
早期発見とインターネット・レジリエンスの関連性:Salesforceの障害から学ぶこと
翻訳: 島田 麻里子
この記事は米Catchpoint Systems社のブログ記事「The Link Between Early Detection and Internet Resilience: A Lesson from Salesforce’s Outage
」の翻訳です。
Spelldataは、Catchpointの日本代理店です。
この記事は、Catchpoint Systemsの許可を得て、翻訳しています。
障害にかかる1時間あたりのコストを調査したほとんどすべての研究は、必ず「障害にはコストがかかる」という明確かつ否定できない結論を導いています。
2016年の調査によると、ダウンタイムの平均コストは1分あたり約9,000ドルと見積もられています。
さらに最近の調査では、回答者の61%が障害によるコストは少なくとも10万ドル、32%が少なくとも50万ドル、21%がダウンタイム1時間あたり少なくとも100万ドルと回答しています。
障害によって毎分何万ドルもの損害が発生する場合、できるだけ早期に発見することが重要となります。
顧客関係管理(CRM)ソフトウェアのリーディング・カンパニーであり、中小企業からFortune500社まで、15万社以上の顧客にサービスを提供し、何兆ものプラットフォーム、消費者、従業員とのやり取りを促進している企業であれば、なおさら重要です。
Salesforceの高額なサービス中断
2023年9月20日10時51分(米国東部時間)、Salesforceのテクノロジーチームは、様々な重要なサービスに影響を及ぼすインシデントを検出しました。
これらのサービスは、Commerce Cloud、MuleSoft、Tableau、Salesforce Services、Marketing Cloud Account Engagement、Marketing Cloud Intelligence、Omni Channel、ClickSoftware、Trailblazer(コミュニティ、認証、プロファイル)、Data Cloudなど、複数のクラウドに及んでいます。
