
Traseroute InSession:より信頼性の高いネットワーク診断ツールを目指したCatchpointの努力
翻訳: 島田 麻里子
この記事は米Catchpoint Systems社のブログ記事「traceroute InSession: Catchpoint’s effort towards a more reliable network diagnostic tool.」の翻訳です。
Spelldataは、Catchpointの日本代理店です。
この記事は、Catchpoint Systemsの許可を得て、翻訳しています。
1988年に誕生して以来、tracerouteはいくつかのバリエーションを経てきました。
「なぜそんなにたくさんあるのか」と疑問に思われるかもしれません。
答えは簡単で、tracerouteの機能を実現するには、セキュリティとユーティリティのバランスが必要だったからです。
悪意ある者がファイアウォールやルーターの脆弱性を突くたびに、そのベンダーは修正と対策を追加し、これらがtracerouteのアルゴリズムに影響を及ぼしました。
結果として、これらのアルゴリズムは、ネットワークデバイスの変更に対応するために、若干異なる方法で動作するように修正されました。
これは現在のtracerouteにも当てはまります。
なぜなら、ファイアウォールや負荷分散ルーターにより、一部のIPに対してパケットロスの誤検出が生じる可能性があるからです。
ここから先、引用された研究論文では、これらをロードバランサー(負荷分散装置)と識別しています。
例えば、TCPを使用してbing.comに向けて標準的なtracerouteを実行すると、どのようなことが起こるか見てみましょう。
]$ sudo traceroute -T bing.com traceroute to bing.com (13.107.21.200), 30 hops max, 60 byte packets 1 192.168.2.1 (192.168.2.1) 0.237 ms 0.288 ms 0.282 ms 2 180.8.126.58 (180.8.126.58) 4.103 ms 180.8.126.66 (180.8.126.66) 4.759 ms 180.8.126.74 (180.8.126.74) 5.103 ms 3 180.8.126.101 (180.8.126.101) 4.893 ms 180.8.126.93 (180.8.126.93) 4.765 ms 180.8.126.77 (180.8.126.77) 5.063 ms 4 210.254.188.21 (210.254.188.21) 5.380 ms 5.273 ms 5.722 ms 5 60.37.54.166 (60.37.54.166) 14.329 ms 122.1.245.70 (122.1.245.70) 5.479 ms 60.37.54.162 (60.37.54.162) 5.703 ms 6 61.199.135.106 (61.199.135.106) 6.320 ms 61.199.135.94 (61.199.135.94) 5.592 ms 61.199.135.106 (61.199.135.106) 5.486 ms 7 13.104.186.83 (13.104.186.83) 5.609 ms 13.104.182.210 (13.104.182.210) 9.130 ms 13.104.186.85 (13.104.186.85) 6.795 ms 8 * * * 9 * 13.107.21.200 (13.107.21.200) 6.758 ms *
Catchpointのエンジニアたちは、数多くのRFC(インターネットのプロトコルと標準を定義する正式な文書)や研究論文を精査しました。
そして、この問題の解決策を見つけ出した後、それに効果的に対処するために、traceroute InSessionを構築しました。
これは新しいアプローチではありませんが、ネットワークエンジニアの重大なフラストレーションを解決する単一の機能的ツールです。
Catchpointのtraceroute InSessionをbing.comに実行すると、以下のようになります。
(もちろん、以下のリンク先のオープンソースコードでビルドしています)
