
インシデント・レビュー ‐ 今週もAWSの障害が発生
翻訳: 島田 麻里子
この記事は米Catchpoint Systems社のブログ記事 Incident Review: Another Week, Another AWS Outageの翻訳です。
Spelldataは、Catchpointの日本代理店です。
この記事は、Catchpoint Systemsの許可を得て、翻訳しています。
以下は、2021年12月15日に発生したAmazon Web Servicesの障害を分析したものです。
多くの人にとってはホリデーシーズンかもしれませんが、AWSにとってはビル・マーレイ流のGroundhog Dayとなっているようです。
(訳注・Groundhog Day=邦題「恋はデジャ・ブ」1993年に製作されたビル・マーレイ主演のアメリカ映画。同じ一日を何度も繰り返す)
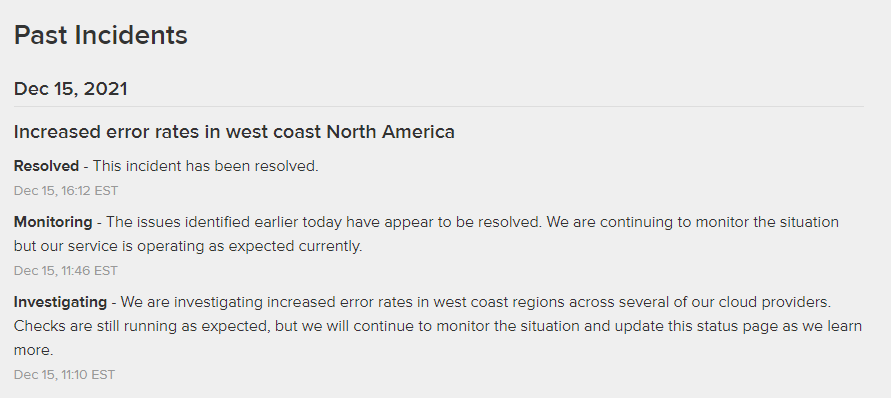
2週連続で、オレゴン州のUS-West-2地域と北カリフォルニア州のUS-West-1地域で障害が発生しました。
今回のAWSの障害は約1時間続き、Auth0、Duo、Okta、DoorDash、Disney、PlayStation Network、Slack、Netflix、Snapchat、Zoomなどの主要なサービスが停止しました。
Catchpoint社では、AWSの発表よりもかなり早い、米国太平洋時間の7時15分頃に障害が発生したことを確認しました。