このインシデントは4時間以上続き、その間、Salesforceの巨大な顧客基盤の一部で障害が発生し、Salesforceにログインできなくなったり、影響を受けたサービスにアクセスできなくなったりしました。
Salesforceによると、障害はセキュリティ強化を目的としたポリシーの変更が原因だといいます。
しかし、この変更によって、必要なリソースへのアクセスが不用意に遮断され、サービス間の通信途絶やシステム障害が発生することになったのです。
驚くべきことに、サービス間通信への影響は検証テストでは検出されませんでした。
嘆かわしいのは、この一件がもっと短時間で済み、Salesforceの顧客への影響も少なくて済んだかもしれないということです。
カギとなるのは―早期発見です。
Catchpointは、Salesforceが公式にこのインシデントを認識するほぼ1時間半前に、この問題を検出しました。
その方法は以下の通りです。
Salesforceの複数のクラウドで障害を検出
米国東部標準時間の9時15分、Salesforceが問題を認識する約1時間半前に、Catchpointのプローブが問題の初期兆候を特定し、障害の発生を知らせました。

Catchpointを使用してCommerce Cloud(Demandware)上のSalesforceサービスを監視している顧客は、50倍ものサーバエラーを検出し、即座にアラートを受け取りました。
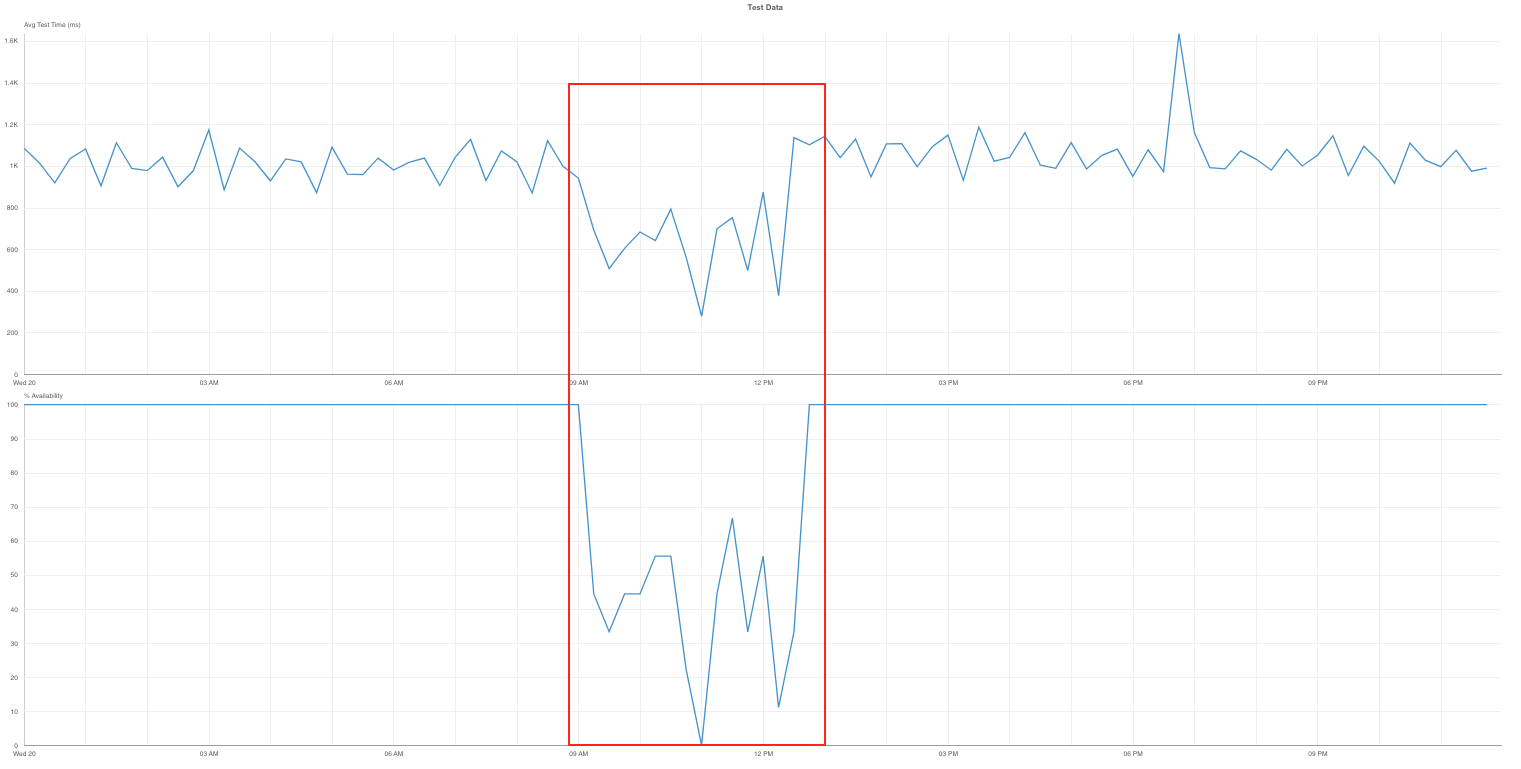
パーミッションの変更によって可用性が低下し、サービスが中断されたことに注目してください。
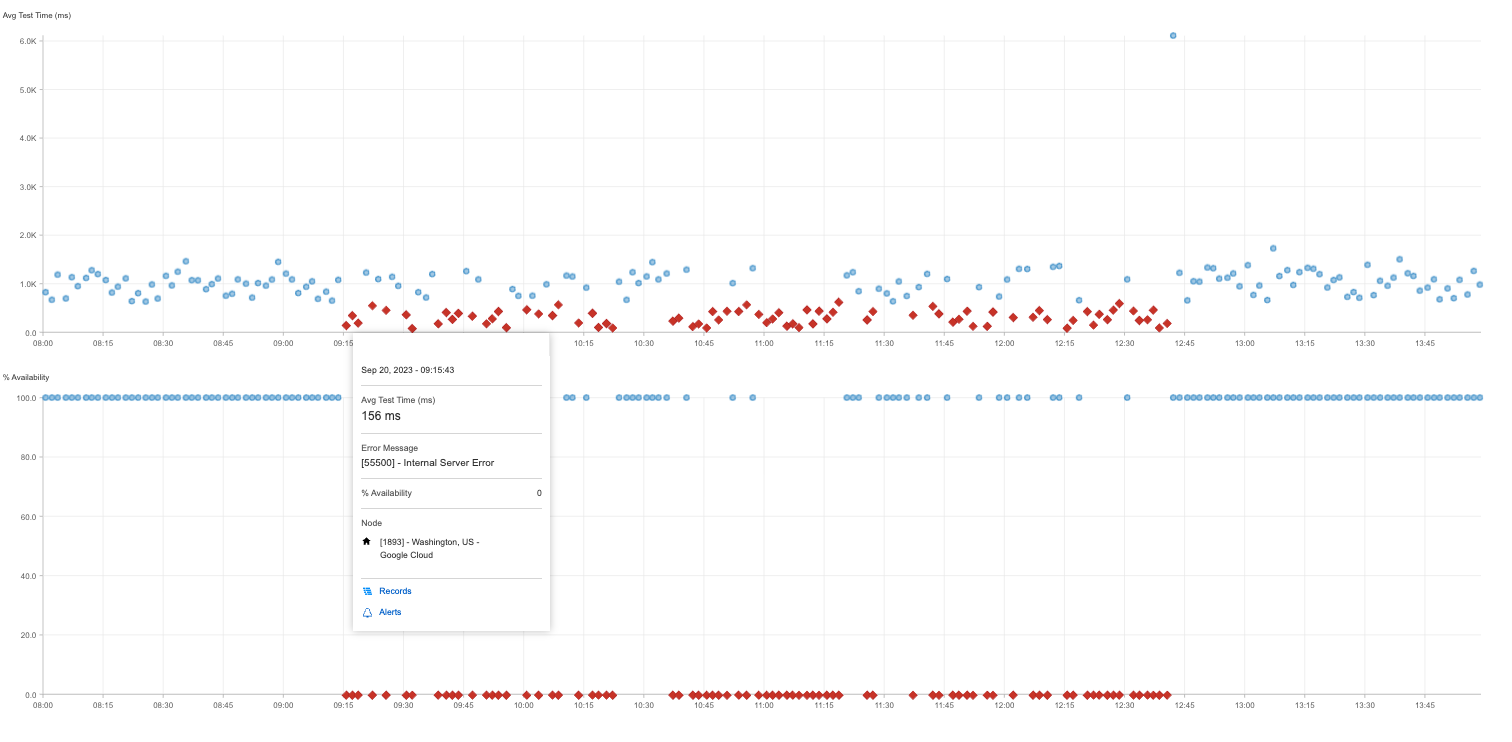
Salesforceがこれらの個別のエラーを検出したのは、米国東部標準時間10時42分のことでした。
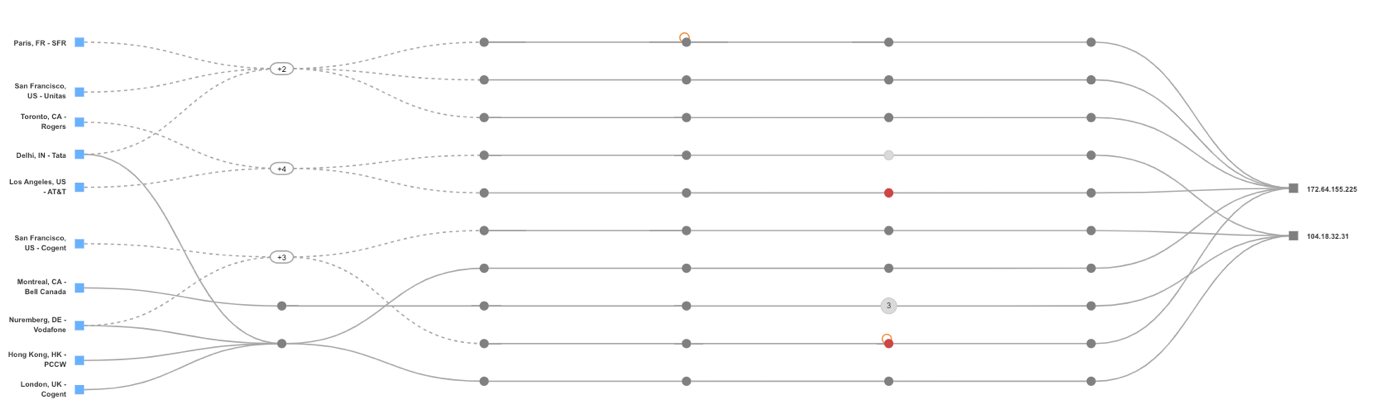
状況が展開するにつれ、Catchpointのインターネット・パフォーマンス・モニタリング(IPM)プラットフォームは、インターネット・スタックのどのレイヤーが影響を受けたかを正確に特定することができました。
