
検知から解決までを加速:インターネット・レジリエンスのケーススタディ
翻訳: 島田 麻里子
この記事は米Catchpoint Systems社のブログ記事「Accelerating Detection to Resolution: A Case Study in Internet Resilience」の翻訳です。
Spelldataは、Catchpointの日本代理店です。
この記事は、Catchpoint Systemsの許可を得て、翻訳しています。
今日、収益を生み出すWebサイトはトランプで作った家のようなもので、複数の障害点によって崩壊する可能性があります。
現代のサービス・デリバリー・チェーンは、複雑なマルチステップ・トランザクションとサードパーティのAPI統合に依存しており、システムをより複雑で相互接続性の高いものにしています。
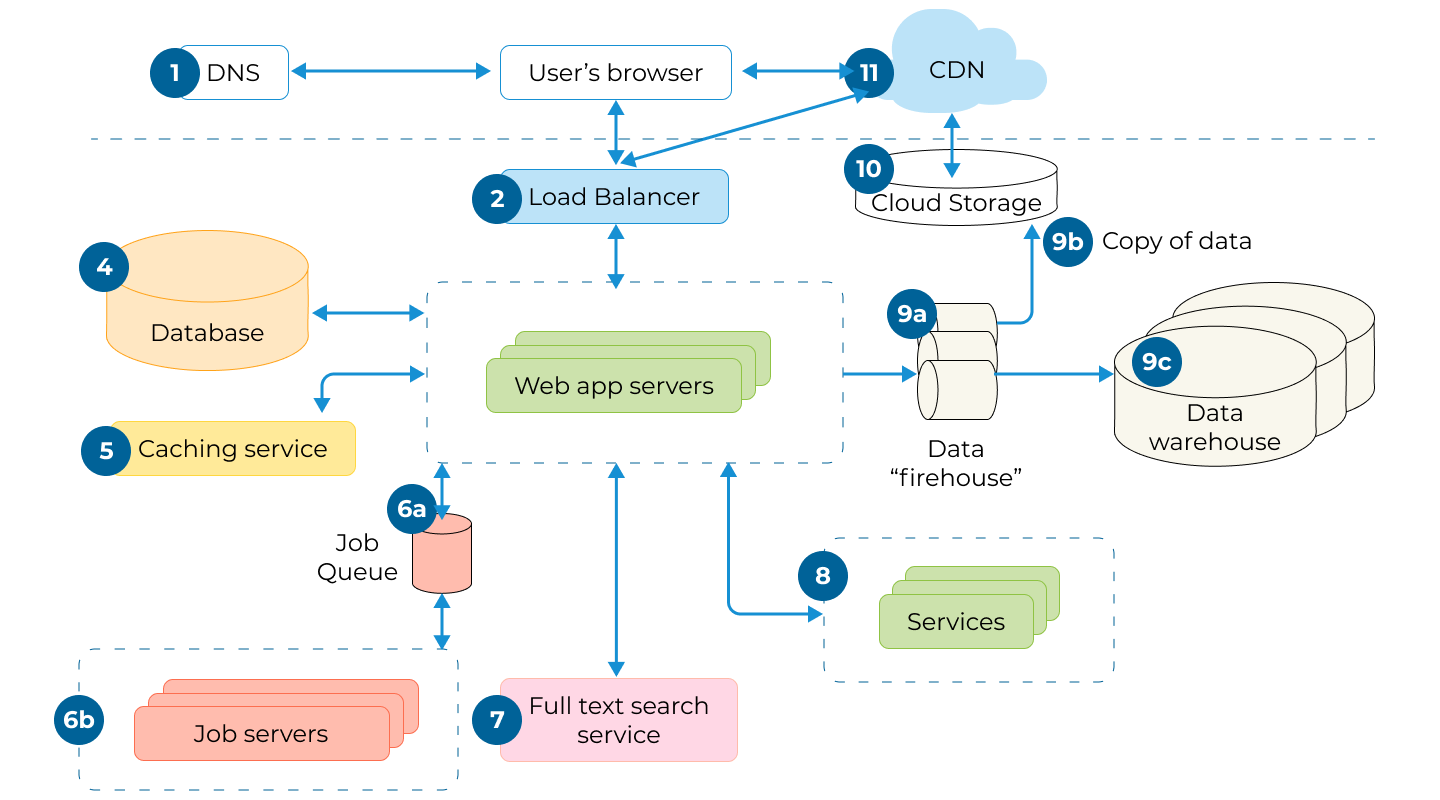
上のアーキテクチャ図における単一障害点は、収益に具体的な影響を及ぼす速度低下や障害につながる可能性があります。
そのため、インシデントの検出と解決にかかる時間を短縮することは、インターネットに依存するビジネスにとってミッションクリティカルな能力です。
障害コストの主な要因: MTTD、MTTI、MTTRの解明
障害コストに影響を与える主な要因は3つあります。
#1 MTTD ― 平均検出時間
MTTD(Mean Time to Detection)は、障害の原因となっているインシデントに気づく重要な瞬間を表します。
この段階は最も重要で、問題を迅速に特定できればできるほど、より早く解決に着手することができます。
#2 MTTI ― 平均識別時間
MTTI(平均検出時間)は次の重要なステップです。
これは障害の根本原因を特定することであり、見落とされがちなステップですが、同様に重要です。
迅速なMTTIは、障害の原因となっている特定のコンポーネントや問題をピンポイントで特定することで、解決プロセスを迅速化します。
#3 MTTR ― 平均解決時間
最後に、MTTR(Mean Time to Resolve:平均解決時間)は、インシデントが特定された後、そのインシデントに完全に対処し、解決するまでにかかる時間を表します。
このステップには、システムを通常のオペレーションに戻すために必要なすべてのアクションと対策が含まれます。
MTTRを短縮することで、ダウンタイムを最小限に抑え、ビジネスへの影響を最小限に抑えることができます。
