
見えない依存関係、見える影響:Google Cloud障害からの教訓
著者:
Catchpoint Team
翻訳: 逆井 晶子
この記事は米Catchpoint Systems社のブログ記事「Invisible dependencies, visible impact: Lessons from the Google Cloud outage」の翻訳です。
Spelldataは、Catchpointの日本代理店です。
この記事は、Catchpoint Systemsの許可を得て、翻訳しています。
2025年6月12日。
インターネットの大半の人々には記憶に残らない日ですが、Google Cloudに依存している人々にとっては忘れられない日です。
数分足らずのうちに、日常的なクォータの変更が、世界的な混乱を引き起こしました。
APIは応答を停止し、ダッシュボードは依然として“正常”を示していました。
そして大陸を超えて、多くのチームが問題が自分たちの側なのか、Google側なのかを確認しようと奔走しました。
これはサイバー攻撃でも、データセンターの火災でもありませんでした。
Googleのインフラストラクチャ深くに埋もれた自動クォータ変更が原因で、デジタル世界全体に波紋を広げることになったのです。
これはGoogleだけの問題ではありませんでした。
どれほど巨大な存在であっても、停止する可能性があるという現実を突きつける出来事でした。
私たちが依存しているシステムは、非常に複雑に入り組み、見えにくい構造をしており、想像以上に脆弱です。
そして、ひとたび障害が発生すると、何が原因なのか、誰が責任を負うべきなのかさえ、即座には見えてこないのです。
この記事は単なる障害の話ではありません。
30分から1時間遅れて反映されるステータスページに依存していると見落としてしまう重要な兆候、リアルタイムで自律的に監視し即応できることがもたらす利点、そして、どれほど大規模なデジタル企業であっても「見えない状況を見通す力」が不可欠である理由について、本記事では掘り下げていきます。
何が起きたのか?
