
右シフトするには、オブザーバビリティが必要
翻訳: 島田 麻里子
この記事は米Catchpoint Systems社のブログ記事 To Shift Right, You Need Observabilityの翻訳です。
Spelldataは、Catchpointの日本代理店です。
この記事は、Catchpoint Systemsの許可を得て、翻訳しています。
先日、サファイヤ・ベンチャーズ社のHypergrowth Engineering Summitに参加しました。
(デビッド・カーター氏、サファイヤ社の皆さん、ご招待ありがとうございました!
全体像については、別途ブログ記事を書きました。)
その中で、CircleCI社CTOロブ・ズーバー氏 と、LaunchDarkly社エンジニアリング・プロダクト担当SVPジョナサン・ノレン氏によるによるパネルディスカッションが行われました。
このセッションでは、誰もが左にシフトしているこの世界において、チームはむしろ右にシフトすることを考えるべきだという、示唆に富んだ話がなされました。
※訳注:
Shift to Leftとは、品質保証活動を前倒しにするアプローチで、開発ライフサイクルの早期の段階でテスト活動を実施する事を指します。
Shift to Rightとは、品質保証活動をリリース後も継続的に続けているアプローチを指します。
左にシフトするか、右にシフトするか
まず、左や右にシフトするというのはどういうことでしょうか。
そう、左にシフトするという動きは、私たちが何年も前から知っていた、「問題を早く見つければ、その解決にかかる費用は少なくなる」ということから生まれたものです。
このアイデアは、開発者に広範なテストを行うよう奨励し、複数のレベルの本番前環境で機能を検証し、運用前に可能な限り全ての問題を捕捉することです。
そのときロブは、当たり前のことを言ったのですが、それに私は衝撃を受けました。
それは、 本番にリリースする前にどれだけテストを行ったとしても、常に生きたバグが存在することになるということです。
だから、正常化するのだと。
開発現場でバグを素早く発見し、解決することに慣れさせる。
つまり、右にシフトするのです。
これは、カオスエンジニアリングの考え方に似ています。
「わざと」問題を引き起こすことで、チームが午前3時ではなく午後3時に問題解決に取り組めるようにするのです。
さて、あなたのチームが左にシフトすべきか、右にシフトすべきかは説きません。
実際には、エンジニアリングの世界と同様、人それぞれです。
できるだけ早く見つけるべきものもあれば、低環境では見つけにくいもの、テストデータに大きな投資が必要なものなど、様々です。
しかし、実稼働環境において、クライアントの混乱を最小限に抑えながら、非常に迅速に発見・修正できるものもあります。
これは、適切なリリース計画、機能フラグ、クライアントの期待値の設定と相まって、本番環境へのバグのリリースが危機的状況に陥ることはないことを示しています。
それからディスカッションでは、いくつかの理由で私にとって身近なことを話題にしました。
右シフトを成功させるためには、オブザーバビリティが必要です。
つまり、意図的にバグを本番環境に入れるのであれば、そのバグを迅速に修正するための適切なツールをチームに用意する必要があるのです。そこで、もう一度、仮定してみます。
意図的に右シフトしようとしているのか、それとも誤ってバグを展開してしまったのか、まず本当に問題があることを検知し、次に問題の場所を正確に特定するために、チームが必要とする全てのデータを手元に置いておきたいとは思いませんか?オブザーバビリティは、まさにそれを実現するものです。
本番でトラブルシューティングを成功させるためには
もうひとつ、私にとって非常に重要なのは、開発現場でのトラブルシューティングの役割が、いま非常に混乱しているからです。
オペレーションチームは開発システムを「所有」していますが、開発上の問題を解決するための微妙な情報は持っていません。
ベストなケースは、問題が以前に起こったものであったり、手順書に存在するもので、オペレーションチームが自分たちで解決できるものであることです。