50倍の内部サーバ・エラーが表示されるようになったページもあれば、検索機能が部分的に停止したページもありました。
webテストに加え、Catchpointはネットワーク・テストも実施しました。
障害発生中、これらのテストでは宛先へのpingやtracerouteが正常に実行され、問題がネットワーク・レイヤーに起因するものではないことが確認されました。
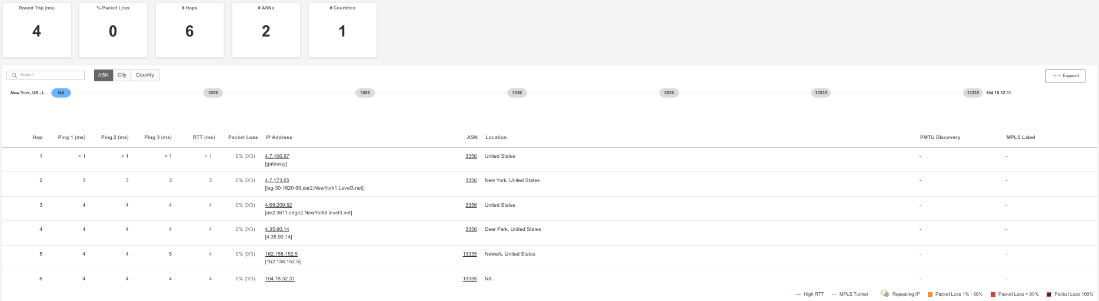
図1は、トランジットISPからエンドポイントへの到達可能性を示すASN(Autonomous System View)であるのに対し、図2は同様のビューをIP(ホップ・バイ・ホップ)の視点から示しています。

Salesforceのテクノロジーチームは、米国東部標準時間11時5分に影響を受けたサービスチームに連絡し、11時33分までにロールバックを開始しました。
Salesforceがクラウドシステムが再び完全に稼働することを宣言したのは、最初の検知から約4時間後のことでした。
コストの計算
Salesforceは、シームレスなプラットフォーム・インタラクション、顧客エンゲージメント、データ管理など、ビジネス・プロセスの生命線ともいえる重要な機能を提供しており、全世界で15万社にのぼる顧客基盤が同社に大きく依存しています。
Salesforceだけでなく、サービスを利用できなかった顧客一人ひとりにまで影響が及ぶ障害が発生した場合の影響を少し考えてみましょう。
収益の損失だけでも天文学的な数字になるかもしれません。
障害発生中、重要な顧客データにアクセスできずにマーケティング・キャンペーンを展開できず、顧客との関係を管理できなかった小規模な新興企業から多国籍企業まで、無数の企業について考えてみましょう。
トランザクションの中断、販売機会の損失、顧客とのやり取りの遅延を想像してみてください。
Salesforceが「サブセット」と呼んでいる顧客全体にこの影響が及んだ場合、一見何の問題もないように見えるサービス中断の重大さを理解することができるでしょう。