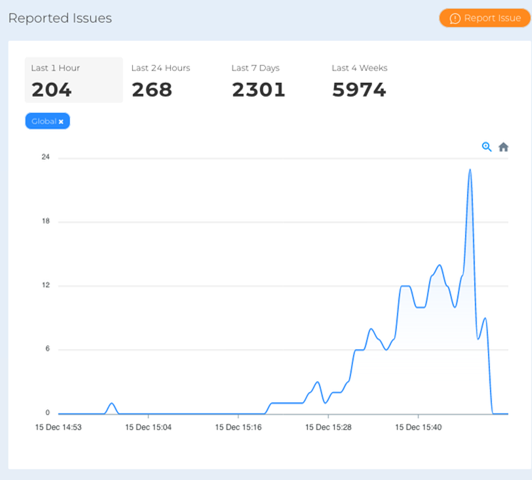
以下のスクリーンショットは、今回の障害を分析したものです。
以下のタイムラインは、米国西海岸地域のインターネット接続に影響を与えたネットワークの遅延とパケットロスの増加を示しています。
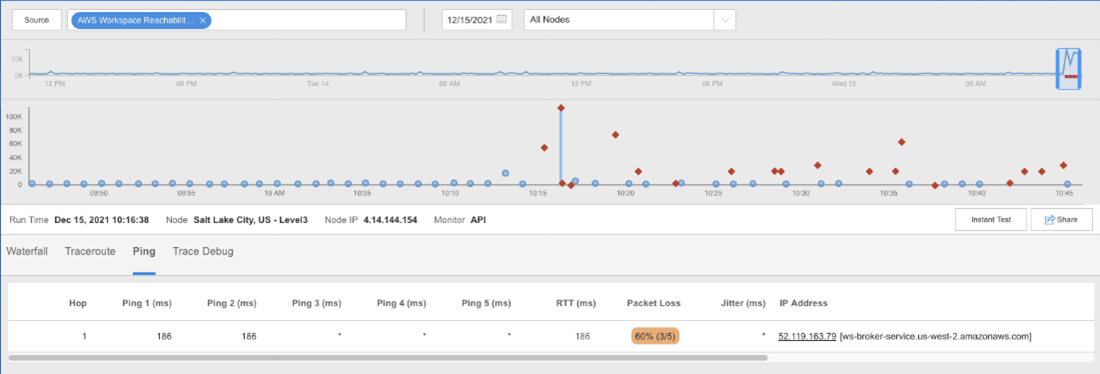
下の図は、複数のインターネット・キャリア上の様々な地域の外部の視点からネットワークを検査したもので、AWSネットワークのエッジにおける追加のレイテンシーとパケットロスを強調しています。
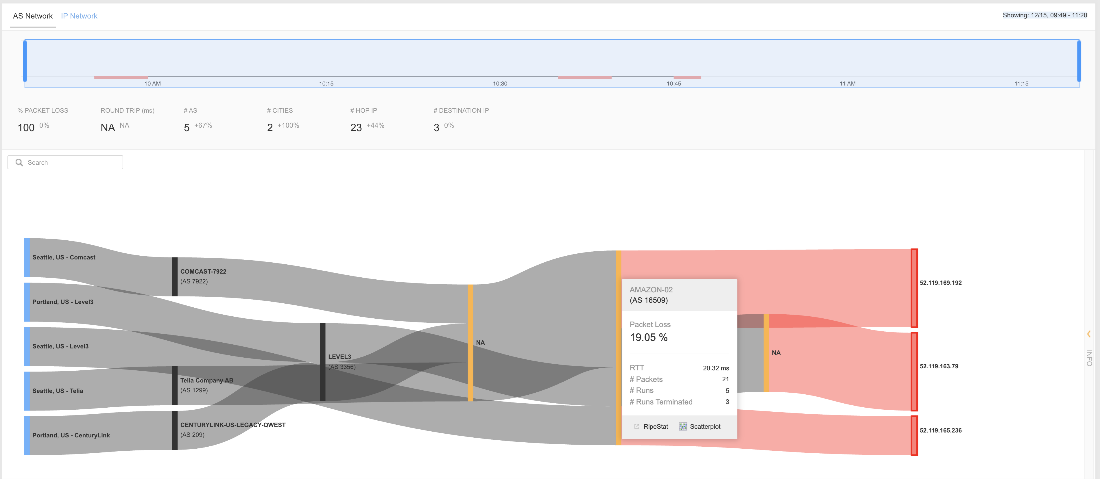
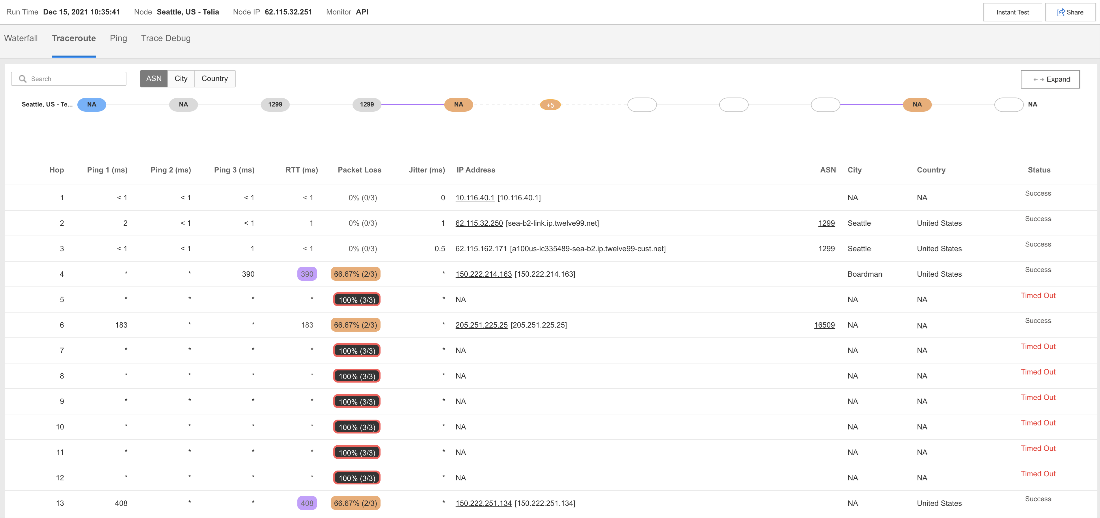
例えば、失敗した測定値の1つを拡大してみると、シアトルのサービスプロバイダTeliaのネットワークパスの記録から、Amazonのネットワーク内でTeliaのネットワークが劣化した後に発生したレイテンシーとパケットロスの増加が明らかとなります。
今回の障害は、先週発生したAWSのバージニア北部(US-East-1)リージョンでの長時間にわたる障害に続くもので、Amazon、Venmo、Disney+、Tinder、複数のオンラインゲームサイトなどの主要サービスはもちろん、倉庫や配送、Amazon Flexの従業員を支援する同社のアプリにも連鎖的な被害をもたらしました。
