
インシデント・レビュー - Google Cloudの障害がエンドユーザに広く影響を与える
翻訳: 島田 麻里子
この記事は米Catchpoint Systems社のブログ記事 Incident Review – Google Cloud Outage has Widespread Downstream Impactの翻訳です。
Spelldataは、Catchpointの日本代理店です。
この記事は、Catchpoint Systemsの許可を得て、翻訳しています。
インターネットの障害は、あなたが、エンドユーザであれ、SRE(サイト信頼性エンジニアリング)やDevOps部門の責任者であれ、平常心を保ちながらインシデント対策本にあることを実践しようとするときに、意表を突いてきます。
お客様のために信頼できるサービス提供を担なう人々にとって、通常経験する障害には、可及的速やかに解決すべき、火災報知機やビデオ電話が鳴り響くような事態の障害も含まれます。
とはいえ、私たちは、障害がエンドユーザにとってどんな意味をもたらすのかをしばしば忘れがちです。
2021年11月16日火曜日、一体どうしてか、私はちょうど靴を履き違えた時のような感覚を思い知らされました。
エンドユーザの立場からすると: Google not foundエラー
火曜日、Homedepot.com(ホームデポ・米大手のホームセンター)で自宅用の商品を購入しようとしたところ、ブラウザにいつもと違うページが表示されました。
それは、Googleのボットページの404メッセージでした。
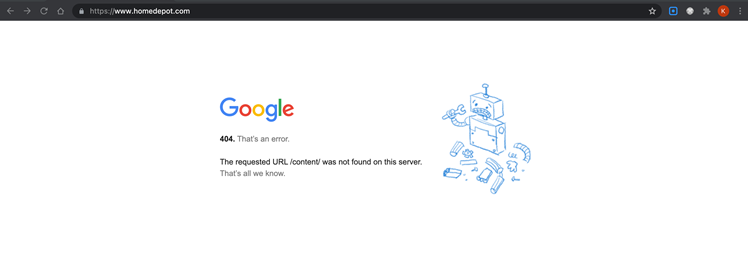
驚いて 「リロード」をクリックしました。
だめです、やはり同じページが表示されました。
URLをwww.付きで再度入力し、次にwww.無しで入力しましたが、やはり同じように壊れたGoogleボットのイラストが私を出迎えました。
「まあ、Googleがホームデポを買収するなんてありえないよな 」などと思っていました(Googleの親会社であるアルファベット社には、Hで始まる会社が抜けてはいますが)
技術ギークの私が次に考えたのは、もしかしたら自分がGoogleのパブリックDNS 8.8.8.8を何らかの形で使っており、DNSルックアップが失敗していて、Googleが自分で解決できないドメインをIPにルーティングする新機能を開始することにしたのではないか、ということでした。(以前いくつかの企業も使っていたテクニックなのです)
しかし、そのどちらでもありませんでした。
消費者でいることを諦め、Catchpoint社のプラットフォームにアクセスし、何が起こっているのかを確認することにしました。
答えはすぐにわかりました。
複数のサイトで障害が発生し、全てのサイトで同じエラーメッセージが表示され、それらのサイトは全てGoogle Cloudの顧客だったのです。
Googleのステータス・ページにアクセスしましたが、まだ何も掲載されていませんでした…
そして、問題が発生してから30分経っても何も掲載されていませんでした。
それでは、この事件そのものを簡単にご紹介しましょう。
2021年の最新の障害
11月16日(火)、米国東海岸時間の正午過ぎから、Google社以外の多くの企業のWebサイトがオフラインになり、Google 404ページが表示されました。
何が起こったのでしょう?
