
2022年2月22日のSlack障害 ― 「おはよう!16分間のストレスです!」
翻訳: 島田 麻里子
この記事は米Catchpoint Systems社のブログ記事 Slack Outage of 2/22/22 – Good Morning! Here’s 16 Minutes of Stress!の翻訳です。
Spelldataは、Catchpointの日本代理店です。
この記事は、Catchpoint Systemsの許可を得て、翻訳しています。
地震や津波の検知、軍事防衛、ビジネスや金融の危機など、早期警報システムの重要性が理解されるようになって久しいです。
ではなぜサービスプロバイダ、特にSaaS(Software as a Service)を提供するプロバイダは、そうではないのでしょうか?
時は金なりという言葉のように、1分が数百万ドルにさえなることのある世界では、企業や消費者のエンドユーザに対するサービスの供給チェーンと配信チェーンを大変注意深く見守ることが重要です。
techjuryによると、Slackのデイリーアクティブユーザは1,000万人以上、そのうち300万人は有料会員で、1日に平均9時間Slackにログインしているそうです。
そう、Slackにとって、自分たちのサービスがどのように機能しているのか、ユーザがどのような体験をしているのかを十分に理解することは重要です。
しかし、あなたがSlackを利用して組織内のコミュニケーションを維持している、世界で60万社の企業のうちのひとつに所属しているならば、Slackの意向をはっきり把握していることが大切です。
顧客にとって、生産性の高いアプリケーションがダウンすることより悪いことは、それが自分の身にも起こるかもしれないと考え、存在しないものを解決しようとしてさらに時間を浪費することです。
これは、前例がないわけではありません。