インターネット・レジリエンスにおける早期発見の重要な役割
ビジネスがクラウドベースのサービスに大きく依存している今日の相互接続された世界では、インターネット・レジリエンスはもはやオプションではなく、基本的に必要なものです。
問題を早期かつプロアクティブに検出し、根本原因を迅速に特定する能力により、障害が発生した時点でその状況を把握し、トラブルシューティングを行うことができます。
しかし、早期発見は言うほど簡単ではありません。
多くのサイトでは、基本的なアップタイム監視に頼っているため、スローダウンや障害の検出がホームページの監視だけに限られていることもあり、断続的または部分的なサイト障害を経験している企業が検出を逃してしまう可能性があります。
では、プロアクティブな早期発見のための重要な要素とは何でしょうか?
考慮すべき重要な要素が少なくとも2つあります。
その1 高いエラー閾値を再考する
最も重要な点は、高いエラー閾値によって引き起こされる遅延に対処することです。
ログやトレースに依存して問題を検出するシステムの多くは、特にトラフィック量が多い状況で、主に誤検出を避けるためにエラーの閾値を高く設定しています。
APM側に設定された高い閾値は、パーミッションの変更によるエラーの増加など、変更後の問題の検出を遅らせる可能性があります。

Catchpoint IPMと従来のAPMを比較したグラフをご覧ください。
Catchpointは、標準的なAPMソリューションよりもはるかに速く問題を検出、診断、解決することに優れていることに注目してください。
実際、Catchpoint IPMは、APMシステムが単に問題を検出するのと同じ頃に問題を解決することがよくあります。
これは、グラフのグレーの部分で示されているように、大幅なコスト削減につながります。
その2 リアルタイムのデータ分析が不可欠
有名な観測ソリューションの中には、テレメトリ・ソースからのデータを15分間隔で提供するものもあります。
例えば、15分前のBGPデータでは、1分1秒を争うときにコストがかかります!
