
Microsoftのクラウド障害により、全世界の労働力に影響が及ぶ
翻訳: 島田 麻里子
この記事は米Catchpoint Systems社のブログ記事 Microsoft Cloud Outage Causes Global Workforce Disruptionsの翻訳です。
Spelldataは、Catchpointの日本代理店です。
この記事は、Catchpoint Systemsの許可を得て、翻訳しています。
2023年1月25日、クラウドサービスプロバイダのMicrosoftが長時間の障害に見舞われ、私たちの多くが(全世界で10億人以上のユーザが)重要な業務活動をMicrosoftに依存していることが明らかになりました。
Microsoftのような重要なワークフォースサービスが停止すると、世界中のチームが大きな混乱に陥るため、インターネット・レジリエンスはビジネスの優先事項となっています。
ITチームが問題をいち早く発見し、その原因を切り分け、トラブルシューティングを行うことで、通常業務を再開し、ビジネスへの影響を最小限に抑えることができます。
2023年1月25日07:08(UTC/02:08 EST)から世界各地で複数のMicrosoftサービスに障害が発生し、約5時間にわたりユーザに影響を与え続けました。
この障害は、Teams、Outlook、SharePoint OnlineなどのMicrosoft 365サービスだけでなく、HALOなどのMicrosoftゲームやMicrosoft Defender for Identityなどのセキュリティ機能、さらには同社の冠たるクラウドサービスであるAzureにも影響を及ぼしました。
同社のサービスヘルスダッシュボードのインシデントMO502273によると、暫定的な根本原因は「広域ネットワーク (WAN) のルーティング変更 (その結果、ユーザが複数のMicrosoft365サービスにアクセスできなくなった)」と特定されています。
Microsoftは根本的な原因を追求
ワシントン州レドモンドに本社を構えるMicrosoftは27日、根本的な原因について、1台のルータのIPアドレスが変更され、WAN内の他のすべてのルータ間でパケット転送の問題が発生したことが原因であると詳しく説明しました。
「WANルータのIPアドレスを更新するために計画された変更の一環として、ルータに与えられたコマンドが、WAN内の他のすべてのルータにメッセージを送信させ、その結果、すべてのルータが隣接テーブルと転送テーブルを再計算してしまいました」 と、Microsoftは述べました。
「この再計算の間、ルータはそれらを通過するパケットを正しく転送することができませんでした」ということです。
この変更は計画的なものでしたが、ルータに与えられた「コマンド」は明らかにエラーであり、実際にコストがかかり、Microsoft Azureのサービスステータスページで共有されているように、約30分ごとにピークとなる波状攻撃を受けて、サービス全体に影響を与えました(このサービス自体にも影響があり「504 Gateway Time-out errors」と断続的に表示されました)。