TechTargetによると、2019年、Slackは1四半期あたり820万ドルのクレジットをベンダーへ発行することを余儀なくされた障害があった後、クラウドのサービス品質水準(SLA)を縮小しました。
Slackの財務責任者であるアレン・シム氏は、当時の電話会議でアナリストに対し、ダウンタイムの財務的な影響をさらに大きくしたのは、当社が創立したての会社だったころからの契約で、クレジット払いの倍率が異常に高かったことです
と述べました。
私たちはこれらの条件をより業界標準に近いものにし、かつ、お客様にとって使い勝手の良いものにしました
その後、障害による収益への影響はほとんどないはずですが、ブランドへのダメージ、解決努力、生産性の低下、競合への脆弱性などの問題による無形の影響は残り、数値化することは困難です。
さて、Slackユーザの立場から見てみると……
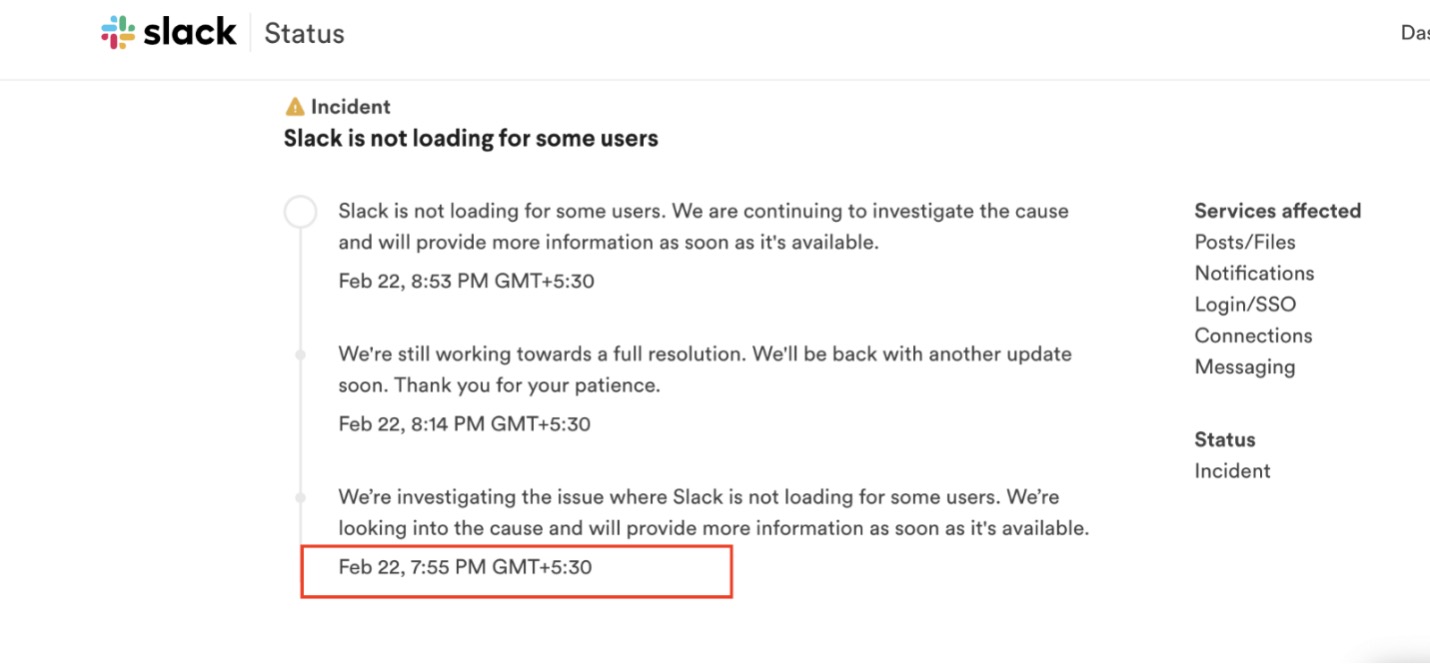
2月22日の午前9時頃(米国東部標準時間)サービスに問題が発生し始めたとき、Slackからそのような指摘はありませんでした。
しかし、Catchpointのユーザであれば、すぐにアラートが表示されたので、Slackからの連絡なんて必要なかったでしょうね。
この事象に対する組織の反応は、ユーザの種類や立場によって様々です。
私がSlackを利用している企業のIT責任者であるなら、まずSlackのサービスサイトを確認し、障害発生から数分経過してもSlackからの更新がないことを報告します。
自分の役割としては、社内でアラームを鳴らす前に、エラーを確認する必要があります。
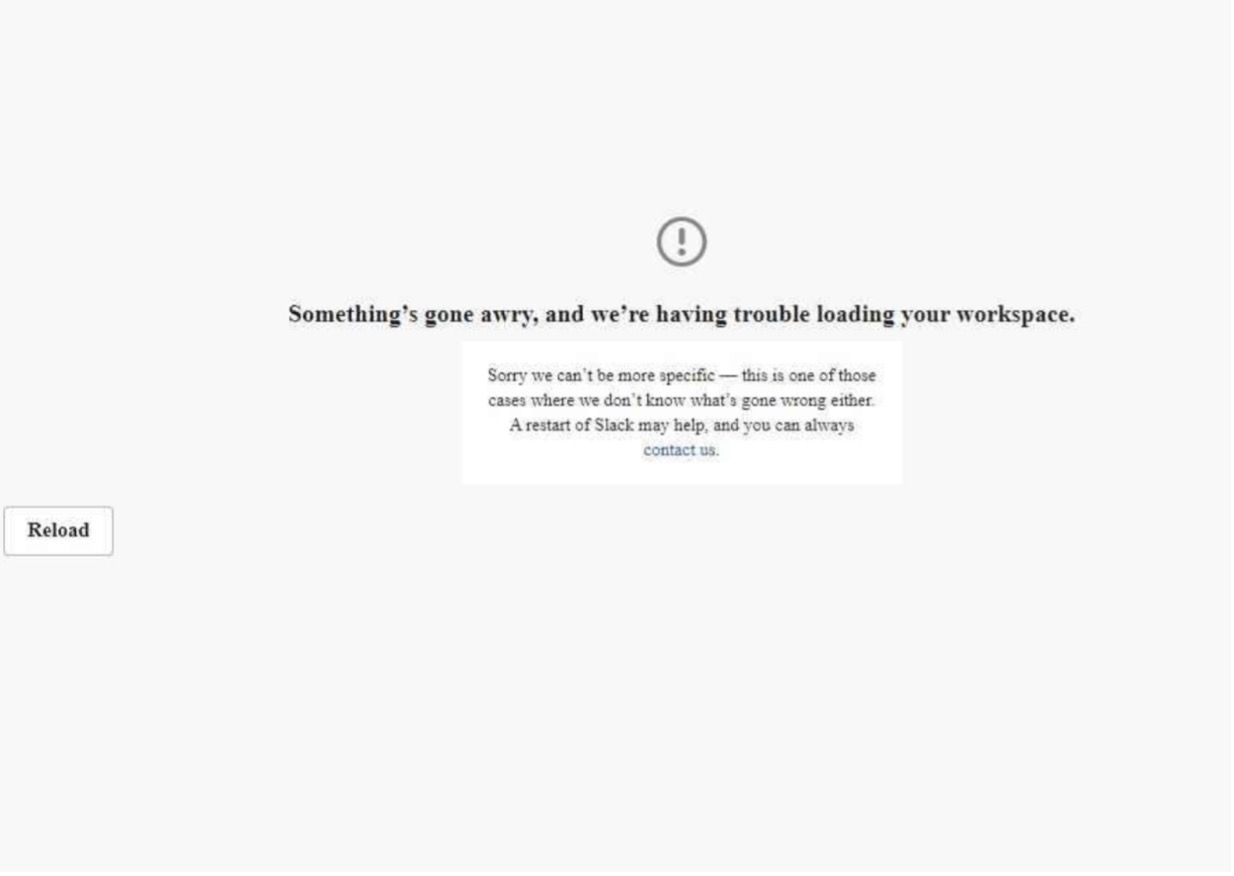
幸いなことに、私は自分でSlackにログインする必要はありません。
