
DNS解決に失敗した事例から得た3つの教訓
翻訳: 島田 麻里子
この記事は米Catchpoint Systems社のブログ記事 3 Lessons from a DNS Resolution Failure Incidentの翻訳です。
Spelldataは、Catchpointの日本代理店です。
この記事は、Catchpoint Systemsの許可を得て、翻訳しています。
サイト信頼性エンジニアやネットワークエンジニア、あるいは単にデジタルサービスの監視に携わっている人なら、DNSが正しく動作していなければ、ユーザが障害を体験するということはもうご存知のことでしょう。
しかし、DNSはWebの回復力と可用性を確保する上で重要であるにも関わらず、正しく監視されていないことが多く、その結果、障害が発見されず、ビジネスに何らかの連鎖反応が生じる可能性があります。
さらに、今日ではほとんどの企業が自社でDNSインフラを維持せず、「マネージドDNSプロバイダ」と呼ばれるサードパーティ企業にDNSをアウトソースしています。
企業は、信頼性の高いDNSインフラの運用と維持をプロバイダに依存しており、サービス内容合意書(SLA)は、プロバイダがその業務を果たすかどうかを確認するために頼りにしているものです。
ベンダーを信頼することは大切ですが(契約書も有用ですが)、ベンダーが契約責任を果たしているかを検証し、確かにすることは更に重要であり、DNSを正しく監視することが成功のカギとなります。
DNS解決失敗時のMTTRを短縮するには、剣ではなくメスが必要
Catchpointにおいて、DNSの監視は、全てのお客様にとって中核となるユースケースです。
大規模な障害や設定ミスを迅速に検出し、この複雑で壊れやすい技術に対するお客様の監視戦略の強化を支援します。
最近、ある大手eコマースのお客様(S&P500にランクインする10億ドル規模の企業、本社は米国)のDNSに関する興味深い問題のトラブルシューティングをお手伝いしましたが、これは、私たちのサービスをよりよく監視する方法という点で、誰もが教訓を得ることができるものです。
このeコマース企業は、Catchpointのテストを通じて、米国の特定の場所から、同社の特定のWebサイトで断続的にDNS解決に失敗していることを発見しました。
私たちは、彼らが経験した問題を掘り下げ、レゾルーションチェーン全体を見渡し、どこで問題が発生したのかを特定し、その解決方法を明らかにし、今後の監視戦略の拡張を一緒に考えました。
このブログでは、全てのSRE、Devops、NetOpsが注目すべき、DNS監視とオブザーバビリティの3つの重要な教訓を紹介します。
3つの重要な教訓
1. DNSだけでなく、サードパーティへのCNAMEを監視する
多くの企業は、デジタル・プレゼンスの重要な側面をサードパーティのSaaSプロバイダに依存しています。
Catchpointでは、2つのCDN、ホスト型CMS、マーケティングオートメーションサービス、キャリア・履歴書管理サービスを利用していますが、これらは全て「catchpoint.com」のサブドメインの後ろにあり、サービスを指すCNAMEに依存しているのです。
私たちは、これらのサービスの一つひとつを監視し、そのうちのどれかに障害が発生した場合の対応策を用意しています。
今回のケースでは、お客様はキャリアページをサードパーティのSaaSプロバイダに依存しており、そのドメインは単にプロバイダに対するCNAMEを持っていただけでした。
サービスを監視していたところ、断続的にDNSに障害が発生することに気づき、その原因が自分たちのDNSではなく、別のものにあることを確認しました。
企業のエンドユーザは「career.company.com」にアクセスしますが、裏側ではこのドメインに「[nameofcompany].phenompeople.com」のCNAMEが設定されているのです。
