
100万ドルの教訓:SLAを通じて品質文化を築く
著者: Mehdi Daoudi
翻訳: 永 香奈子
この記事は米Catchpoint Systems社のブログ記事「The $1 Million Lesson: Building a Culture of Quality Through SLAs」の翻訳です。
Spelldataは、Catchpointの日本代理店です。
この記事は、Catchpoint Systemsの許可を得て、翻訳しています。
DoubleClickの初期の頃、SaaSがまだアプリケーションサービスプロバイダー(ASP)と呼ばれていた時代、私はQoS(サービス品質)チームの立ち上げを任されました。
私たちの主な使命は監視システムを構築することでしたが、すぐにSLA(サービスレベル契約)の管理を任されるようになりました。
ある顧客に対してSLA違反による違約金を100万ドル以上支払った後、この業務は非常に重要なものとなったのです。
理由はというと、誰かが100%の稼働時間を約束するという不可能な契約に署名してしまったからです。
これは、私たちがどのようにしてSLAを管理し直し、金銭的損失を止め、サービス指標を中心とした品質文化を構築していったかの物語です。
あなたが現在SLAを管理している場合でも、単にそれに興味があるだけでも、この投稿は私たちが直面した課題、実施した解決策、そして学んだ教訓について貴重な洞察を提供することでしょう。
SLAとは?

SLA(Service Level Agreement:サービスレベル合意)とは、ベンダーと顧客との間で締結される契約上の合意であり、期待されるサービスレベルを明記したものです。
この法的な枠組みの中には、SLO(Service Level Objectives:サービスレベル目標)が含まれており、アップタイム(稼働時間)、速度、1秒あたりのトランザクション数などの具体的な指標が定義されています。
DoubleClickでは、以下の原則を念頭に置いてSLAを定義しました。
- 達成可能
- 目標は現実的であるべきです。
- 再現可能
- 指標は一貫して測定可能であるべきです。
- 測定可能
- パフォーマンスは定量化できるべきです。
- 意味のある
- 指標はビジネスにとって重要であるべきです。
- 相互に受け入れ可能
- 両当事者が条件に同意するべきです。
SLAは、顧客とベンダーの双方に利益をもたらします。
顧客にとっては、客観的な評価基準を提供し、劣悪なサービスからの保護となります。
ベンダーにとっては、明確な期待値を設定し、品質向上への動機付けとなります。
出発点、調査
私たちが初めてSLAの問題に取り組んだとき、まさに危機的状況にありました。
最初のステップは、すべての契約書を一覧化し、SLAとSLOを抽出し、関連するペナルティを文書化することでした。
この情報をデータベースに保存し、ビジネスリーダー、法務チーム、経営幹部といった関係者にSLAの重要性について教育を始めました。
最初から、私たちはエンドユーザーの体験に基づいたSLAに焦点を当てました。
つまり、サーバーの視点だけでなく、ユーザーの視点からパフォーマンスを測定することを意味していました。
普遍的な課題
長年にわたり、私は多くの企業が同様の問題に直面するのを見てきました。
すべてのSRE(サイト信頼性エンジニアリング)チームやDev(開発)チームが、自社と顧客との間にあるSLAを十分に理解しているわけではありません。
彼らはしばしば内部のSLOに強く集中し、それらの指標が契約上の約束とどのように結びついているかを見落としがちです。