$ sudo /opt/CatchPoint/Agent/Plugins/Native/Ping/centos.7-x86_64/CP_tr aceroute bing.com --tcpdata traceroute to bing.com (13.107.21.200), 30 hops max, 53 byte packets, overall timeout not set 1 192.168.2.1 (192.168.2.1) 0.154 ms 0.142 ms 0.140 ms D=0.151449 2 180.8.126.66 (180.8.126.66) 7.523 ms 5.196 ms 8.236 ms D=0.121180 3 180.8.126.69 (180.8.126.69) 4.541 ms 4.170 ms 6.149 ms D=0.091046 4 210.254.188.21 (210.254.188.21) 6.897 ms 6.536 ms 4.476 ms D=0.060790 5 122.1.245.70 (122.1.245.70) 5.752 ms 6.593 ms 5.266 ms D=0.030519 6 61.199.135.94 (61.199.135.94) 29.937 ms 19.745 ms 13.803 ms D=0.152267 7 * * * D=0.152154 8 * * * D=0.121709 9 * * * D=0.108900 10 * * * D=0.108898 11 13.107.21.200 (13.107.21.200) 9.499 ms 5.834 ms 7.377 ms D=0.043023 Timedout: false Duration: 392.302 ms DestinationReached: true MSS: 1420
この経路は、ホップでの変動が少なく、目的地ではパケットロスが発生していません。
なぜそうなるのかを理解するために、このブログ記事の続きを読んでください。
tracerouteの略歴
tracerouteは1988年12月20日にVan Jacobson氏によって作成されました。
彼は2012年に「インターネット殿堂」入りした、初めての受賞者の一人となりました。
彼の目的は、「パケットはどこへ行くのか」という厄介な問いに答えることでした。
私はホストへのルートを追跡するプログラムを作りました。
それはTTL(Time to Live)が1のUDP(User Datagram Protocol)パケットを送り、ICMP(Internet Control Message Protocol)の「時間超過」メッセージを受け取ることで動作します。
もしメッセージがあれば、そのICMPメッセージからの送信元アドレスを表示し、次にTTLを1つ増やします。
Van Jacobson氏
UDPプローブは、元々ICMPエコーリクエストよりも好まれていました。
これは、RFC792(Internet Control Message Protocol)の序文で述べられているように、当時、ルーターはICMP ECHOメッセージに対するICMP TTL超過メッセージの送信を正当に拒否することができたからです。
ICMPメッセージは通常、データグラムの処理でのエラーを報告します。
メッセージに関するメッセージ等の無限の回帰を避けるため、ICMPメッセージに関するICMPメッセージは送信されません。
従って、ICMPエコーメッセージはPingには適していますが、送信元から送信先までの経路を追跡するには適していなかったのです。
その後、RFC1122(インターネットホストの要件)により、その要件が緩和され、ICMPプローブを使用するtracerouteのバリエーションが誕生しました。
TCP tracerouteの導入
時代が進むにつれて、インターネット上の脅威や攻撃、そしてその結果としてファイアウォールが広まりました。
これらの防御メカニズムはインターネットをより安全にしましたが、同時にtracerouteを通して得られる結果にも影響を及ぼしました。
これは、一部のファイアウォールがICMPとUDPのプローブをフィルタリングする設定になっていたり、ICMPエコーパケットを優先順位を下げる設定になっていて、tracerouteが大量のパケットロスや高いRTTを持つ不完全なパスを表示するようになったためです。
これは、パケットフローにセキュリティルールを追加したルーターの設定が人工的に作り出したものです。
このため、2001年半ばにtcptracerouteが導入されました。