最悪の場合、そして最悪の機能を持つチームでは、運用チームがオンコールのエンジニアに連絡し、「つまらないことで」起こされたことに文句を言い、問題を修正し、そもそも自分たちが起こされたことにイライラして眠りにつくのです。
ハニカム社のCTOであるチャリティ・メイジャーズ氏は、同じサミットで、この問題のために、エンジニアが実際にオンコールローテーションを所有すべきであると話しています。
何しろ彼らは、本番環境で動いているソフトウェアの専門家なのですから。
これには原則的に同意しますが、とはいえなかなかそうもいきません。
ソフトウェアのレイヤーやコンポーネントが多すぎるため、多くの人がオンコールで対応することが不可能な場合があります。
さらに、エンジニアが本番データを実際に見ることができず、少なくとも他のチームからの厳しい監視なしにはできない場合もあります(金融や医療業界を想像してみてください)。
しかし、せっかくの機会なのに、特定のアプリケーションの専門家が周りにいないこともあります。
そして重要なシステムでは、その専門家をいち早く探し出さなければならないのです。
私の解決策は、ご想像のとおり、「オブザーバビリティ」です。
しかし、それ以上に重要なことがあります。
エンジニアリングからオペレーション、または本番環境でアプリケーションを所有するチームからの標準的なハンドオフを通じて、誰もがシステムをデバッグできるようにすることです。
このハンドオフには、実装されるコンポーネントの機能から、入出力、既知のエラー処理、依存関係、要件など、あらゆるものが含まれる必要があります。
これら全てから、アプリケーションのための慎重なオブザーバビリティ計画を考え出すことができます。
そしてそれができれば、アプリケーションの複雑なビジネスロジックを知らなくても、多くの種類の問題をトラブルシューティングできるようになるのです。
オブザーバビリティ計画によるトラブルシューティングの効率化
典型的な3層アプリケーションとキャッシュレイヤーの例を見てみましょう。
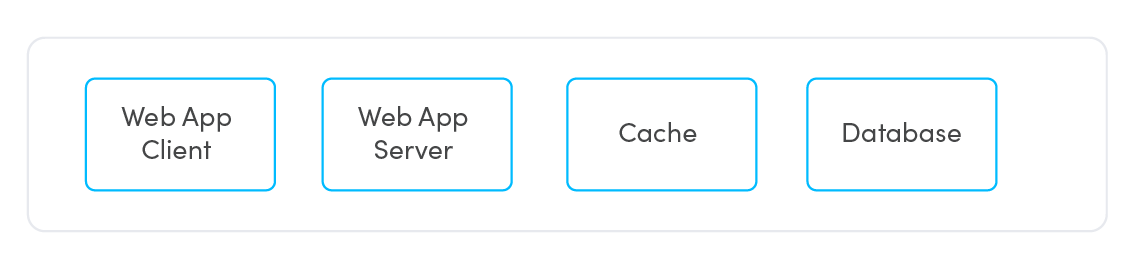
引き継ぎ情報はこちら。
- Web App ClientはWeb App Serverと対話する。
- Web App ServerはWeb App ClientとCacheと対話する。
ただしCacheと対話できない場合は、直接Databaseにアクセスする。 - CacheはWeb App ServerおよびDatabaseと通信する。
もちろん、もっと色々な話があります。
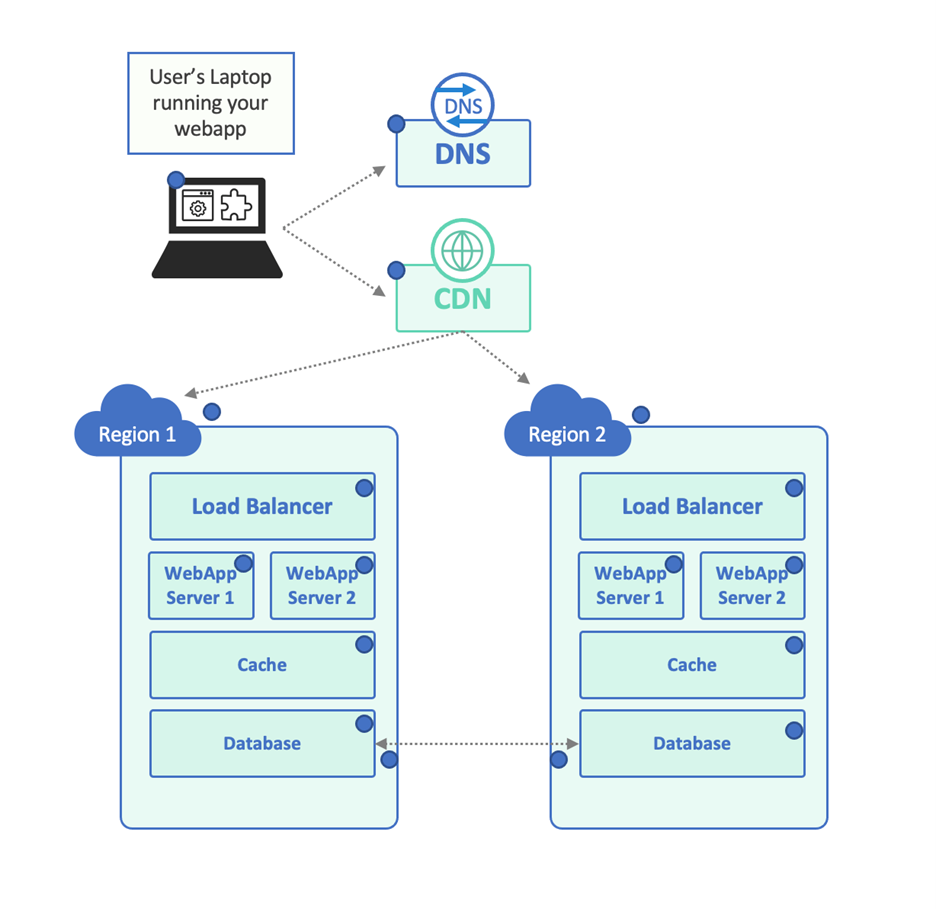
例えば、実際のインフラはこんな感じでしょうか。
余談ですが、あなたのエンジニアリングチームは、この機能モデルとインフラデータフローモデルの違いを知らない可能性があります。
このような環境にデプロイされた場合、彼らのアプリケーションは全く動作しないかもしれません。
したがって、インフラの計画とレビューがSDLC(Systems Development Life Cycle:ソフトウェア開発ライフサイクル)の一部であることを最初に確認してください。
インフラの図を見てみると、引き継ぎを成功させるためには、まだまだ必要なことがたくさんあります。
- DNSプロバイダ、CDN、Load balancerにクライアントが依存する。
- CDNとLoad balancerの両方が、正しいWeb App Serverにセッションを永続化する必要がある。
- Cacheはローカルだが、Databaseは一貫性を保つ必要があるため、クラウドのリージョン間でレプリケートされるとする。
例: 動作中のオブザーバビリティ戦略
この単純な例はすでに複雑になっていますが、私たちのアプリケーションのためのオブザーバビリティ戦略を考えてみましょう。
上記の例では、全ての監視ポイントを表すために青い点を追加しています。
クライアント環境の動作を確認する
クライアントのラップトップPCでクライアントアプリケーションが実行できるか、DNSサーバに到達できるかなど、クライアントの環境が正常に動作しているかどうかを確認したい場合があります。
エンドポイント・オブザーバビリティ、あるいはリアル・ユーザ・モニタリング(RUM)のソリューションが、その助けとなるでしょう。