Microsoftは、この問題のトラブルシューティングを行いながら、Twitterでユーザに情報を提供しました。
1月25日MSツイッター更新情報
その1時間後には、この問題を軽減するために変更を取り消しました。
その5時間後、Microsoftはほぼすべてのサービスが正常に戻ったと報告しました。
CatchpointのIPMプラットフォームによる即時検知
CatchpointのIPMプラットフォームは、Bing、Teams、Outlookの各アプリケーションにおいて、2023年1月25日 AM02:08(EST)に発生した問題をいち早く検知しました。
私たちのグローバルな観測ネットワークが継続的に拡大しているおかげで、世界中の接続の増加、待機時間、可用性の低下を観測することができたのです。
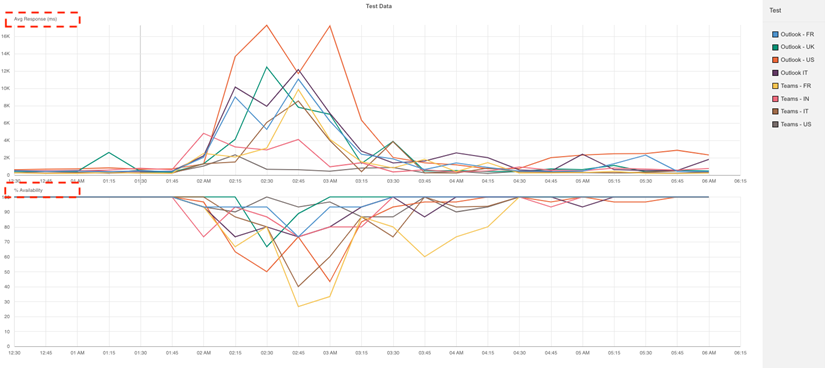
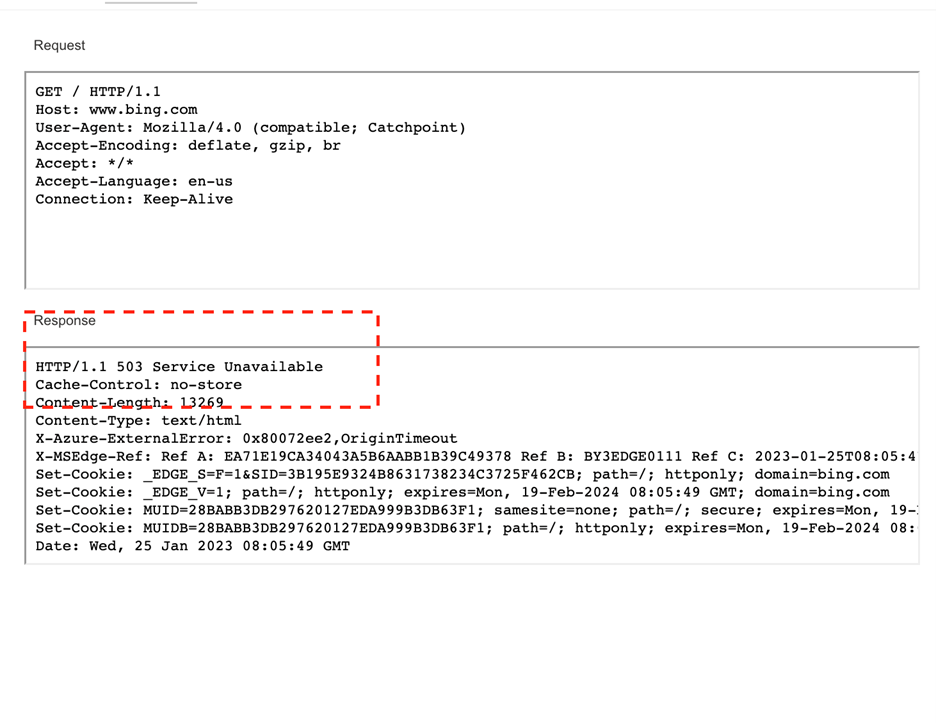
ユーザが最初に目にするエラーは503のステータスコードで、次にService Unavailable(サービス停止中)のエラーが表示されたはずです。
以下は、Catchpointのテストによるレスポンス・ヘッダで、Microsoftの検索エンジンであるBingに対して503 Service Unavailableエラーが発生したことを示しています。
米国とEMEA(ヨーロッパ、中東及びアフリカ)の大部分にとって幸運だったのは、この障害が発生したのが、まだ誰も仕事を始めていない早朝の時間帯であったことです。
しかし、Catchpointでは、多くのグローバル企業と同様、従業員の多くをインドに置いており(この日は昼過ぎでした)、従業員はMicrosoftの主要サービスが利用できないことに最初は困惑したと話しています。
あるエンジニアリング部門のQAマネージャは、Teamsが2時間半ほどほとんど使えず、同僚のステータスに「Status Unknown」と表示されて狼狽し、Teamsの通話から突然退出されて再接続できなくなったと報告しています。
しかし、IPMプラットフォームが検知したテレメトリを観測していた当社のマネージドサービスチームが障害発生のアラートを出すと、彼女はモバイル版のTeamsに切り替えて通話を再開することができたのです。
また、あるシステム管理者は、Outlookが動かなくなったことに気づきました。
メールも受信できないし、送ることもできませんでした(障害そのものに関するものも含まれているはずです)。
Catchpointが発掘したデータを知った彼も、世界的な障害であることを理解し、サービスが再開されるまで電源を切るのではなく、同僚と積極的に連絡を取り合い、サービスが正常化するまでの回避策を模索し始めました。
さて、ネットワーク面(とBGPデータのサポート)です!