Googleは、あなたのお気に入りのサイトを買収して、それを閉鎖したわけではありません。
実際は、本当に多くの企業が、ホスティングに利用しているGoogle Cloudで発生した2021年の最新の障害による巻き添えを食らったのです。
この影響により、多くの企業は収益を失い、企業の評判を落とす恐れがありました。
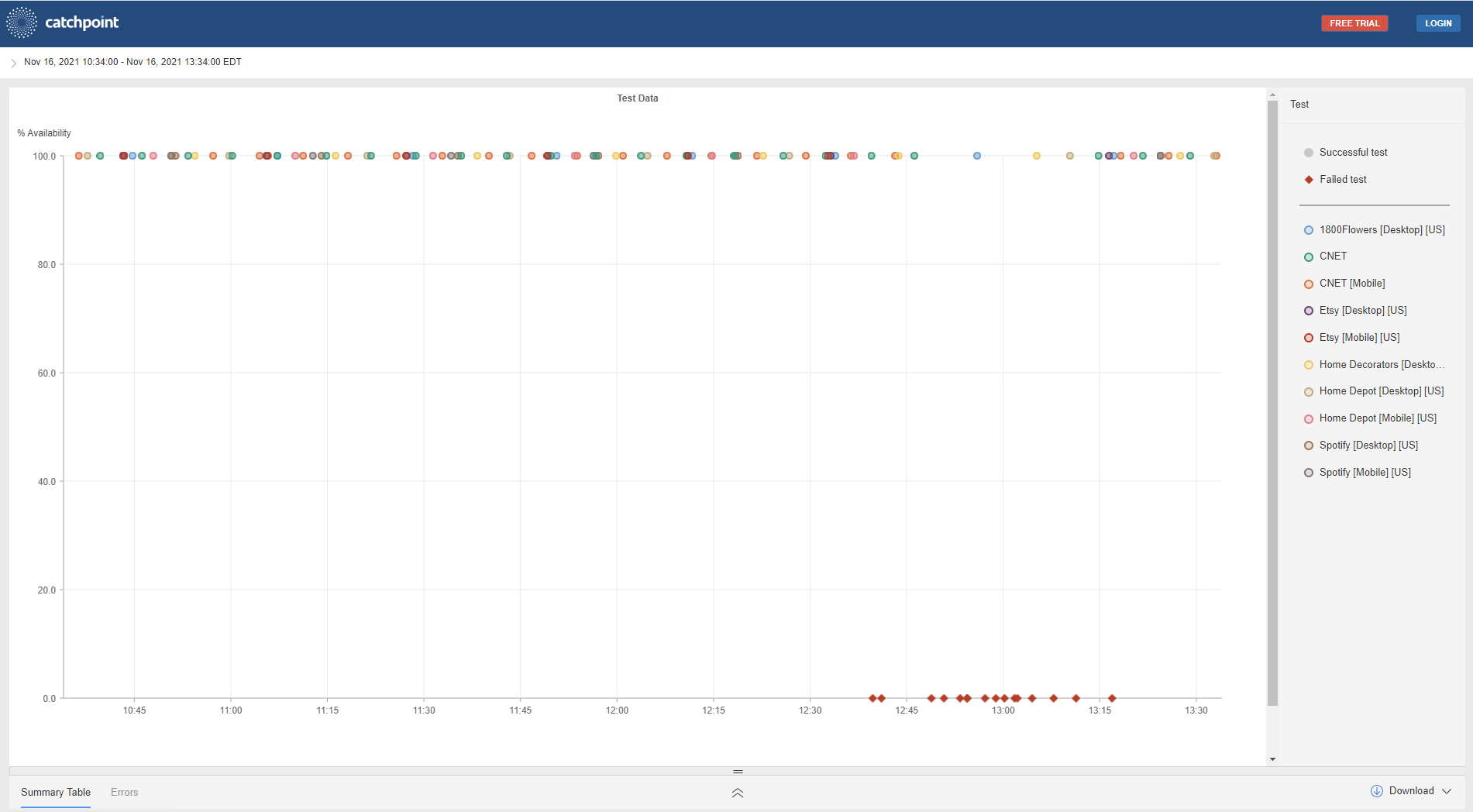
Catchpointはテストの失敗の急増を観測
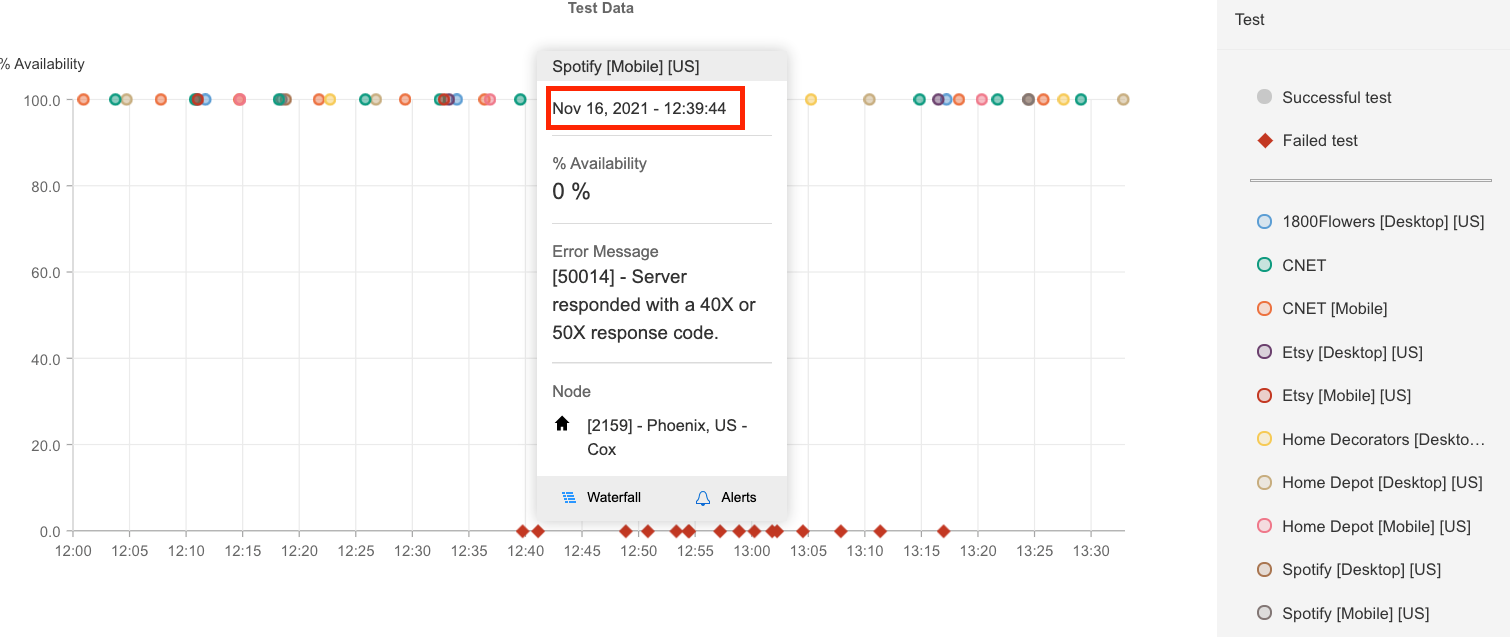
Catchpoint社では、米国時間午後12時39分から、突然の観測障害が発生しました。
大小さまざまな企業に影響を与えました。
影響を受けた企業の中には、Nest、1800Flowers、CNET、Home Depot、Etsy、Priceline、Spotify、そしてGoogle自身などが含まれています。
13時10分頃には問題が一部解決しました。
しかしGoogle社によると、影響の出た全ての製品について問題が完全に解決するまでには約2時間かかり、米国時間の14時28分まで続きました。
すぐに復旧した企業もあれば、しばらくの間エラーが発生したり、読み込みに時間がかかったりする企業もありました。
下の図は、これらのサイトの多くが障害発生時に稼働していたことを示しています。
安定した高稼働率から0%になるという、崖っぷちからの急降下がどこで起きたかがよくわかります。
お客様への影響は、利用しているGoogle Cloudサービスによって異なりました。
例えば、Google App Engineでは、米国の中央部と西ヨーロッパの一部でトラフィックが80%減少しました。
Google Cloud Networkingのお客様は、Webサイトのロードバランシングの変更ができず、404エラーページが発生しました。
実際、影響を受けたのはWebページだけではなく、以下のような複数のGoogle Cloud製品も含まれました。
- Google Cloud Networking
- Google Cloud Functions
- Google Cloud Run
- Google App Engine
- Google App Engine Flex
- Apigee
- Firebase
「ネットワーク構成サービスに潜むバグ」
Google Cloudは、サービスの障害と、エンドユーザに齎した全ての不具合について謝罪しました。