Catchpointテストは、ログインに成功すると表示される、エンドユーザが見るこのようなエラー通知画面をキャプチャするのです。
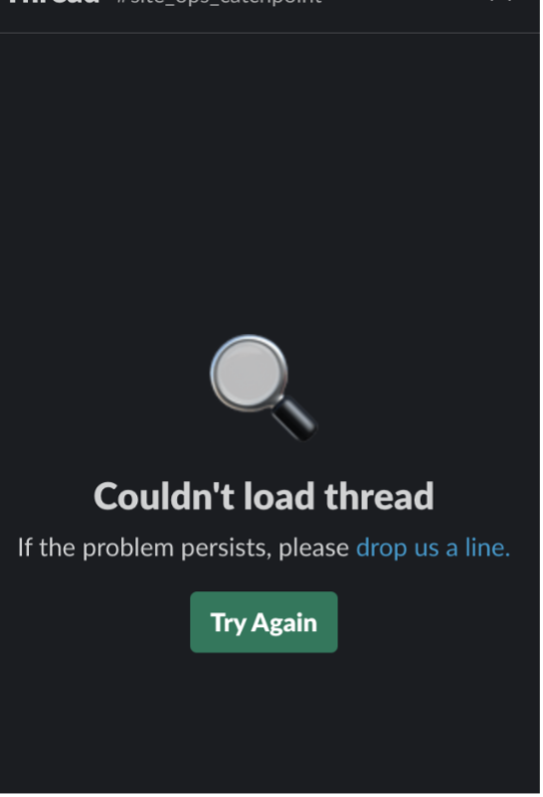
そして、ユーザが会話画面を開こうとしたときのこれ。
それだけでなく、Catchpointのウォーターフォールレポートには、ページ上のエラーリクエストが表示され、アプリケーションに取り込まれたエラーがポストバックされているようです。
(このリクエストは、失敗したテスト実行時にのみ表示されます)

「ヒューストン、問題発生!」
この時点で、私はインシデント対応ライフサイクルの「検知」段階をうまく通過し、その次の段階、その事象を正真正銘の障害として「特定」することができたはずです。
次に大変なのは、トリアージです。
誰に知らせればいいのか、最悪、寝ているところを起こせばいいのか。
誰の朝食を中断して、この原因を突き止めるのに協力しろというのだろう?
まずは、無実が証明されるまで有罪である人々……つまりSlackのネットワークチームから始めましょう。
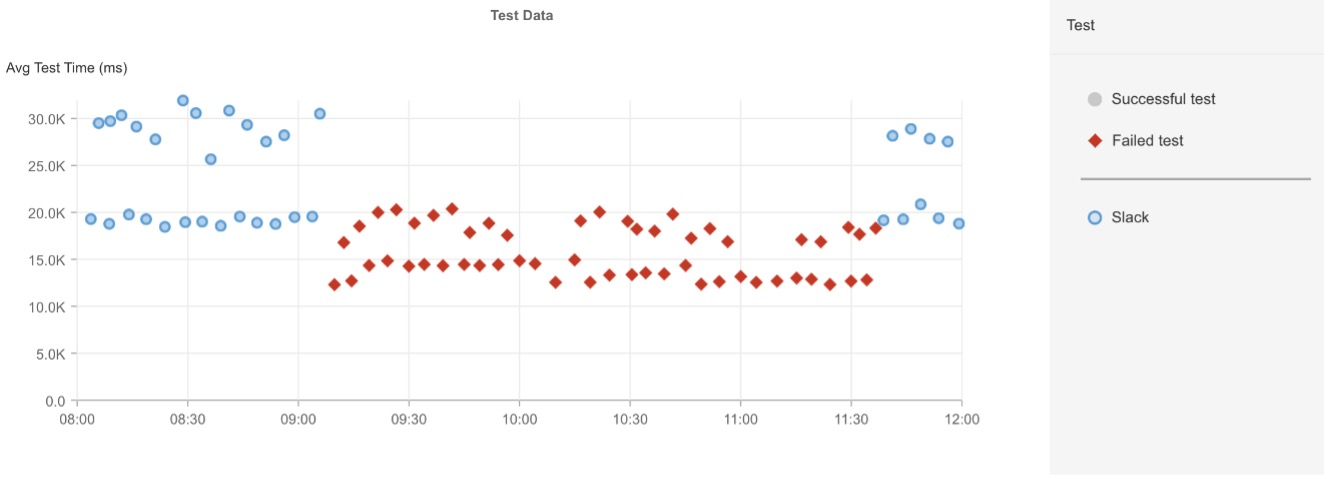
下のグラフは、多くのステップのうち、どこでテストが失敗しているかを示しています。

なるほど、ネットワークが原因ではないんですね。
しかし、念のためどのようなリクエストが失敗しているのかを見てみましょう。
Catchpointにはユーザの行動をエミュレートする機能があるので、Slackサーバからエラーが出る前に、ユーザがログインしてかなりの数のアクションを取れていたことがわかります。

チャートは
<root>/api/client.boot?_x_id=noversion-1645542869.027&_x_version_ts=noversion&_x_gantry=true&fp=e3
というリクエストが原因であると指摘しています。