私たちのテレメトリは、Microsoftの発表と一致しました。
しかし、それに加えて、BGPのデータはネットワークベースの調査の出発点として自然であり、Microsoftもネットワーク/WANの問題だと述べていたため、BGPのデータを掘り下げることにしました。
Catchpointでは、世界中に分散する50社以上のパートナーからBGPデータをリアルタイムで収集しており、その数は増え続けています。
いくつかのピアが集めたBGPイベントをざっと見ただけで、問題が発生した瞬間(そしておそらくMicrosoftの顧客が苦情を言い始めた瞬間)を正確に特定するのは簡単です。
以下のグラフでは、ピアセレクションで生成されたすべてのBGPアップデートを分析し、Microsoftが主に使用する5つのAS番号(ASN)のいずれかによってもともとアナウンスされたネットワークへのルートを伝えていることを確認しました。
.png)
ご覧の通り、AM02:08(EST/07:08 UTC)からBGPイベントが急増し、5つのASNそれぞれのルーティングアクティビティが急上昇していることがわかります。
これは、分析したすべてのピアで記録されています。
記録されたイベントのほとんどはネットワークのアナウンスでしたが、いくつかのネットワークの撤回も確認しました。
つまり、撤回したネットワークの背後で動いているサービスは、選択されたピアから、そしておそらく世界中のもっと多くの人々から到達できないことを意味しているのです。
それを確認するために、Catchpointが障害期間中に作成したテレメトリデータを再確認してみると、以下のウォーターフォールおよびサンキーチャートで見ることができるように、多くの接続タイムアウトが発生していることがわかります。

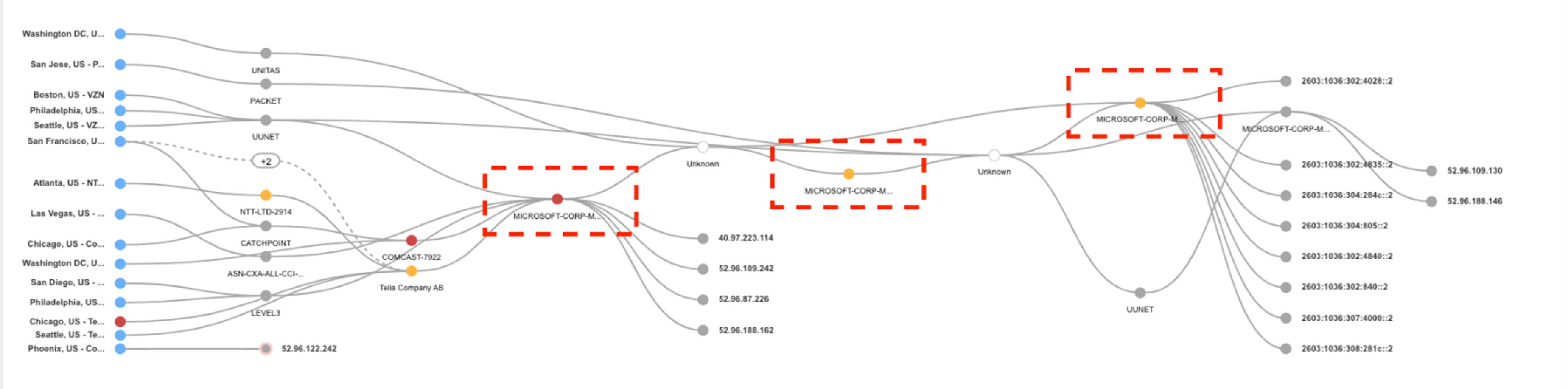
Synthetic Tracerouteのテストでは、Catchpointの従業員からMicrosoftまでのネットワークを継続的にアクティブに監視していました。
これにより、以下の3つのサンキーチャートで示されるように、障害の前後でグローバルに影響を追跡することができました。

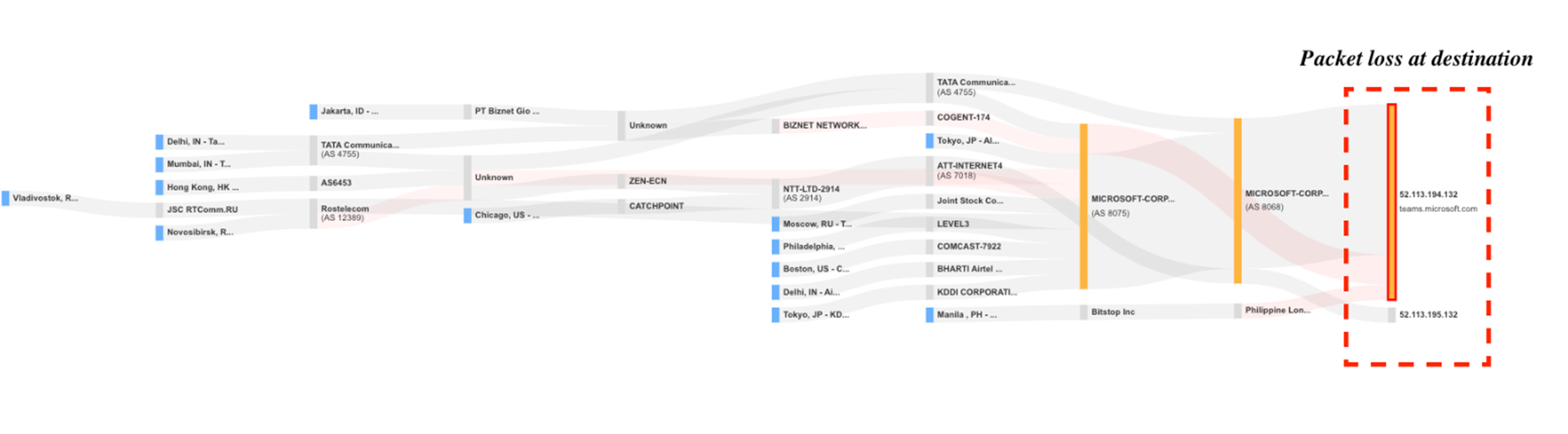
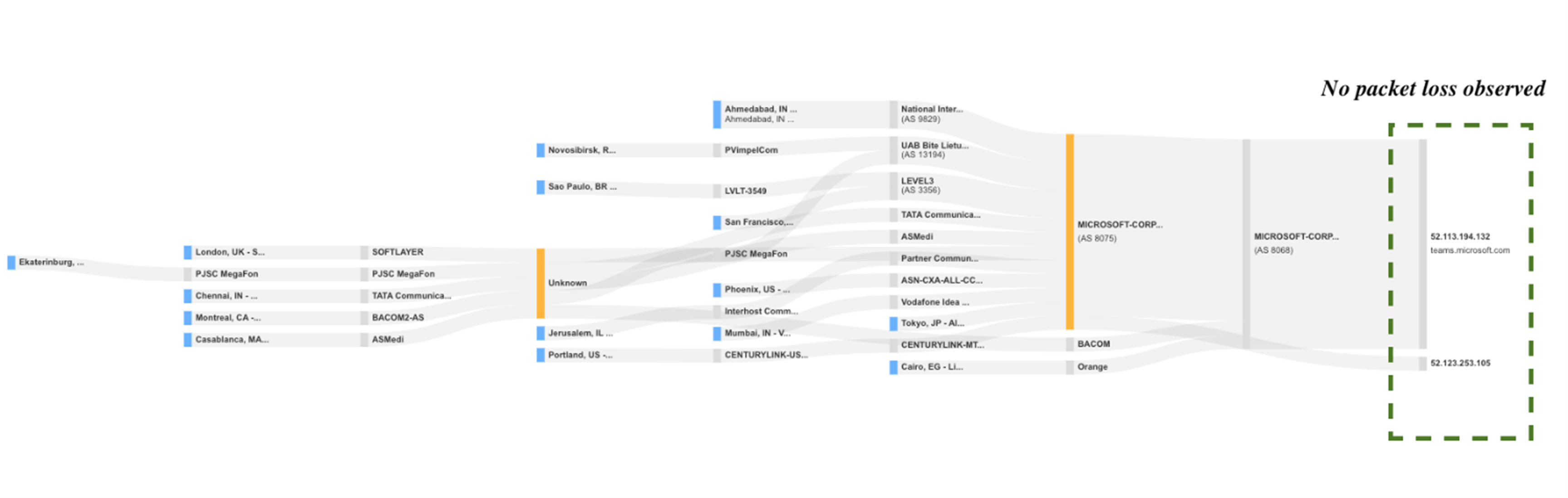
図1より、テストの失敗は接続のタイムアウトによるものであることが分かります。