6月12日午後1時49分(米東部時間)、Google Cloudで深刻なサービス障害が発生しました。
引き金となったのは、GoogleのグローバルAPI管理システムで実行された自動クォータの更新であり、これが原因で広範囲にわたる503エラーと外部APIリクエストの失敗が発生しました。
障害は次第に連鎖しながら拡大し、Google Cloudの主要サービスや、その基盤となるインフラストラクチャ全体にも波及しました。
影響を受けたサービスには以下が含まれます
- Google Cloud Console、App Engine、Cloud DNS、Dataflow
- Identity and Access Management(IAM)、Pub/Sub、Dialogflow
- Apigee API Managementおよびその他のバックエンドサービス
- アメリカ、EMEA、APAC、アフリカにわたる30以上のGCP製品
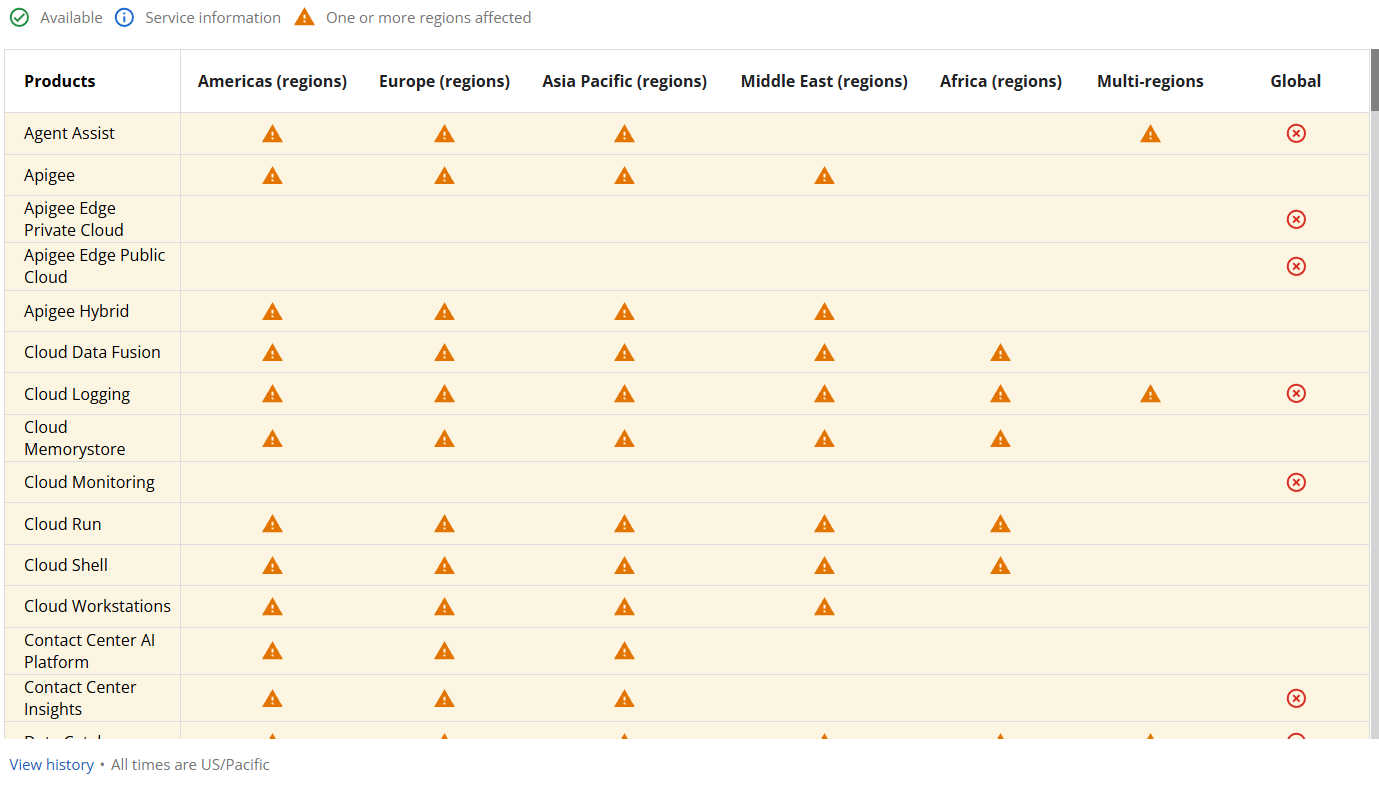