この問題の原因について、同社はステータスページで「(分散システムの)リーダー選挙(※)の際に発生したネットワーク構成サービスの潜在的なバグ」であると示しています。
同社は「今後このような問題が発生しないよう、2種類の保護手段を用意している」と述べています。
※訳注: リーダー選挙は、分散システムにおけるシステム調整の仕組みです。
リーダー選挙とは、分散システム内の1つ(プロセス、ホスト、スレッド、オブジェクト、または人間)に特別な権限を与えるというシンプルなアイデアです。
これらの特別な権限には、作業を割り当てる機能、データの一部を変更する機能、またはシステム内の全てのリクエストを処理する責任が含まれます。
リーダー選挙は、効率の向上、調整の削減、アーキテクチャの簡素化、運用の削減のための強力なツールです。
一方、リーダー選挙では、新しい障害モードとスケーリングのボトルネックが発生する可能性があります。
さらに、リーダー選挙では、システムの正確性を評価するのが難しくなる場合があります。
引用元: 分散システムのリーダー選挙
(長年にわたる障害の中で)最新の今回の事件は、パブリック・クラウドの大規模な導入に伴うパブリック・クラウド・ベンダーの障害がエンドユーザに与える影響がいかに大きいかということを示しています。
また、サードパーティベンダーの障害に対し、企業がいかに脆弱であるかを示しています。
多くの企業が、ビジネスを遂行し、顧客にデジタル体験を提供するために、公共のインターネット、サービス、インフラに依存していることがよくわかります。
このような状況には多くの利点がありますが、課題としては、これらの企業は自分の組織を動かす基盤となるインフラをほとんど、あるいは全くコントロールできないということです。
どの企業にとっても重要な3つの教訓
今回の障害で得られた3つの重要な教訓を以下にまとめましたので、ご参考ください。
教訓1: 失敗はつきものだが、適切なエラーページを使ってエンドユーザに伝えることの重要性を見落としてはならない。
ユーザがステータスページを見つけたり、Twitterで自社のアカウントが発信する情報を確認するとは考えないでください。
ユーザはすでに次の競合他社に移っているでしょうし、最終的にその障害のことはニュースで読むことになるでしょう。
この事例でエンドユーザを混乱させたものがあるとすれば、それは人々を迎えたGoogleのエラーページです。
ほとんどの人は、ホスティング会社ではなく、自分がアクセスしようとしたWebページの会社からのエラーメッセージを期待したことでしょう。
