
IPMを極める:SLA監視で収益を守る
翻訳: 島田 麻里子
この記事は米Catchpoint Systems社のブログ記事「Mastering IPM: Protecting Revenue through SLA Monitoring」の翻訳です。
Spelldataは、Catchpointの日本代理店です。
この記事は、Catchpoint Systemsの許可を得て、翻訳しています。
もしあなたがSREであるならば、SLIは言うまでもなく、SLOもSLAも既にご存知でしょう。
しかし、これらの略語に精通していなくても、IPMベストプラクティスシリーズのこの回を読めば、これらの概念がいかに広範に適用可能であるかがすぐにわかります。
これらのコンセプトについて詳しく説明し、合成監視(Synthetic Monitoring)によってサービスレベル目標(SLO)の追跡を強化し、ユーザ体験の向上と十分な情報に基づいた意思決定につなげる方法を探ります。
はじめに、SLAとSLOを区別しましょう。
SLOとは何か?
SLO(サービスレベル目標)は、ベンダーが満たすべき具体的なパフォーマンス目標です。
これは、期待されるサービス品質レベルの概要を示す、明確で測定可能な目標です。
例えば、SLOはWebアプリケーションが99%の稼働時間を維持するよう指定することができます。
これは、1か月または1年など、指定された期間内に少なくとも99%の時間、アクセスおよび運用が可能であることを意味します。
SLAとは何か?
SLA(サービス・レベル・アグリーメント)とは、ベンダーと顧客との間で交わされる契約で、ベンダーが顧客に提供しなければならないパフォーマンスのレベルと、パフォーマンスが定義されたしきい値を満たさない場合の結果(通常は金銭的なもの)を定義するものです。
SLAは多くの場合、個々のSLO(サービス・レベル目標)の集合体で構成され、保証される範囲を正確に定めます。
例えば、クラウド・プロバイダと顧客との間のSLAでは、仮想サーバーの99.9%の可用性を保証することができます。
このレベルの可用性が維持されない場合、SLAでは返金またはサービスクレジットを指定することができます。
SLIとは何か?
SLI(サービスレベル指標)は、SLOに違反したかどうかを判断するために使用される正確な指標と閾値を示します。
例えば、SLIは「テスト失敗率」が 1週間中に1%を超えてはならないと定義することができます。
この場合、SLIは特定のテストの不合格率を追跡調査し、1週間の期間内に許容できる最大不合格率として1%の閾値を設定します。
エラー・バジェットとは何か?
エラー・バジェット(Error Budget)とは、システムの性能測定基準におけるエラーや逸脱に対してあらかじめ設定された許容範囲のことで、通常はSLOで指定されます。
これは、定義された時間枠内で許容可能な問題または障害のマージンを表します。
エラーが累積してバジェットを超えると、合意されたサービス品質が破られたことになります。

なぜSLOが重要なのか?
SLOが重要である主な理由は以下の通りです。
- ユーザ体験の向上
- SLOは通常、エンドユーザ体験と密接に結びついています。
SLOを追跡することで、組織はサービスが常にユーザの期待に応え、あるいはそれを上回るようにすることができます。
これは、最終的にポジティブなユーザ体験に繋がります。 - 信頼性アセスメント
- SLOは、使用されているアプリケーションまたはサービスの信頼性を追跡するのに役立ちます。
SLOが満たされていない場合、これはアプリケーションが複数のサービス中断とパフォーマンス低下に直面したことを示しています。 - SLAコンプライアンス
- SLOは、組織と顧客、または同じ組織内の異なるチーム間の SLAの一部です。
SLOを監視することで、これらの合意事項の遵守が保証され、説明責任と信頼が促進されます。
SLOが守られなかった場合、組織はSLAに従って金銭的なペナルティを請求することができます。 - データに基づく意思決定
- 組織はSLO指標を利用して、戦略的決定を下し、リソースを効果的に配分し、改善の優先順位をつけることができます。
過去のSLOデータの助けを借りて、組織は信頼できる一貫した製品とサービスを選択することが可能です。
SLOはどのように機能するのか?