プライマリドメイン(お客様管理)はDNSSECに依存せず、CNAMEドメインはDNSSECを実装していました。
DNSSECは、IETFが「……DNSデータの起点認証と完全性保護、および公開鍵配布手段を提供する」(引用:RFC4033)ために導入した機能です。
これは、暗号技術(RRSIGおよびDNSKEYレコードによる)と信頼の連鎖(DSレコードによる)を用いて返されるレコードの信頼性を検証することを目的とした、一連のDNSリクエストとリプライから構成されています。
ドメインの解決中、エンドユーザのマシンは「再帰的DNSリゾルバ」にアクセスし、DNSを再帰的に検索し、DNSSECを検証し、最終的にドメインのレコードを送り返します。
この再帰的リゾルバは、まず.com GTLDの権威ネームサーバに問い合わせ、次に権威ネームサーバを受信し、最後にPhenompeople.comドメインの権威ネームサーバのひとつに問い合わせます。
次の切り抜き画像からわかるように、GTLDサーバの後者の応答にはRRSIGレコードと2つのDSレコードが含まれています。
つまり、phenompeople.comは署名されており、リゾルバはDNSSEC検証を行うことになっているのです。
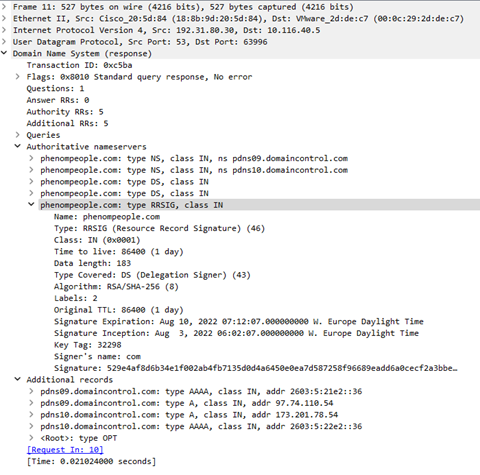
これはリゾルバによって正しく実行され、リゾルバはPhenompeopleドメインの権威ネームサーバの1つ(現在はpdns10.domaincontrol.com(173.201.78.54)と特定されている)に問い合わせ、DNSKEYレコードを要求し、DNSSEC検証を進められるようにします。
2.UDPだけでなくTCPも監視する
DNSは主にUDPに依存していますが、特定のシナリオではTCPもフォールバックとして使用します。
そのため、単にUDPでDNS問い合わせを送るだけでは、DNSの監視は十分とは言えません。
そして、このDNSの不具合の例で問題になるのは、ここからです。
DNSKEYの問い合わせを送信すると、pdns10.domaincontrol.comから提供された答えはUDPで処理するには長すぎるため、次の切り抜き画像からわかるように、権威ネームサーバはTC(切り捨てられた)フラグが設定されたメッセージで返信します。
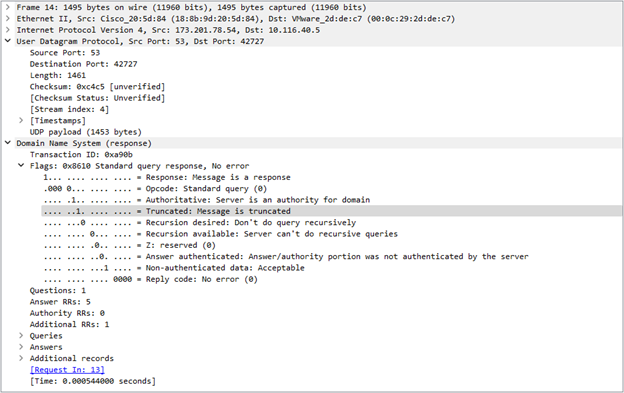
その結果、再帰リゾルバは全く同じサーバに全く同じ問い合わせを行いますが、今度はTCP(Transmission Control Protocol)を使用します。
しかし、TCPコネクションはサーバによって引き裂かれます。
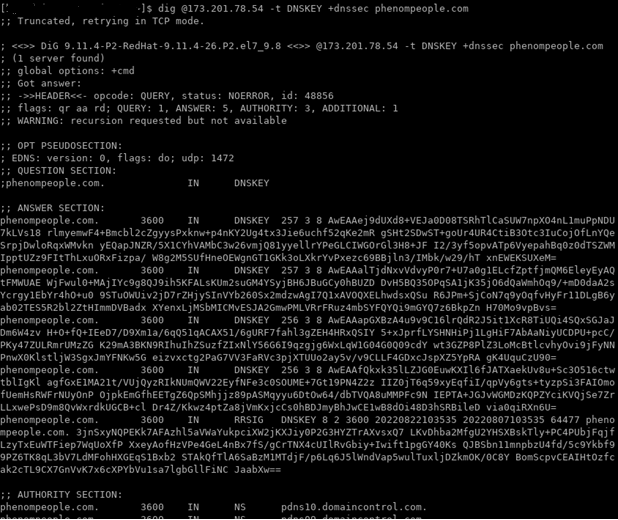
次の切り抜き画像のパケット番号20をご覧ください。

同じマシンから同じ権威ネームサーバにDNSSECに関連するDigを手動で実行したときにも、同じことが起こっていることが確認されました。

この場合、以下の「tcpdump」トレースから、サーバはサイズ1460の最初のTCPパケットで応答し(5)、まさにTCPハンドシェイク(2)で交渉されたMSSの値ですが、DNS応答の末尾データを含む2番目のTCPパケットを送る前に、サーバはTCPセッションを停止することにした(7)ことがわかります。

3. クラウドだけでなく、エニーキャストも監視する
DNSは非常に複雑であり、速度の必要性から、ほとんど全てのDNSインフラはエニーキャストに依存して、ユーザを最も近いDNSサーバに迅速にルーティングするようになっています。
この問題は、マネージドDNSプロバイダにバグや設定ミスなど、サービスに影響を与える可能性のあるものがあった場合、その問題がエニーキャストの多くの拠点のいずれかに影響を与え、その結果、お客様に小規模な障害をもたらす可能性があることです。
ニューヨークからDNSを問い合わせた場合とシカゴから問い合わせた場合では、異なるサーバに到達する可能性があります。