しかし、それだけでは終わりませんでした。
障害はDiscord、Spotify、Snapchat、Twitch、CloudflareといったGCPに依存する大手プラットフォームにも波及しました。
多くの地域では数時間以内に復旧が始まりましたが、us-central1ではクォータポリシーデータベースが過負荷となり、影響が午後まで続きました。
どのように検出されたのか?
午後1時50分(米東部時間)に、Catchpoint Internet SonarがGoogle DriveやApp Engineの異常を検出し始めました。
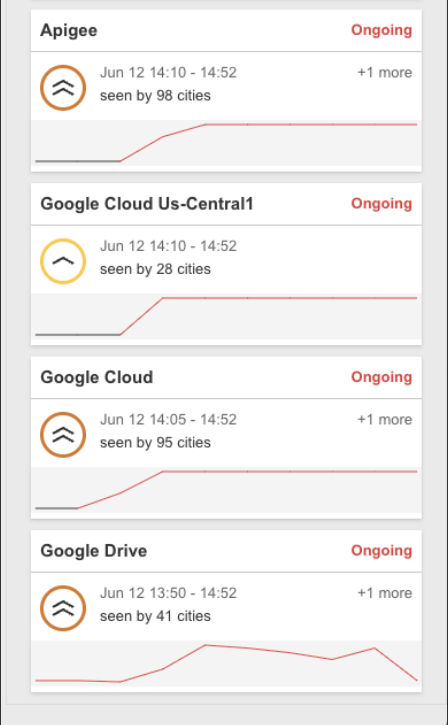
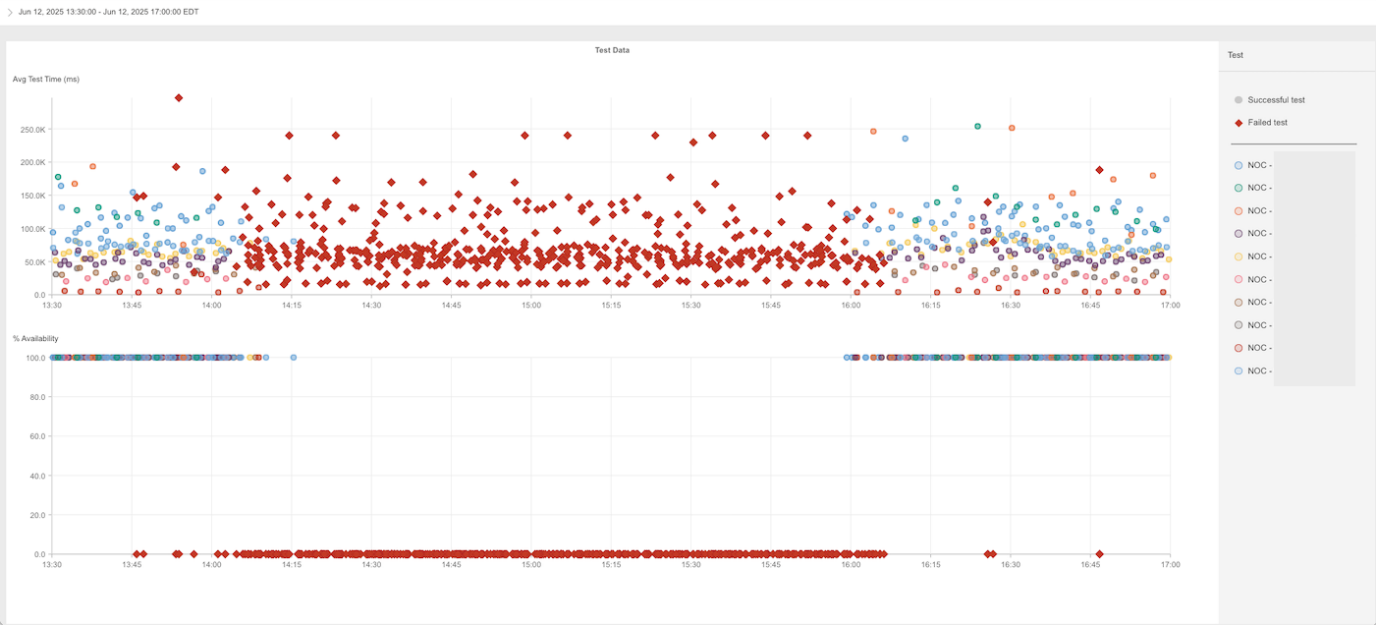
この時点でのテストでは、複数のワークフローで失敗のスパイクが確認されました。
それらの失敗は突発的でありながら継続的に発生し、複数のテスト種別にまたがって相関が確認され、広範な上流インフラストラクチャの障害の典型的な兆候を示していました。