今回はより短い時間でしたが、Log4jへの不安と加えて、再びソーシャルメディアを騒がせました。
AWS Down and the PagerDuty down. All while the log4j security vulnerability is still at large. 🤕
— Navneet Raju (@navneetraju) December 15, 2021
主要な監視ベンダーから障害に伴うサービスの低下が報告される
AWSの障害は、障害が発生したインフラ上で監視サービスを実行しているいくつかの企業の監視ベンダーに、ダウンストリームの影響を再び与えることになりました。
Datadog社は、AWSの統合メトリクスの収集に遅延があると報告しています。
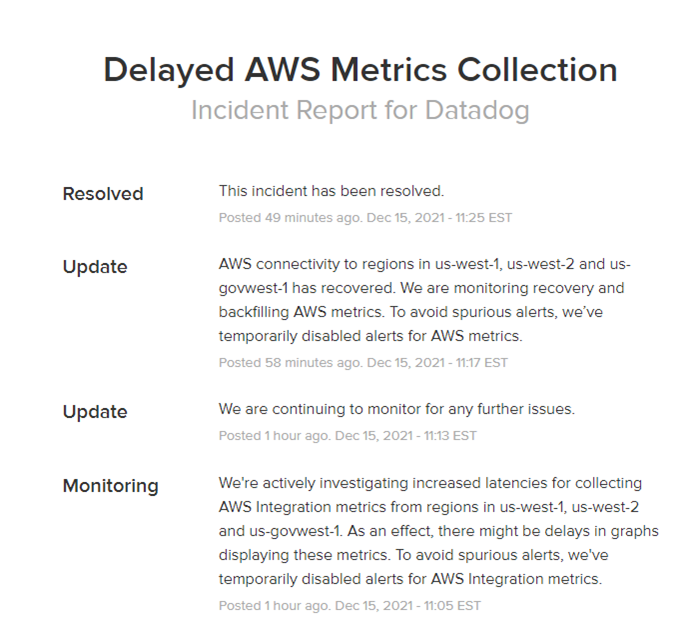
ThousandEyes社では、APIサービスの劣化が報告されています。
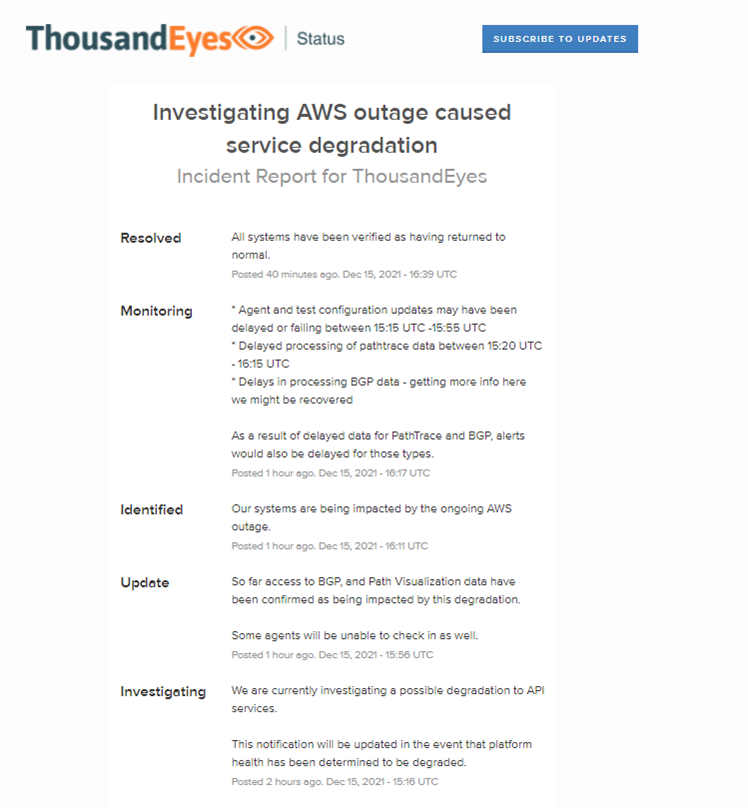
NewRelic社の報告によると、syntheticのユーザインターフェースに影響があったほか、APMのアラートの一部やインフラストラクチャメトリクスのデータ取り込みにも影響があったとのことです。
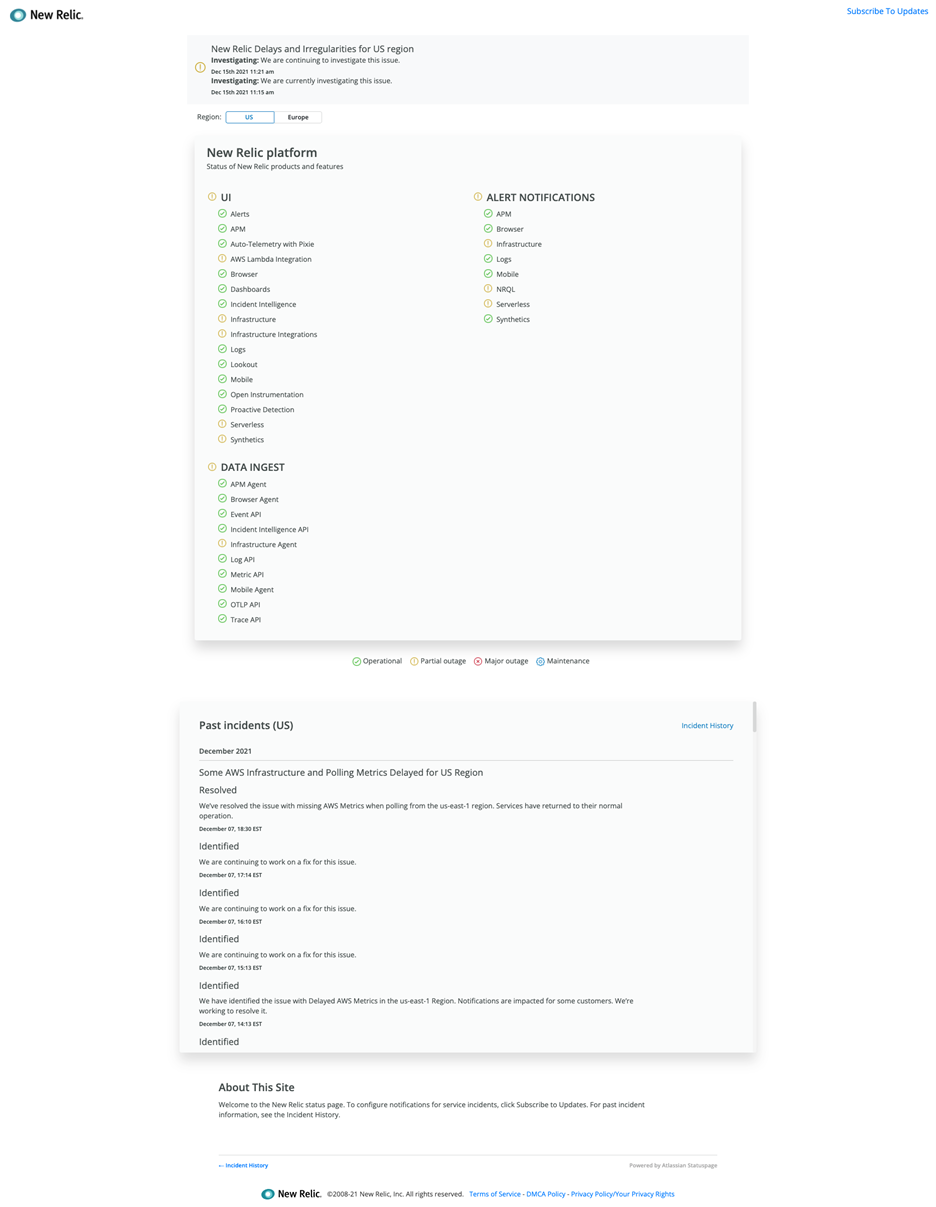