しかし、これは地理的な問題だけではありません。
同じ都市からATTとVerizonをISPとして問い合わせを実行すると、異なるデータセンターの異なるDNSサーバに問い合わせを実行することになります。
DNS監視の最も一般的な形態は、データセンター/クラウドからの探査、またはAWSやGoogleCloudにしかないAPM(オブザーバビリティ・プラットフォーム)からの一般的なブラウザ合成に依存するため、この監視は非常に複雑で、DNSの障害を引き起こしている原因については、極めて限定的な可視性しか得られません。
お客様のケースに戻ると、イタリアからとラスベガスから全く同じ問い合わせをしても、適切な回答が得られることに気づきました。
マネージドDNSプロバイダは、ネームサーバをエニーキャストに依存しており、その拠点の一部(米国内)だけが、TCP上のDNS問い合わせを適切に処理できないDNSサーバを保有しています。
私たちは、この問題を示しているノードの1つからそのネームサーバ上でさらにいくつかのテストを行いました。 そして、+dnssecオプションが設定されているときだけdigが失敗すること、つまり、DNSリクエストにDOビットが設定されていること、言い換えれば、digからリゾルバへのリクエストは、要求したレコードとともにRRSIGレコードも提供することが確認できました。
以下は、TCPでDNSKEYを要求して成功したときの切り抜き画像です。
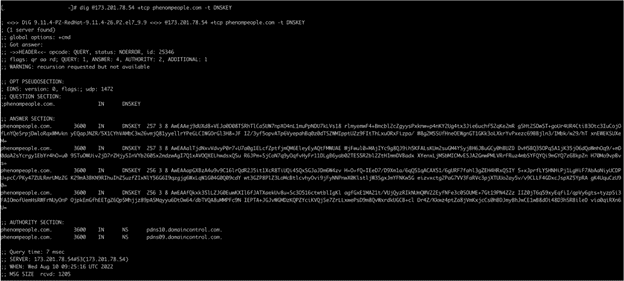
我々は、pdns10.domaincontrol.comの問題は、生成される返信のサイズに何らかの関連があると考えています。
問題が発生したノードでそのサーバから受信した全ての返信は、確かにTCPセッションで設定されたMSS(1440バイト)よりも小さいです。
そして、DNSSECは大きなメッセージを生成することが知られています。
実際、イタリアからdigを実行した際に受け取った返信のサイズは1813バイトでした。
その証拠に、問題を起こしたノードからエニータイプでdigを実行すると、同じ問題が発生することがわかりました。
これは通常、大きなレスポンスにつながります(有効な場合)。

主要なポイント
DNSに関連して監視すべきことは何でしょうか?
まず、DNSは見た目よりもずっと複雑であることを、もうお分かりいただけたかと思います。
この出来事は、3つの明確な教訓を示しています。
1. ドメインの後ろや前にある重要なCNAMESを監視する
DNSの設定やインフラには問題がなくても、ビジネスがSaaSプロバイダに依存している場合、ユーザや業務に影響を与えるような問題が発生する可能性があります。
顧客は、問題が御社のCDNなのか、御社のSaaSプロバイダなのかを知りません。
ただ、影響を受けたドメインに御社のブランドが表示されているのを見るだけです。
2. UDPだけでなく、TCPも監視する
DNSSECの失敗は、署名だけではありません。
ネームサーバがTCP上のDNSを適切に処理しているかどうかもまた知る必要があります。
必ず監視してください。
3. クラウドやデータセンターのためではなく、エニーキャストのために監視する
権威DNSサーバは、ほとんどの場合エニーキャストに依存しています。 AWS上のいくつかのブラウザの合成ロケーションから監視するだけで、世界の残りの人々があなたのサイトに到達できると思い込まないでください。
顧客と同じように、広く分散した場所から監視する必要があります。
さらに詳しく
昨年発生した、Slackの15時間に及ぶ障害においてDNSが果たした役割について読み、DNSの問題をより迅速に解決する方法への理解を深めてください。
Catchpointがお客様の企業にどのように貢献できるのか、実際に試してみたいという方には、喜んでデモンストレーションをさせていただきます。
お問い合わせはこちらから