例えば、DNSの障害を考えてみましょう。 問題はいくつも考えられます。
- すべてのネームサーバーがダウン
- DNSハイジャック
- いくつかのネームサーバーがダウン
- パフォーマンスの低下
- ネームサーバーの変更
特定のコンポーネントを特定することは非常に困難です。
このケーススタディでは、ある大手ハイテク企業がCatchpointを活用したプロアクティブな監視アプローチによって、インシデント対応時間とインターネット・レジリエンス全体を大幅に改善した事例を紹介します。
MTTR短縮のケーススタディ
問題点
同社は、eコマース・サイトを通じて販売する製品やサービスの一部について、大きな課題に直面していました。
この特定の事業グループは立ち上げたばかりで、監視システムを導入していませんでした。
彼らの姿勢は消極的で、購入が完了できないなどの問題が発生した場合、顧客からの連絡に頼ることが多くありました。
このアプローチでは、数百万ドルの収益損失が発生しました。
解決策
同社はすでにビジネスの他の側面でCatchpointを使用していましたが、新たに設立したeコマース・サイトにはサポートが必要でした。
Catchpoint は、インターネット・パフォーマンス・モニタリング (IPM) サービス一式を拡張し、同社のeコマース・プラットフォームをカバーしました。
このフレームワークの中で、障害を迅速に検出して対応することを目的としたテストを確立しました。
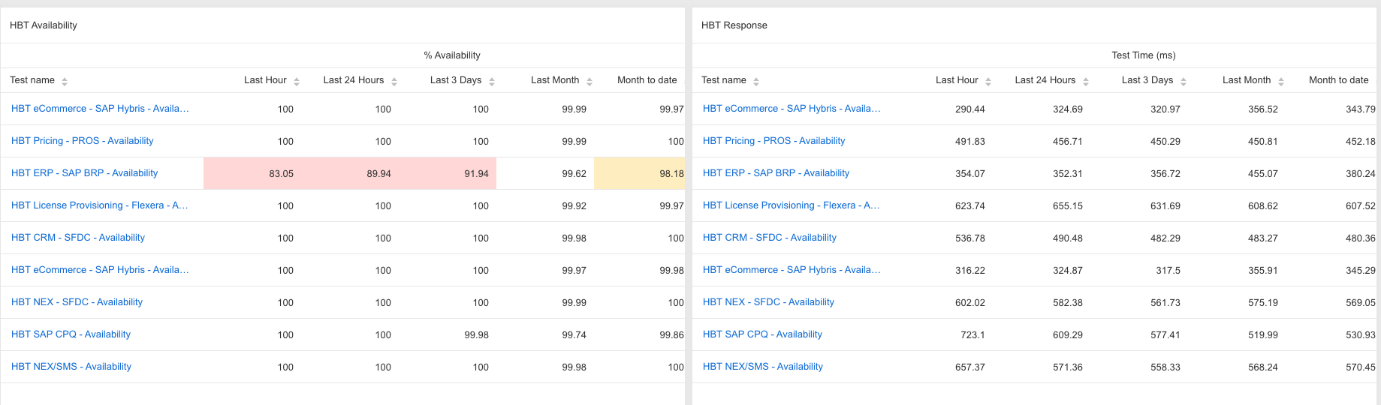

結果
その成果は極めて大きかったです。
テスト導入後、同社のMTTDは大幅に改善され、2~4時間かかっていたものがわずか5分に短縮されました。
また、リアルタイム・ダッシュボードを構成し、継続的な更新を提供しました。
これらのダッシュボードは即座にアラートを発し、各障害の性質と原因に関する正確な情報を提供します。
これらのアラートは関連チームに送られ、迅速な調査が可能になり、その結果、平均解決時間(MTTR)が8~10時間からわずか30分に短縮されました。
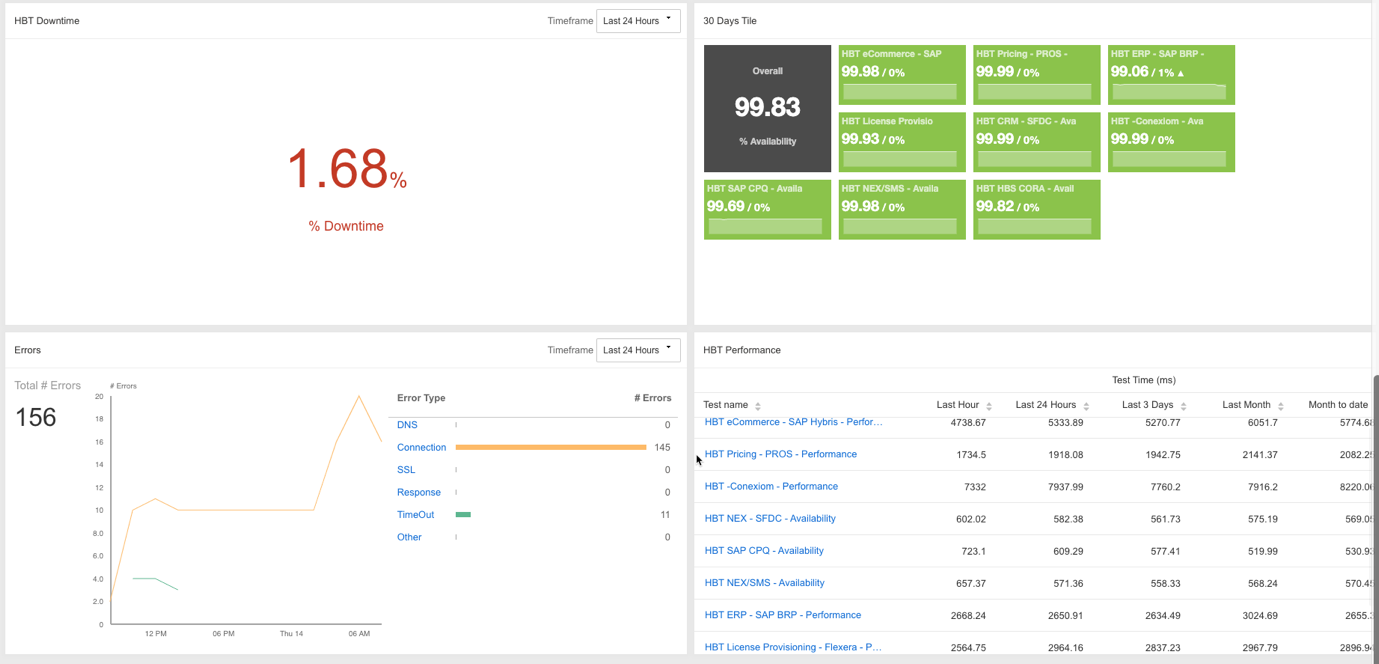
監視ツールがこの重要な情報を提供しない限り、トラブルシューティングに多くの時間を費やすことになり、苛立たしく、時間がかかります。
このような非効率性は、平均識別時間(MTTI)と平均解決時間(MTTR)の指標に直接影響します。