ほとんどの監視ツールは、接続の問題があることを示すだけですが、Catchpointは、ご覧のように、ネットワークチームがどのレベルで問題が発生しているかを判断するのに役立ちます。
図2は、Microsoftが管理するホップでのグローバルなパケットロスを明確に示しています。
一方、図3から図5を見ると、障害発生前後ではパケットロスが発生していないのに対し、障害発生時には宛先IPのパケットロスが増加していることがわかります。
重大な障害発生時には、このような詳細な情報を得ることで、プレッシャーがかかるネットワークチームが、問題の根本原因を迅速に特定することができます。
今日の競争環境において、インスタントメッセージや電子メールの送信、重要な文書へのアクセスができないことで、従業員の生産性が停止するような事態は避けなければなりません。
また、このような障害が発生すると、分散勤務している従業員からヘルプデスクチームに状況把握のための電話が数百件かかってくることになります。
適切な監視ツールがなければ、ヘルプデスク・チームが自分たちの責任ではないことに気づき、従業員に明確な説明と回避策を提示するまでに、かなりの時間がかかるでしょう。
当初は、503エラーが接続タイムアウトエラーに変わるというパターンから、サービス障害に伴う変更で発生したネットワーク障害ではないかと疑っていました。
しかし、同じようなパターンは、ある場所でアプリケーションサービスを停止し、ユーザを別の場所にルーティングすることによって、あるポッド/データセンターから別のポッド/データセンターへトラフィックを移動する、ネットワークの変更を計画したときに発生します。
これが(Microsoftの最初の事後報告に基づくと)今回起こったことです。このため、テレメトリデータの分析が非常に重要なのです。
アーキテクチャを把握し、インシデント発生前と発生中に行われた変更によって生じた差異を評価します。
6つの重要なポイント
このような大規模な障害が発生した場合、その被害を軽減するためには、自身が障害が発生したサービスプロバイダなのか、その下流の不幸な被害者なのかによって、様々な方法があります。
6つのキーポイントをご紹介します。
1. コミュニケーション、コミュニケーション、コミュニケーション
障害が発生した場合、従業員や顧客にできるだけ早く状況を伝え、回避策を見つけられるように準備しておきましょう。
2. すべてのユーザにとって、迅速かつアクセスしやすい通信を実現する