サードパーティの動作を確認する
サードパーティのサービスが要求通りに機能していることを確認するため、恐らくはDNSの検証テストと地域別のCDNの一連のテストで、異なるクラウド地域間で適切にバランスが取られていることを確認することになるでしょう。
これらの同じテストは、クラウド領域自体が動作していることを確認するために使うことができます。
あるいは、それぞれの領域に対して専用のテストを追加して確認することもできます。
サーバサイド、キャッシュの動作を確認する
サーバサイドの各コンポーネントについて、入力と出力を観察する必要があります。
ロードバランサーに接続し、サーバ間の負荷を分散していることを確認することができます。
200 OKを返すか、あるいはサンプルの問い合わせ結果を返すようにすればいいのです。
個々のWebサーバも、キャッシュについても同様です。
キャッシュが稼働していることはもちろん、キャッシュ機能が正しく動作していることも確認できます。
おそらく、データを2回問い合わせ、応答ヘッダーを見て、それがキャッシュから来たものであることを確認します。
データベースを直接テストする場合も同じです(レスポンスヘッダーにはキャッシュから来たと書いてはいけません)。
アプリケーションの動作を確認する
ここでは必要なだけ複雑にすることができます―恐らくアプリケーションは、特定のAPIコールが発行されたときにメトリクスを返すことができます。
多分、このアプリケーションがカスタムメトリクスを返すようにしたいのです―特定の重要な領域をどのくらいで通過するのかを。
リクエストが特別な「マジック」ヘッダを送信する場合、各リクエストに対して行うことができますし、API経由でサマリーメトリクスを返すことも可能です。
監視の追加を検討する
ネットワークインフラがこれより複雑な場合は、レイヤー3~4(ルーティング、パケットレベル)の監視を追加したほうがいいかもしれません。
クロスリージョンテストを設定する
最後に、データを同期させるためにデータベース同士が通信する必要があることがわかっているので、ネットワーク層とアプリケーション層の両方でクロスリージョンテストを設定し、両者間の接続性と高いスループットを確認することができます。
より良い(オブザーバビリティ)解決は、より速い(障害)解決に繋がる!
上記の図を見てみると、青い点(監視ポイント)がたくさんありますね。
そこが重要なんです。
アプリケーションを完全にオブザーブできるようにするには、できるだけ多くのデータを持つ必要があります。
どれかを外すと、今度はどこに問題があるのかよくわからなくなります。
ここで、上記と同じ画像を低解像度で表示させてみると、その意味がよくわかります。
何が起こっているのかわからない!
アプリケーション本体だけを監視していると、そういうことになります。
上がっているか下がっているかはわかるかもしれませんが、細かいところは見えません。

さらに解像度を上げるために監視点を追加していくこともできますが、この比較的シンプルな戦略でも、どのようなことが実現できたかを見てみましょう。
- これらのテストを「通常時」に行うことで、ベースラインを確認することができました。
各コンポーネントの所要時間やエラー率などがわかったので、そのベースラインに対してSLO(Service Level Objective: サービスレベル目標)を作成し、パフォーマンスが低下した場合には、何が問題だったのかを正確に把握できるようになりました。 - 万が一、問題が発生しても、クライアントと個々のインフラコンポーネントの視点から、360度完全に把握することができます。
- 特定のコンポーネントに問題がある場合、すぐに特定することができます。
このように適切な引き継ぎを行うことで、突然のインシデントコールが少なくなり、短時間で解決することができるのです。
そして、もし、エンジニアリング・チームに報告する必要がある場合でも、問題はすでに絞り込まれているので、迅速に解決することができます
右にシフトするなら、この方法で。
そうでなくても生産性の問題が発生するのですから、きちんとした技術的な引き継ぎをすることです。
そうすることで、関係者全員がより幸せになれるはずです。