下のグラフは、その障害の前後を示したものですが、上記のリクエストが会話やメッセージページの機能を担う重要なコールの一つであることがわかります。
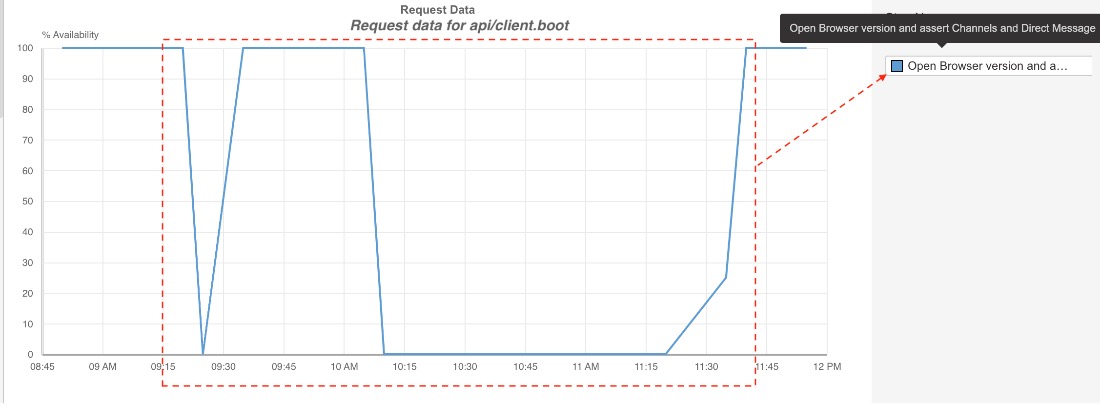
確定……Slackネットワークチームに一日を始めさせることができる!(どうせマウンテン・デューを飲んでる人たちだし)
しかし、私がSlackのヘルプデスク責任者であれば、今頃、とても熱いコーヒーを噴き出しているところです。
ユーザはSlackにログインできても、他のことをすることができない……とりわけこれが朝一だったわけですから、多くの人が何が起こっているのかわからず、サポートスタッフにチケットや電話が殺到してしまうわけです!
私は一息ついてから、Slackに障害が発生していること、追って連絡があるまで他のコミュニケーション手段を探すようにと、Catchpointのユーザコミュニティにメールを送りました。
私がこれだけのことをあっという間にできてしまったわけですから、Catchpointのユーザならすでに知っていることを、Slackが約16分かけて世間に知らせたというこの差は大きいでしょう。
あなたの組織では、従業員一人当たり16分の生産性を失う余裕がありますか?
また、組織のコントロールが及ばない状況下で、従業員がチケットを開いたり、ヘルプデスクに電話したりしていませんか?
もしあなたが多くの企業と同じように、答えが「ノー」で、Catchpointのような業界をリードするオブザーバビリティ・ソリューションにまだ投資していないなら、今でもそれをするのに遅いということはありません。
次の障害まで待たずに、オブザーバビリティの旅を始めてください。
Catchpointは、あなたのパートナーになる準備ができています。
今すぐお問い合わせください。
★Speeddataのご案内はこちら。