誰もがTwitterにアクセスしたり、この例では、より詳細な注意事項が記載されたMicrosoftの管理ページにアクセスできるわけではありません。
当然のことながら、サービスプロバイダは、すべてのユーザが何が起こっているかを正確に把握し、自分のWi-FiやISPのせいにして、結果としてさらなる混乱(と不安)を経験しないように、コアサービスとは異なるインフラ上にあるダウンページに、人々をルーティングする必要があります。
3. サービスプロバイダとそれに依存する企業は、IPM戦略を導入する
これにより、世界中に分散する従業員や世界中の顧客が経験していることを24時間365日、正確に監視することができます。
4. コンテンツの配信に依存するインターネットスタック全体を監視する
DNS、CDN、ISP、BGP、TCP設定、SSL、その他のクラウドサービスなどを含みます。
たとえその多くが自分のコントロール外であると仮定したとしても、監視してください。
5. 変更計画の後に発生する可能性がある障害に備える
障害の主な原因は構成の変更であるため、変更が計画された場合は必ず、その後に発生する可能性のある障害に備える必要があります。
6. 準備、準備、準備
復旧の練習や作業手順書を作成することで、(意図的であるかどうかにかかわらず)起こりうる障害に対応できるようにします。
これには、コミュニケーション戦略やテンプレートを含むクライシスコール計画、第三者からの障害を軽減する計画、監視とオブザーバビリティのためのベストプラクティスアプローチなどを含みます。
Microsoftは、PIR(Post Incident Review)の中で、独自の重要なポイントを認めています。
どうすれば、このような事態を少なくし、影響を少なくすることができるのか?
- 影響の大きいコマンドが端末上で実行されることをブロック(完了済)
- デバイス上でのコマンド実行はすべて安全な変更ガイドラインに従うことを義務付ける予定(完了予定:2023年2月)
さらに詳しく
この1年半で痛感したのは、どんなに大きなサービスプロバイダでも、失敗することはあるということです。
MicrosoftからFacebookまで、インターネット界の巨人たちに失敗が相次ぎました。
Catchpointの専門家は、これらの6つのインシデントを深く掘り下げて分析し、新しいホワイトペーパーにまとめ、6つの重要な教訓を示しました。
Catchpointの「2023年の障害を防ぐ」ホワイトペーパーを今すぐ入手(登録不要)