Google Cloudがこれを修正できるかどうかは少し不明です。
もしかしたらできないかもしれません。
とはいえ、どのような企業であっても、このような失敗に備え、DNSやCDNの設定を変更し、自社のブランディングやメッセージングを施した適切なエラーページを表示し、自社の言葉で不具合を謝罪するプロセスを導入する必要があります。
そして理想的なのは、それを愉快なものにすることです。
人間らしくあり続けて、エンドユーザと関わりを持つことを恐れてはいけません。
今回の例のように紛らわしいエラーページや、「サーバが応答できませんでした」などの不明瞭なエラーよりも、適切なエラーページの方が良いに決まっています。
更に悪いのは、画面に何も表示されず、サーバへの接続に無限に時間がかかる場合です。
教訓2: 外部のファイアウォール、データセンター、クラウドといったサービスに適切なオブザーバービリティを確実に実装すること。
多くのオブザーバビリティ・プラットフォームは、自社製品(トレースやロギング)に合わせて「オブザーバビリティ」を定義していますが、実際には、オブザーバビリティはトレースが登場するよりもずっと前にその起源がありました。
制御理論において、オブザーバビリティは、外部出力の知識からシステムの内部状態をどれだけうまく推測できるかを示す指標として定義されています。
ニュースや顧客からの苦情などで、企業がダウンしていることを知るのは初めてのことではないでしょう。
このような方法で問題を見つけることは避けたいものです。
クラウド・プロバイダの外から自社のサービスを観察することで問題を先取りする方がはるかに優れています。
コードトレースやログだけに頼っていると、問題が見えてきません。
積極的に自社のサービスを最高の状態に保ち、自社が依存し、単一障害点となるようなサービスプロバイダやインフラプロバイダを把握しておきましょう。
教訓3: 最後に、サービスのSLAを追跡し、MTTRを把握する。
チームやプロバイダがどれだけ問題を良好に解決しているかを追跡する必要があります。
このようにして信頼を築き、彼らが自分の責任を全うしていることを検証していくのです。
独立した監視・観測ソリューションからのリアルタイムデータにより、問題がいつ始まり、いつ解決されたかを正確に知ることができます。
その問題が自社サイトに与えた影響を正確に把握するには、ステータスページに頼ることはできません。
誰もが同じ影響を受けているわけではありません。
障害発生が僅かに早かったり遅かったり、障害影響時間も短かったり長かったり…