SLOの目標は、一貫してユーザの期待に応え、あるいはそれを上回る、信頼性が高く、レジリエンスが高い、応答性の高いサービスを確実に提供することです。
これらの目標は、多くの場合、100%に近いが100%ではないパーセンテージで表されます。
例えば、99%または99.99%の可用性を目標とすることができます。
100%を目指す完璧さは、現実の世界では不可能です。
たとえあなたの責任でなくても、いつかは何かが故障します。
絶対的な信頼性を追求することは、金銭的なコストがかかるだけでなく、人材やエンジニアの期待という点でも非現実的です。
逆に、信頼性が低すぎることもまた、代償を伴います。
頻繁なサービス中断を経験すれば、ユーザはいずれ、より信頼できる競合他社に移ってしまうでしょう。
では、そのバランスは?
行きつけのレストランで料理を注文したとき、うまくいかなかったとします。
厨房が遅れたり、ウェイターが注文を間違えたり。
それは些細な不都合であり、簡単に修正できます。
そのようなミスが5%程度の頻度である限り、あなたはそのレストランを支持し続けるでしょう。
これがSLOとサイトの信頼性エンジニアリングの本質です。
SLOとは、時折起こる不都合を受け入れつつ、ほとんどの時間期待に応えることです。
SLOはこのバランスを取るのに役立ち、ユーザの幸福とビジネスの成功を保証します。
合成監視(Synthetic Monitoring)はSLO追跡にどのように役立つのか?
合成監視(Synthetic Monitoring)は、サービス実績と信頼性について公平かつ包括的な見解を提供することで、SLO追跡を強化する上で重要な役割を果たします。
顧客や利害関係者は、外部評価を公平で透明なものと考え、信頼を置くことが多いです。
この信頼は、サービス提供者の主張に対する信頼性の向上に寄与します。
最終的に、合成監視(Synthetic Monitoring)はポジティブなユーザ体験、信頼性、SLAコンプライアンス、十分な情報に基づく意思決定を保証し、サービス品質を維持するための貴重なツールとなります。
SLOのベストプラクティス
SLOを設定するためのベストプラクティスをいくつか紹介しましょう。
- SLOのために監視したいサービスをリストアップすることから始めます。