例えば、重大なペナルティを受けた後、Slackのような企業は、内部目標と顧客への約束をより良く整合させるためにSLAの条件を見直しました。
SLAのアプリケーションパフォーマンス

SLAを確立することは、契約書にいくつかの文を記載するだけではありません。
私たちが100万ドルを支払うことになった理由は、SLA管理システムが存在しなかったからです。
そこで私たちは、「管理(Administration)」「監視(Monitoring)」「報告(Reporting)」「準拠(Compliance)」の4つの柱に基づく、サービスレベル管理(SLM)の運用を構築し始めました。
SLMプロセス
私たちは、ビジネスパートナー、顧客、法務チーム、財務チームと協力して、将来の高額なミスを防ぐためのプロセスを作り上げました。
このプロセスは「SLAライフサイクル」と呼ばれ、ビジネス目標と整合し、かつ有効性を保つために四半期ごとに見直されました。
- 1. データサイエンスを活用したリスクシミュレーション
-
SLMプロセスの中で最も重要なステップの一つは、社内のデータサイエンティストを活用してシミュレーションを実施することでした。
これらのシミュレーションでは、監視ツールからの過去データを分析し、SLA違反のリスクを評価しました。
その目的は、毎日のように違反されることのない現実的なSLAを設定しつつ、顧客の期待を満たすことでした。 - 2. 「もしも」のシナリオ
-
私たちはまた、可用性と収益の関係を理解するために、複数の「もしも」のシナリオを実行しました。
これらのシナリオは、1日の中のさまざまな時間帯や曜日におけるダウンタイムの影響を評価するのに役立ちました。
たとえば、ピークトラフィック時間帯に発生した10分間の障害が、オフピーク時間に同じく発生した場合と比べて、どのように収益に影響を及ぼすかを把握することができました。 - 3. SLAデスク
-
プロセスを効率化するために、私たちは2001年にオンラインツール、いわゆる「SLAデスク」を作成しました。
このツールにより、営業チームは顧客向けのSLAポートフォリオをリクエストできるようになりました。
これらのリクエストは、QoS(Quality of Service)チームによって審査・承認され、すべてのSLAが現実的で、測定可能であり、自社の能力と整合していることが保証されました。
外部SLAと内部SLAの整合
私たちが直面した最大の課題の一つは、外部SLA(顧客に約束した内容)と内部SLA(社内で測定していた指標)の不一致でした。
たとえば、顧客は広告配信の稼働時間を求めていましたが、技術チームはサーバの可用性を測定していたのです。
この問題を解決するために、私たちは外部と内部のSLOを整合させ、内部目標(ターゲット)を非常に高く設定しました。
これは大きな成果であり、1つの指標セットに基づいてSLAリスクの状況を把握し、運用上の卓越性を追求できるようになりました。
技術部門(運用、エンジニアリングなど)も、ビジネスSLAという概念に対する意識が高まり、違反しないことに強い関心を持つようになりました。
監視 ― SLA成功の鍵
可用性とパフォーマンスのために、私たちは3つの合成モニタリング製品に依存していました。
社内では、17のデータセンターでSitescopeを運用し、さらに2つの外部の合成モニタリング製品を使用していました。
可能な限り多くのツールから、できる限り多くのデータポイントを取得したかったのです。
リスクが非常に高いため、複数のツールに投資しないという選択肢はありませんでした。