この新しいtracerouteはこの問題解決策を以下のようにして提示します。
多くの場合、これらのファイアウォールは、ファイアウォールの背後にあるホストが接続を待機している特定のポートに向けたTCPパケットを許可します。
と、tcptraceroute GitHubで述べられています。
UDPやICMPエコーパケットの代わりにTCP SYNパケットを送信することで、tcptracerouteは最も一般的なファイアウォール・フィルタを回避することができます。
それ以降、さまざまなグループが異なるオペレーティングシステム向けに複数のバージョンのtracerouteを構築し、維持してきました。
Windowsでは、tracertはICMPパケットのみを使用します。
対照的に、ほとんどのLinuxディストリビューションでは、2001年に初めて書かれ、現在もDmitry Butskoyによって維持されている「現代版」のtracerouteを確認することができます。
これは、UDP、ICMP、TCPプローブを使ったトレースをサポートしています。
これらのツールの他にも、パスの精度の向上(Paris traceroute)、NATの考慮(Dublin traceroute)、IPエイリアシングの考慮(Pamplona traceroute)などの特定の問題を解決するために、学会では様々なtraceroute技術が開発されました。
TCPプローブの問題点
しかし、tracerouteにTCPが導入しても、すべての問題が解決されたわけではありません。
tcptracerouteとButskoy氏のtracerouteは、どちらもよく知られたTCPハーフオープンの技法を使用しています。
具体的には、彼らはSYNパケットが目的地に到達し、通常はTCP RST(目的地のポートで何も聞いていない場合)または通常のTCP SYN+ACK(そこにある場合)の反応を引き起こすまで、ホップごとに増加するTTLでTCP SYNパケットを送信します。
また、ファイアウォールが何らかの理由でTCP SYNをドロップした場合、応答を受け取らないこともあり得ます。
これについては、後ほど説明します。
目的地がTCP SYN+ACKで応答すると、送信者はTCP RSTを生成し、TCPセッションが本当に確立されることはありません。
TCPセッションの開始を模倣することで、この手法は、選択した宛先ポートでアクティブなサービスが実行されている宛先(ポート80のWebサイトなど)でフィルタリングされる可能性が低くなります。
しかし、セキュリティの脅威が増大するにつれて、防御も強化され、最新のファイアウォールやNAT設定では、TCP sidecarの研究論文にあるように、SYNパケットをフラッド、ポートスキャン、または侵入試行と解釈する可能性があります。
これは、Butskoy氏のtracerouteのように、デフォルトで同時に16のプローブを送信するツールに特に当てはまります。
tracerouteの観点から見ると、これらの要因がすべて、宛先がパケットをドロップすることに繋がり、ユーザはパケットロスが発生し、従って問題が発生していると考えるようになります。
しかし、その宛先で実際に確立された任意のTCPセッションでは、実際のネットワーキングの問題は発生しません。
この問題のために、より多くのツールやアルゴリズムが開発されました。
Paratrace、TCP sidecar、0trace、Service tracerouteは、すでに確立されたTCPセッションの上にTCPプローブを乗せることで、さらに一歩踏み込んだ解決策を提供しています。
TCP sidecarの著者らは「TCP接続から送信されるプローブは、tracerouteの探索ができないファイアウォールやNATを通過し、それらを明らかにすることができる」と述べています。
このアプローチは素晴らしいものですが、根本的な制限があります。
それは、既に確立されたアクティブなTCPセッションが必要だということです。
camotraceが行うように、アプリケーションレベルのデータを送信するリモートエンドとのTCPセッションを意図的に開くことは可能です。
しかし、これはアプリケーションサーバによって処理されている実際のトラフィックを妨害することを意味し、tracerouteが伝統的に避けようとしていることです。
TCPハーフオープン技術に基づくtracerouteについては、さらなる注意点があります。
この技術で生成される各SYNパケットは、異なるTCPソースポートを使用します。