例えば、DNSプロバイダ、CDNベンダー、Webサイトのサードパーティタグ、クラウドプロバイダなどです。 - 追跡が必要なメトリクスを決定します。
可用性(Availability)とテスト時間(Test time)をお勧めします。 - 特定のサービスに対するテストを設定します。
例えば、Adobe Tag ManagerのSLOをトラッキングしたい場合、ページ上のタグマネージャJSに対してテストを作成します。 - 選択したメトリクスの目標と目的を決定し、これらのメトリクスの違反条件を設定します。
- ダッシュボード/コンソールを使って、その期間に使われたバジェットと残りのバジェットを追跡できるようにします。
すでに社内チームやベンダーからSLAに定義済みのSLOがある場合は、それらの文書に明記されているSLOを参考にして設定することができます。
しかし、ゼロから始める場合は、効果的に始めるために以下のベストプラクティスを検討してください。
Catchpointの統合ダッシュボードによるSLO監視の合理化
SLOダッシュボードは、すべてのサービスのSLOを追跡する単一のビューを提供する必要があります。
CatchpointのSLOダッシュボードは効率的な監視を提供し、サービスパフォーマンスの統一されたビューを提供することで、上記のベストプラクティスの実施を簡素化します。
以下は、CatchpointのSLOダッシュボードとその構成要素のスナップショットです。
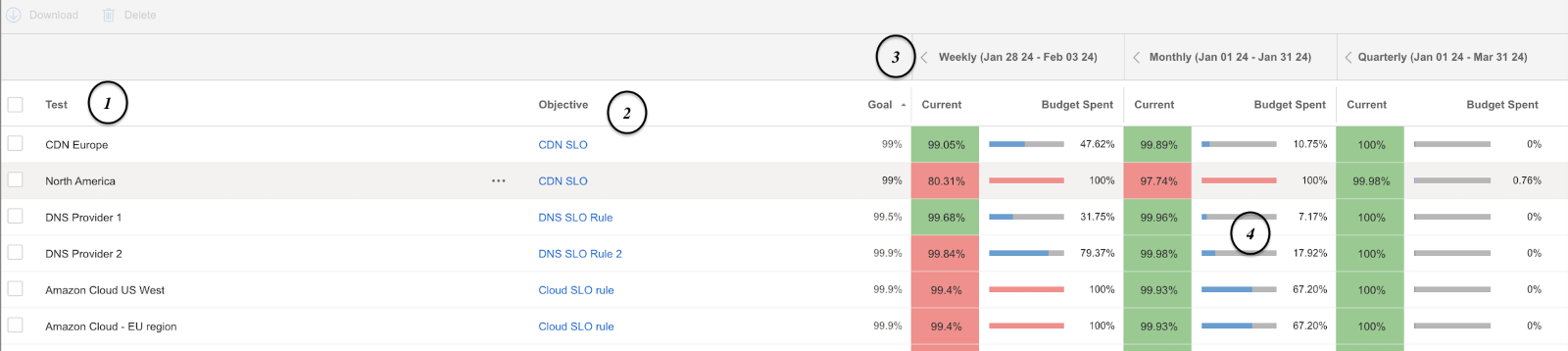
- Test
- 各サービスで作成されたテストはここにリストされています。
- Objective
- 設定され、テストにマップされたSLOルールの名前。
- Time Range
- このセクションでは、さまざまな時間範囲のSLOデータを提供します。
- Budget
- このセクションでは、どれだけのバジェットが使われ、残りのバジェットはどれくらいかを説明します。
- お客様の環境内外の外部DNSプロバイダを、1分以上の頻度で24時間365日アクティブに監視する
- ユーザがいるすべての主要な地理的位置から観測する
- これらの地域の主要トランジットISPから観測する