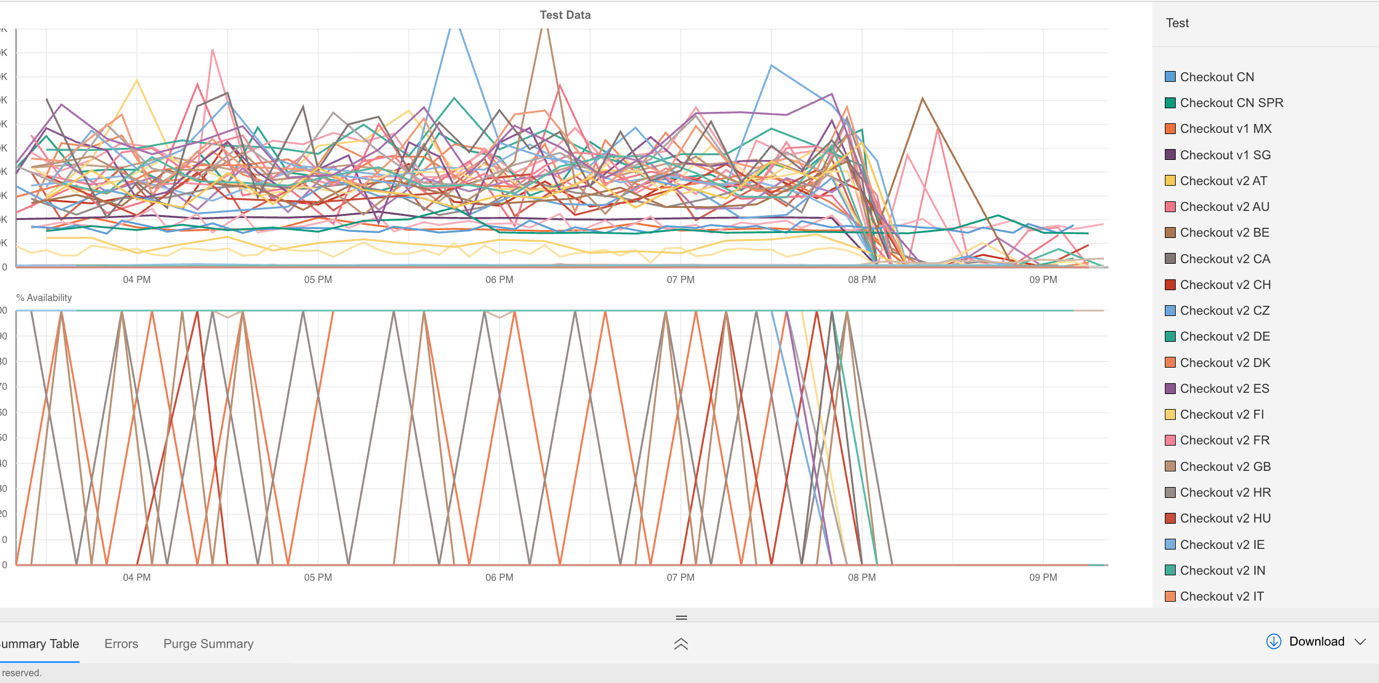
ユーザの一人が作成したグラフでは、可用性の急激な低下と、複数の国でチェックアウト処理が急増した様子が示されていました。
この結果から、ユーザ向けトランザクションへの影響が世界的に広がっていたことが確認されました。
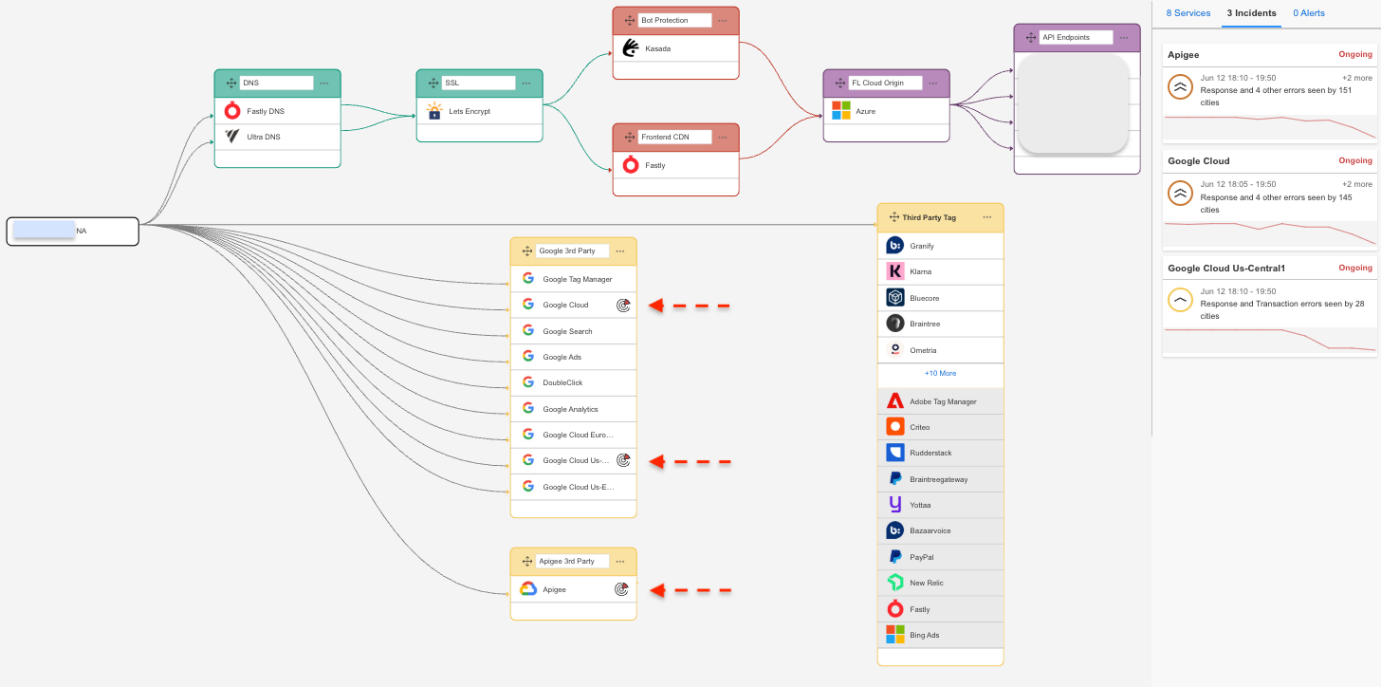
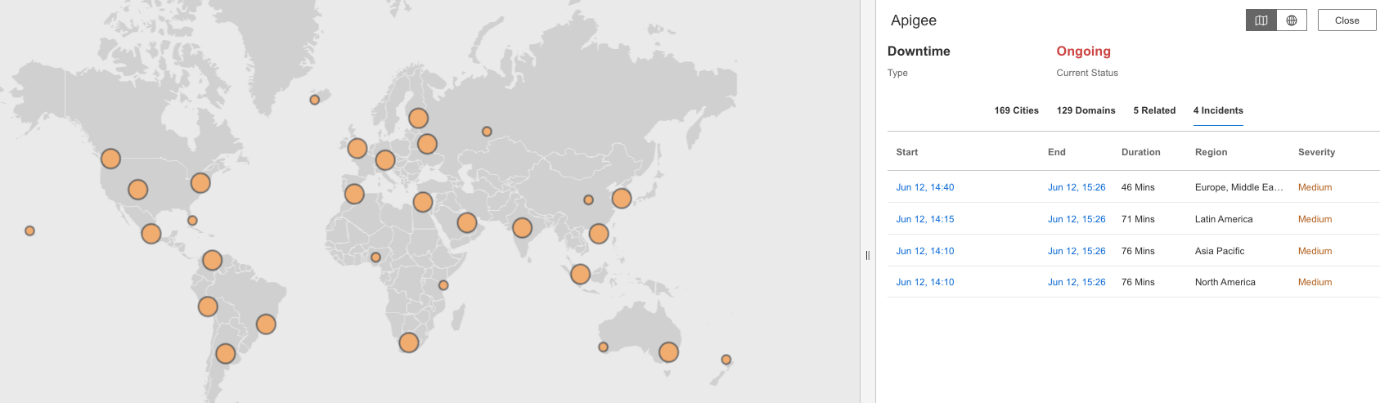
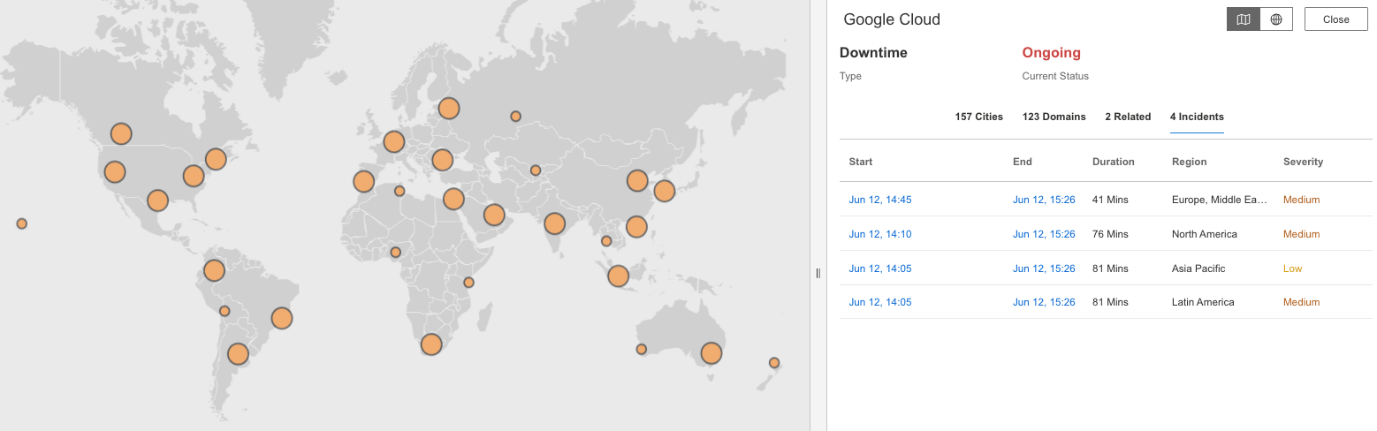
Internet Stack Mapでは、Google CloudとApigeeを中心に、サービス間の依存関係が断たれている様子が示されています。
分析、クラウドログ、ストレージ、認証など、複数のレイヤーが一斉に機能不全に陥りました。
これらの障害は、サードパーティツール、CDN、SaaS統合などにも直接影響しました。
このマップは、多くのチームが直面した現実を示しています。
1つのレイヤーが停止すると、それだけでは終わらないのです。
まだ公式発表はなかった
Syntheticテストとお客様データでは障害がリアルタイムで明らかになっていたにもかかわらず、Google Cloudが初めて公式に障害を認めたのは午後2時46分(米東部時間)であり、最初の異常発生から約1時間が経過していました。

その間、GCPのステータスページ上では“正常”を示す緑の表示が続いていました。
フロントラインのチーム(SRE、DevOps、カスタマーサポートなど)にとって、これは重要です。
「自分たちの問題か?」「ローカルな障害か?」「対応すべきか、待つべきか?」といった疑念を生むからです。
これはGoogleのインフラストラクチャを批判しているのではなく、大規模運用の現実を示しているのです。
ステータスページは多くの場合、障害の検知よりも後に位置づけられ、慎重さを重視して設計されているため、実際の影響が広がってから時間を置いてようやく更新されるのが実情です。
影響はどれほどだったのか?