上記の例はDNSに関するものですが、システム内の他の多数のコンポーネントが障害を引き起こす可能性があり、それぞれに潜在的な障害原因があります。
MTTDとMTTRを削減するベストプラクティス
- 包括的な監視戦略
- あらゆるレベルでの可用性やパフォーマンスなど、ユーザ体験に影響を与えるあらゆる側面をカバーする強固な監視戦略を確立する。
- 最適なテスト構成
- テストを適切に構成し、最適な頻度で実行する。 可用性テストを頻繁に実行しないようにし、警告サインとクリティカルな問題を区別することで、偽陽性を最小化する戦略を策定する。
- データの活用
- 監視システムで収集したデータを最大限に活用する。 共有可能なリンクでカスタマイズされたリアルタイムダッシュボードを作成し、オブザーバビリティツールや、APMやTracingなどの監視スタックの他のコンポーネントとデータを統合する。
MTTDとMTTRを削減するための包括的な監視を確実にするためのチェックリスト
- すべての重要なページが利用可能で、到達可能であることを確認する。
- ユーザがトランザクションを完了できるよう、すべての重要な機能が正しく動作していることを確認する。
- ページのロード時間を監視し、許容範囲内であることを確認する。
- マイクロサービスが正しく機能し、最適なパフォーマンスであることを確認する。
- 高い頻度で監視を設定し、タイムリーな対応を促す。
- ユーザの視点と経験から監視する。
- サードパーティコンポーネントは、Webサイトの可用性とパフォーマンスに影響を与える可能性があるため、監視戦略に含める。
- 24時間365日の監視を維持し、問題が発生したらすぐに検知する。
CatchpointでMTTDとMTTRを削減
Catchpointは、40種類以上のテスト・タイプと、業界をリードするインシデント管理ツールとのシームレスな統合を提供し、インシデントの迅速な検出、特定、解決を促進します。
この合理化されたアプローチは、障害コストを大幅に削減します。
Catchpointの高度なアラート・メカニズムにより、自動化プロセスをカスタマイズするために不可欠なデータを送信することができ、最小限の人的介入で多くのインシデントを解決することができます。
さらに、インシデントを効果的に処理するために、プレイブックをアラートペイロードに組み込むことができます。
ガイド付きツアーをご覧ください。