これは、パケットを異なるパスにルーティングするためにロードバランサーが使用するフィールドの一つです。
パケットが異なる経路を辿る場合、与えられたTTLで目的地に到達するのはその中の1つだけかもしれません。
これにより、tracerouteの最終ホップでは、ただ1つだけのRTT値が残り、他のパケットは消失します。
これは、パケットがロードバランサーによって失われたためであり、目的地への/目的地からのパケットのロスとは異なります。
Catchpointソリューション:traceroute InSession
ここでの課題は、アプリケーションサーバへの干渉を可能な限り少なくしながら、ルートを確定し、そのパフォーマンスを測定する信頼性の高い方法を見つけ、同時にファイヤーウォールにブロックされることを避けることでした。
信頼性の問題に対処するために、私たちは新たに車輪を発明することは選びませんでした。
代わりに、私たちは機能が豊富で既にLinuxコミュニティで人気のあるツール、Butskoyのtracerouteを強化しました。
Dmitryは、これまでに数年間にわたりツールの作成と改善に卓越した仕事をしており、彼のコードは理解しやすく、カスタマイズも容易です。
ファイヤーウォールをバイパスするために、私たちはTCPを活用することにしました。
これは、過去に研究者や開発者が特定したすべての理由からです。
しかし、Butskoyの方法とは異なり、私たちはソースから目的地までのTCPセッションを確立し、その上でtracerouteを行うことにしました。
この方法で、通過した任意のファイヤーウォールは、定期的にデータが流れる正常に確立されたTCPセッションを見ることになります。
このアプローチは、Paris tracerouteと同様に、ロードバランサーに対するある程度の保護も提供します。
この問題の最も困難な部分は、アプリケーションへの影響を最小限に抑えながら上記のすべてを達成することです。
理想的には、私たちのプローブで目的地に到達し、目的地からの応答を引き出し、TCPセッションを可能な限りアイドル状態で短命に保つことができるようにしたいのです。
これは部分的にはTCPの輻輳制御メカニズムを活用することで達成できます。
その考え方は、TCPがアプリケーションレベルに対して順序付けられたデータのみを配信し、シーケンス番号の流れにギャップが含まれているデータの塊は、そのギャップが埋められるまで配信されないという事実を利用するというものです。
ギャップが目的地によって特定されると、TCP ACKメッセージが生成され、再送信のための欠落したパケットのシーケンス番号を送信元に伝えます。
TCP Fast retransmit/Fast recovery輻輳制御メカニズムが適用されている場合、これは「TCP受信者は、順序が異なるセグメントが到着したときにすぐに重複ACKを送信するべきです」(RFC5681)という意味でもあるので、1つのプローブにつき1つのACKを受信することになります。
しかし、これだけでは十分ではありません。
目的地で生成されたTCP ACKはすべて同じシーケンス番号を含んでいますが、私たちは返信するTCPパケットを元のプローブにマッピングする方法が必要です。
これは重要なことで、Butskoyの実装は同時に複数のプローブを行う手法に基づいています。
これはtracerouteを非常に高速にする手法であり、私たちはこれを失いたくありませんでした。
その解決策として、私たちはtraceboxがTCPの輻輳制御メカニズムとSelective ACKnowledgment(SACK)オプションを利用していることに着想を得ました。
SACKは1996年にRFC2018(TCP Selective Acknowledgment Options)で導入されました。
SACKは、
データ受信者がデータ送信者に連続していないデータブロックが受信され、キューに入れられたことを通知するために送信されるオプションです。(中略) このオプションには、受信され、ウィンドウ内のキューに入れられたデータが占める連続したシーケンススペースのブロックの一部のリストが含まれます。
(RFC2018)
各ブロックには、目的地が受信した連続するシーケンス番号の範囲が含まれており、これは受信した最小のシーケンス番号(左端)とまだ受信していない最大のシーケンス番号(右端)で表現されます。
つまり、間隔を空けてシーケンス番号を増加させながらプローブを送信すると、宛先に到達したプローブごとに異なる間隔が発生することになります。