データが15分前のものであるだけでなく、変更が影響したかどうかを確認するためには、さらに15分待たなければならないことに注意してください。
Catchpoint IPMは、独立系からのリアルタイムのデータを活用するため、トラブルシューティングの遅れを防ぐことができます。
Catchpoint IPMがあれば、Salesforceのサービス中断のようなインシデントは、もっと迅速に解決できたはずです。
Catchpointはどのようにサポートできるか
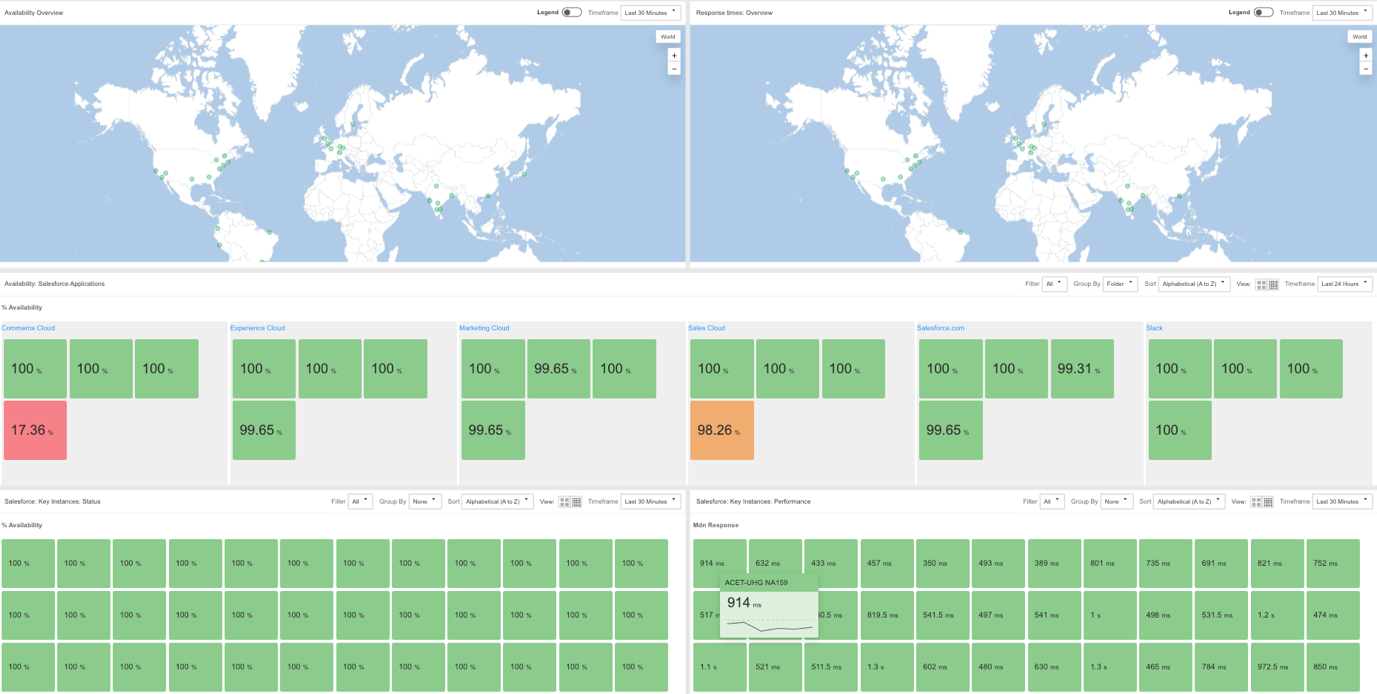
Salesforceの障害は、業務に支障をきたす前に問題を事前に特定し、解決するための継続的な監視の重要性を改めて認識させるものでした。
Catchpoint IPMは、上記のすべての機能により、障害のコストを軽減することができます。
世界最大のグローバルなオブザーバビリティ・ネットワークの管理者として、Catchpointのプラットフォームはトラブルシューティングを迅速かつ容易にします。