このSLMプロジェクト全体は、実装および年間運用コストともに安くはありませんでしたが、私は「適切に実施しなかった場合の代償」を身をもって理解していました。
監視においては、できるだけ多くの観測点から、できるだけ頻繁にテストする必要があることが明らかになりました。
-
SLOのエンドポイントを1時間に1回しかチェックしない場合、次のチェックまで59分待たなければなりません。
この間隔が、誤ったダウンタイムアラートを引き起こす原因となることがあります。 -
また、統計的な有意性を確保するためには、多くのデータポイントが必要です。
データセットが小さいと精度と検出力が低下し、逆に大きいデータセットは偽陽性や偽陰性の管理に役立ちます。
差分パフォーマンス測定(DPM)の登場
私たちが直面した最大の課題の一つは、広告配信速度を効果的に測定し、それをSLAに反映させる方法を見つけることでした。
クライアントは自社サイトのパフォーマンスを見てスパイクを確認し、それを私たちのシステムのせいだと考えました。
一方で、私たちのパフォーマンステレメトリーには問題が示されていませんでした。
両者のチャートを相関させることができなかったため、それが私たちの問題なのか、他の誰かの問題なのか合意に至ることができなかったのです。
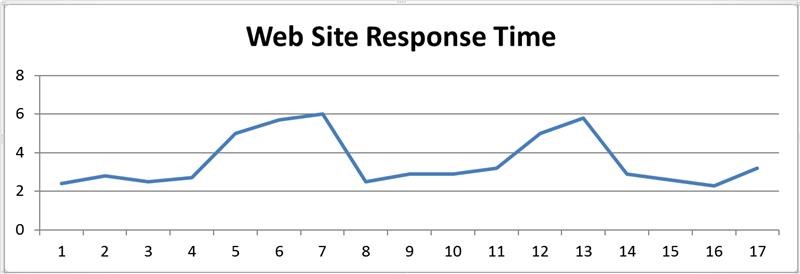
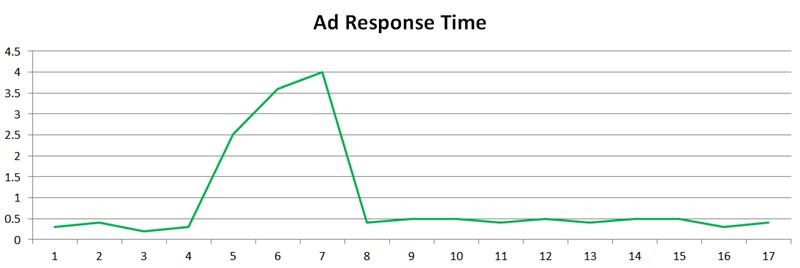
この課題に対処するために、私たちは「差分パフォーマンス測定(DPM)」と呼ばれる手法を開発しました。
私たちの目標は、DoubleClickのパフォーマンスと可用性を正確に測定し、それが顧客のページにどのような影響を与えているかを理解することでした。
また、自分たちが管理している部分について責任を持つことで、非難の応酬や責任の押し付けを回避したいとも考えていました。
この手法は、測定に文脈を追加するものでした。
DPMは明確さと比較性をもたらし、SLAから絶対的なパフォーマンス数値を排除しました。
差分パフォーマンス測定のレシピ(広告を用いた例)
- 1. 2つのページを用意します ― 1つは広告なし、もう1つは1つの広告リクエストを含むページです。
-
ページA = 広告なし
ページB = 広告1つ - 2. ページに他のサードパーティ参照(CDNなど)が含まれていないことを確認してください。
- 3. ページサイズ(KB)が同じであることを確認してください。
- 4. 両方のページのレスポンスタイムを測定すると、以下の指標が得られます。
-
差分応答時間(DR)は、「ページBのレスポンスタイム」から「ページAのレスポンスタイム」を引いた値になります。
差分応答時間の割合(DRP)は、DR ÷ A で求めます。
(例:ページAが2秒、ページBが2.1秒の場合、DRは0.1秒、DRPは0.1 ÷ 2 = 0.05、すなわち5%となります)
このアプローチにより、次のような原因で発生するノイズを排除できました。
- 私たちの管理の及ばないインターネット関連の問題(例:光ファイバーの切断)
- モニタリングエージェントの不整合(モニタリングツール自体の監視が必要になる)
- その他のサードパーティ依存要素
差分パフォーマンス測定(DPM)の影響を可視化するために、以下のチャートでは2つのシナリオにおけるレスポンスタイムを比較しています。
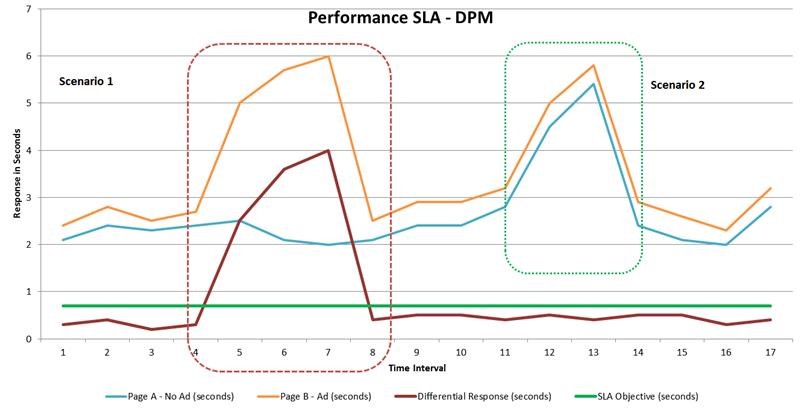
- シナリオ1
-
広告配信会社がパフォーマンスの問題を経験し、それが顧客のサイトに悪影響を与えました。