多くの場合、以下の画像のように、戻ってきたACKを元のプローブと簡単に照合させることができます。
しかし、これは常にそうなるわけではありません。
なぜなら、プローブは目的地に順序を無視して到達することがあり、間隔が離散的になることがあります。
これに対応するために、私たちはACKをその元のプローブに正確にマッピングするための独自のアルゴリズムを考案する必要がありました。
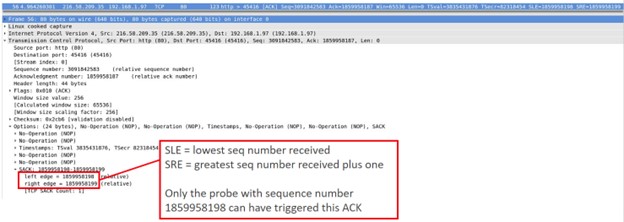
SRE(greatest seq number received plus one:受信した最大シーケンス番号に1を足したもの)が1859958199。
シーケンス番号1859958198のプローブのみが、このACKをトリガーできる
そこで考えたアルゴリズムが、tracerouteが終わるまで返ってくるACKを集めてサイズ順に並べ、間隔の内容を考慮しながらプローブを割り当てるというものです。
例えば、以下の画像に示されているように、6つのプローブが送信され、6つのACKが受信されて、それらがカバーする間隔の大きさによって順序付けられたシナリオを考えてみましょう。
このマッピングアルゴリズムは、SACKブロック[8-9]を持つACKを見て、ACKをプローブ8に直接マッピングします。
なぜなら、それがそのようなACKを引き起こすことができる唯一のプローブであるからです。
実際、右端(9)はまだ受信されていない最初のシーケンス番号を示していますが、左端はすでに受信された最初のシーケンス番号を示しています。
次に考慮されるACKは、間隔[4-5]、[8-9]を運ぶACKです。
プローブ8がすでに前のACKにマップされているので、このACKを引き起こした唯一のプローブは4であるということになります。
このアルゴリズムは、残りの受信したACKに対して同様の方法で進行し、目的地に到達したすべてのプローブを照合します。

(アルゴリズムがそう言っているだけでなく)
最後に一つ、注意点があります。
インターネット上のすべてのホストが、TCP Fast retransmit/Fast recovery 輻輳制御メカニズムを導入する必要があるわけではありません。
これは、TCP ACKが遅延する可能性があり、通常のパケットロスと遅延したTCP ACK(複数のプローブを含むSACK間隔を運んでいる)とを区別することが不可能になることを意味します。
これは下の画像で示されています。

この最終的な問題に対処するために、私たちは、最初に宛先に対する連続したTCP pingを実装して実行し、TCP pingで見つかった結果にtracerouteの最終ホップを置き換えることにしました。
プローブを順番に送信することで、宛先がACKを生成する時間を確保し、tracerouteに実際のパケットロスを特定する機能を提供します。
まとめると、新しいtraceroute InSessionは、ネットワーク関連のトラブルシューティングのために、以下の機能を提供します。
- セキュリティに関連するファイアウォールやルーターの設定によって生じる偽のパケットロスを防止します。
- パケットが単一のフローに従うことを保証し、ロードバランスされたルーターをバイパスするために、通常のTCPセッションに似たものにします。
- アプリケーションパケットトラフィックをシミュレートするためにTCPプロトコルを利用します。
- tracerouteの結果をできるだけ早く取得します
- 上記の利点と従来のtracerouteツールの全機能を組み合わせた単一のツールを提供します
traceroute InSessionは、2023年5月のEagleリリース以降、Catchpointポータルで利用できるようになりました。
Catchpointのお客様は、TCPとInSessionの定期的なtracerouteを実行して、tracerouteの2つの改良形の違いを理解することができるようになりました。
以下は、Catchpointのデータを使用した、Bing.comをターゲットにしたパケットロスの傾向の例です。
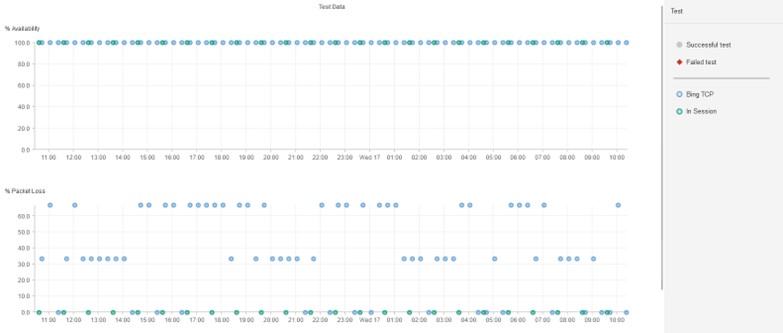
Catchpointの顧客でなくてもInSessionを利用することができます。
オリジナルの作者の理念に沿って、Dmitry Butskoy氏のtracerouteの強化バージョンをオープンソース化しました。
それはこちらで確認することができます。