- DNS、ネットワーク接続、HTTP、Webトランザクション、電子メール、Websocket、MQTTなど、デジタルサービスの重要なコンポーネントを監視する
- DNS、CDN、クラウド、API、SaaS、Eメールなど、外部ベンダーが管理する重要なサービスを監視する
- 捕捉した情報に基づき、リアルタイムのデータとアラートを提供する
- マルチベンダー戦略で使用されるリアルタイムAPIや他のツールとの統合を活用する
- 中立的な第三者のデータでSLIを監視し、サービス提供を検証する。
- メンテナンススケジュールを実施し、データの妥当性を確保する。
- 効果的なSLA管理のために、データをビジネス目標と整合させる。
- 第三者機関のSLAレポートにより、顧客からのクレームを客観的に処理する。
- 法的準備のための広範かつ長期的なデータを維持する。
上記のダッシュボードでは、使用されているすべてのサービスと、さまざまな時間枠に対応するSLOを一括表示できます。
これにより、デリバリースタックで使用されているサービスのいずれかにSLOバジェット違反があるかどうかを素早く特定することができます。
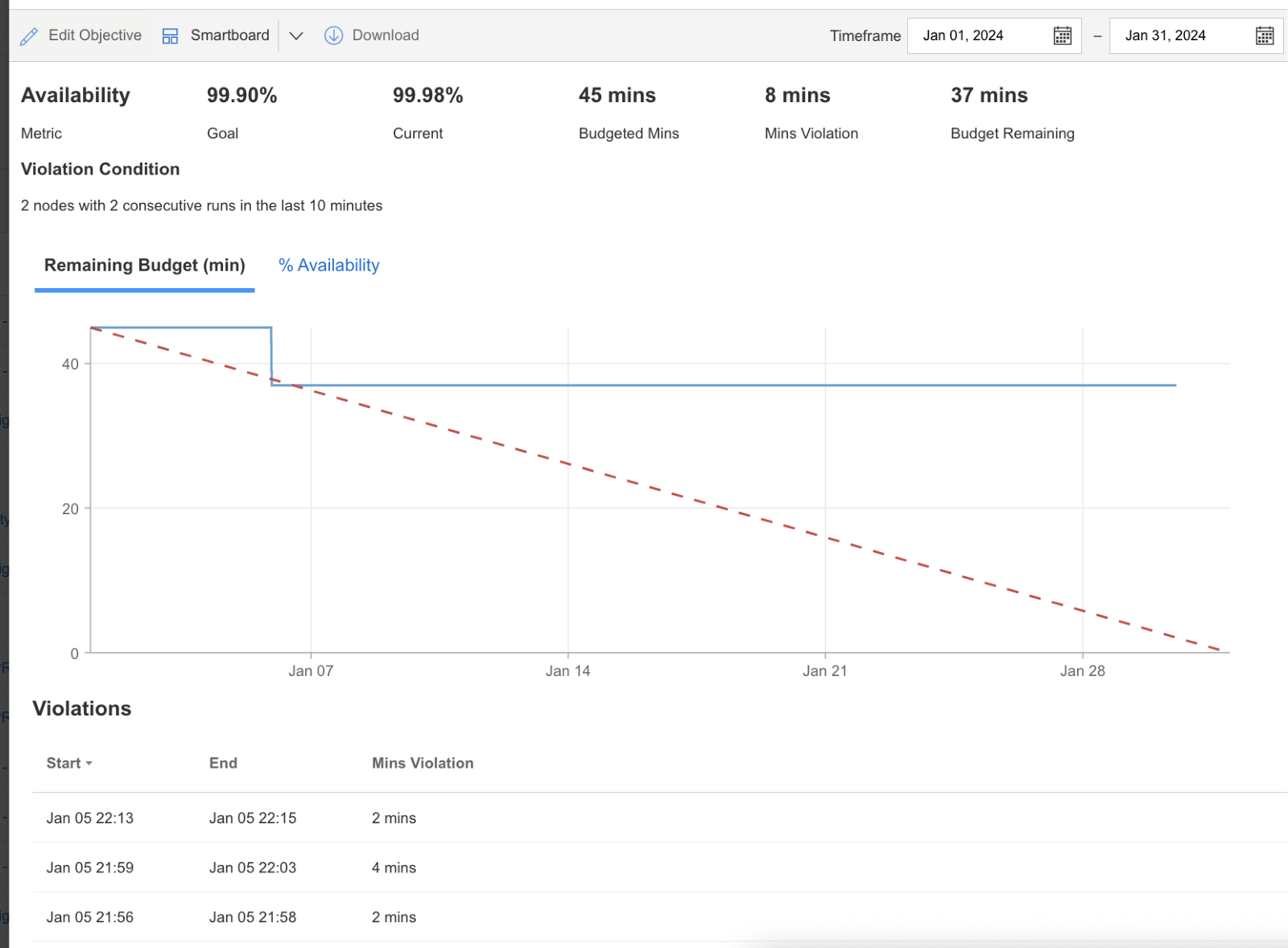
SLO違反が発生した場合、障害または機能低下の理由を理解し、利害関係者と共有できるデータを準備することが重要です。
上記のバーンダウン・チャートから、SLOバジェットの傾向とSLO違反に関する具体的な時間の詳細を見ることができます。
信頼性戦略の必要性
SLA管理は、ベンダーに責任を負わせるためだけのものではありません。
ベンダーの障害とは無関係に、IT組織が信頼できるサービスを確保することでもあります。
SLA戦略を補完する明確なオブザーバビリティ戦略と、ベンダーのサービスと自社のサービスの両方に対するリアルタイムの監視とアラートを含む信頼性戦略が不可欠です。
オブザーバビリティ戦略には、次のような機能が必要です。
CatchpointのIPMプラットフォームはこれらの機能をすべて網羅しており、顧客の期待に自信を持って応え、ベンダーに責任を負わせることができます。
Catchpointを使えば、こんなことが可能です。
IPMベストプラクティス・シリーズの次回は、APIモニタリングについて、APIトランザクションの複雑さを掘り下げ、レジリエンスを向上させる方法を学びます。