Dynatrace社は、AWSクラスターにホストされている同社のコンポーネントの一部が影響を受けたと報告しています。
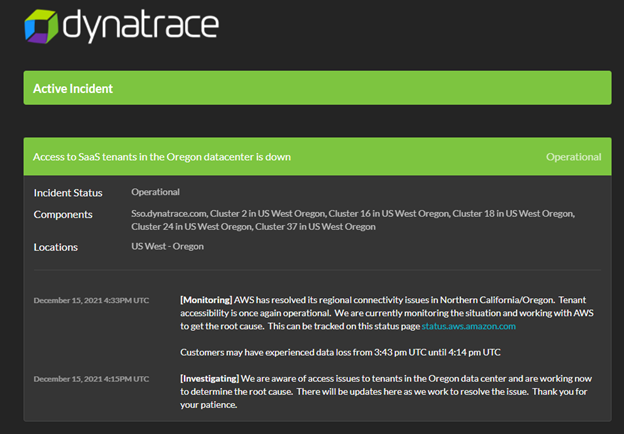
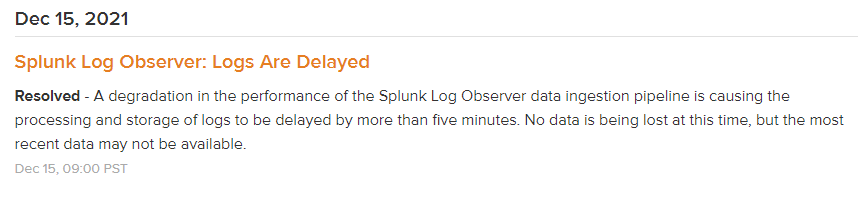
Splunk社(Rigor社およびSignalFX社)は、米国西海岸でのエラー発生率の増加と、同社のログ・オブザーバーのパフォーマンスの低下を報告しました。
仕事を知ることの素晴らしさ
ルーニー・テューンズの古典的なアニメに、サム・シープドッグとラルフ・ウルフが、その日の敵対行為の前に一緒にタイムカードを打つという話があります。
サムがラルフにいつも勝っていたのは、彼が自分の仕事である牧羊犬であることを知っていたからです。
彼は羊ではありません。

というのも、羊の群れを守るためには、自分も羊の群れの一員であってはならないからです。
(しかし、オオカミにとっては成功の秘訣です)
実際、AWSのAdrian Cockroft氏は、2018年にMediumに投稿した記事の中で、この問題を指摘しています。
まずは、監視対象のインフラとは無関係な故障モードを持つ監視システムがあれば便利です
つまり、顧客企業が頼りにしているビジネスクリティカルな監視サービスを、監視対象と同じパブリッククラウドのインフラで実行することはないのです。
そのため、Catchpointはパブリッククラウドの障害の影響を受けません。
クラウドプロバイダのトップ5社のうち、4社がCatchpoint社のオブザーバビリティソリューションを採用している理由は、この説得力のある論理にあります。
実際、ビジネスに不可欠な監視システムが、監視対象となるアプリケーションやプロパティと同じインフラを共有することは、根本的に間違っていると考えています。
パブリッククラウドインフラは、世界のデジタル経済に大きな変革をもたらしてきましたが、今回のような障害が発生すると、ユーザやサービスへの影響が甚大になります。
高可用性アーキテクチャの構築とマルチベンダークラウド戦略の活用は、パブリッククラウドを利用する全てのユーザが優先的に取り組むべきステップです。
最終的に、このような障害の影響を最小限に抑えるための最善の防御策は、問題の早期発見と先を見越した検出を重視した強固なオブザーバビリティ戦略です。
ユーザに影響が及ぶ前に問題を特定することで、迅速なトラブルシューティングが可能となり、収益の損失やブランドへのダメージを防ぐことができます。
もっと詳しく知りたいですか?
障害を予防、準備、対応するためのベスト・プラクティスをもっと知りたいと思いませんか?
こちらをダウンロードしてご覧ください。
2021 Internet Outages: A compendium of the year’s mischiefs and miseries – with a dose of actionable insights