ベンダーは、Time 4からTime 8の間にSLAの閾値を超えて違反しました。 - シナリオ2
- Webサイト自体にパフォーマンスの問題が発生し、これは広告配信会社とは無関係でした。
報告 ― 透明性と説明責任
100万ドルのペナルティを受けて以降、SLA管理は最優先事項となり、CEOにまで可視性が拡大しました。
私たちは、DigitalFuelなどのツールを用いてリアルタイムで問題を検出し、コンプライアンスと違反に関する報告を月次で行いました。
2001年末には、100を超える運用レベル合意(OLA)を追跡しており、DoubleClickには品質重視の文化が根付いていました。
エンジニアから経営幹部に至るまで、すべての人がビジネスサービスの指標に意識を向けており、誰もSLAを違反したくないと考えるようになっていました。
教訓と今後の展望
DoubleClickで包括的なSLMプロセスを導入することで、私たちは次のことを実現できました。
- 最大で5つのSLOを含む数百件の契約を管理すること。
- 新しい製品にも対応できる、スケーラブルなSLAを提供すること。
- 高額なペナルティを回避することで、財務リスクを低減すること。
- 正確で意味のあるSLAを提供することで、当社の評判を維持すること。
- リアルタイムで違反を検出し、積極的な対応を可能にすること。
最大の利点のひとつは、SLAがリスクにさらされるタイミングを事前に把握できたことです。
たとえば、あと4分のダウンタイムが加わると12件の契約に違反し、何$(ドル)のペナルティが発生すると予測できました。
このような洞察は、運用チームの行動を促し、リリースの一時停止や稼働時間に影響を与える変更の防止につながりました。
一部の人々はSLAを軽視しますが、多くの場合、その懐疑は正当なものです。
非現実的な保証、実質的なペナルティの欠如、曖昧な測定基準といった「悪いSLA」は、信頼を損ねます。
「パケットロス0%を保証」といったSLAをよく見かけますが、それがどう測定されているのか尋ねると、その保証がいかに無意味であるかすぐに明らかになります。
このようなSLAは、SLAという概念全体に悪い評判を与えてしまいます。
しかし、正しく構築されたSLAは不可欠です。
SLAは顧客とベンダーの足並みを揃え、摩擦を減らし、責任の押し付け合いを排除します。
とはいえ、顧客は、見た目だけが良いSLAではなく、「実際に役立つSLA」を求めるべきです。
ベンダーを倒産に追い込むことが目的ではなく、責任を持たせることが目的です。
もしベンダーがサービス提供に失敗した場合には、その影響を自ら受けるべきなのです。
SLAの進化
2001年当時、私たちはSLA管理が重要であることを理解していましたが、今日のクラウド主導の世界において、これほど不可欠なものになると予測できたでしょうか?
SLAは、単なる稼働時間の保証から、レイテンシからデータレジデンシーに至るまでをカバーする複雑な合意へと進化しました。
XLO(エクスペリエンスレベル目標)という概念も登場しており、これはサーバーのパフォーマンスだけでなく、顧客の体験に焦点を当てた指標です。
このように、内部の指標から顧客の成果への焦点の移行こそが、パフォーマンス管理の未来です。
パート2では、企業がどのようにして内部指標を「本当に重要なもの」―つまり顧客の体験―と整合させられるのかを探っていきますので、ご期待ください。
さらに学ぶ
SLA、SLO、SLIについて初心者ですか?
本記事を読めば、その基本、ベストプラクティス、そしてそれらがサービスの信頼性にどのような影響を与えるかを学ぶことができます。