影響は多岐にわたり、かつ複数のレイヤーにまたがっていました。
- GCPの直接の利用者
- 管理コンソールやAPI、ストレージ、認証といった中核的なインフラストラクチャへのアクセスができませんでした。
- SaaSおよびエンタープライズ向けプラットフォーム
- ユーザの主要な業務プロセスが2時間以上にわたって停止し、リアルタイムのテストデータでもトランザクションレベルでの障害が確認されました。
- 消費者向けサービス
- Discord、Snapchat、Twitch、Spotifyなどの一般消費者向けサービスでも、Googleサービスへの依存が原因で連鎖的なパフォーマンス低下が発生しました。
- 地理的な影響範囲
- 北米、EMEA、APAC、ラテンアメリカの各地域で障害が確認されました。
一見すると些細な構成変更が、クラウドサービスのみならず、その上に築かれていた信頼や機能までも崩壊させる結果となったのです。
主な教訓
この種の障害は、単にシステムを停止させるだけでなく、私たちが当然と考えていた前提を明るみに出します。
監視のあり方、情報共有の手段、そしてインシデントへの対応方法そのものが問われるのです。
今回のGoogle Cloudの障害から得られた主な教訓は、次のとおりです。
- #1 どんなに大きくても止まることはある
-
Googleのようなプロバイダでも、大規模障害を免れることはできません。
6月12日の出来事はそれを明確に示しました。
定例のクォータ更新がグローバルなダウンタイムへと発展し、すべてのデジタル企業に対して、依存関係がいかに脆弱であるかを思い知らせました。
これはタイムリーな警鐘です。
Googleのようなハイパースケーラーでさえ、大規模障害を免れません。
今日の相互接続されたデジタル世界では、Catchpointのような外部からの可観測性は“オプション”ではなく、“必須”です。
— Mehdi Daoudi(Catchpoint CEO兼共同創業者) - #2 ドミノ効果は現実である
-
Googleのようなハイパースケーラーで障害が発生すれば、その影響は彼らのシステムにとどまりません。
その上に構築されたSaaSプラットフォーム、サードパーティAPI、そしてそれらが提供するエンドユーザ体験すべてが巻き込まれます。
このインシデントは、たった1つの障害がいかに急速に広がり、一見無関係に見えるシステムにまで影響を及ぼすかを明らかにしました。
あなたのシステムは、最も脆弱なコンポーネントと同じだけの強度しかありません。
つまり、1つの依存関係がシステム全体をダウンさせる可能性があるということです。
たとえば、重要なAPIで使われている認証サービスがダウンすれば、他が正常でもあなたのシステムはダウンしているのです。
— Gerardo Dada(Catchpoint フィールドCTO) - #3 ステータスページだけでは不十分
-
プロバイダのダッシュボードには役割がありますが、リアルタイムのインシデント対応のために作られてはいません。
それらは慎重で正確、かつ慎重に設計されており、多くの場合、実際の影響に比べて情報が遅れて提供されます。
これは特定のプロバイダを非難するものではなく、大規模な運用における現実の反映です。
教訓は、ステータスページに多くを期待することではなく、自社の可視性にもっと期待することです。 - #4 レジリエンスを前提とした設計を
-
どんなに優れたプラットフォームでも、障害は発生します。
重要なのはすべての障害を回避することではなく、障害が起きたときに被害を最小限に抑えることです。
それには、障害が起きることを前提としたシステム設計が必要です。
リージョンをまたいだアーキテクチャの構築、プロバイダの多様化、実際に機能するフェイルオーバーの実装などが求められます。
Internet Sonarで分かったことの一つは、最先端のテクノロジーを持つ企業でも障害に見舞われるということです。
それは最良な企業にも起こり得ます。
だからこそ、“マルチ・マルチ”アーキテクチャがより重要になるのです。
— Matt Izzo(Catchpoint プロダクト担当VP) - #5 監視は監視対象と同じクラウドにあってはならない
-
このような障害は、不快ではあるものの「クラウドプロバイダがダウンしたとき、あなたの監視システムはまだ状況を把握できるのか?」という重要な問いを突きつけます。
多くの監視ツールは、監視対象であるクラウドインフラストラクチャ内のクラウドホスト型の観測ポイントに依存しています。
そのクラウドに障害が発生すれば、監視システムも影響を受け、機能が停止するおそれがあります。
ハイパースケーラー内にホストされたSyntheticテストは、実際のユーザ環境をほとんど反映しておらず、プロバイダ自身の内部的な障害を見落とす可能性があるのです。- クラウド内部のSyntheticテストでは、DNSエラー、CDNの障害、ISPレベルの障害など、現実の問題を見逃すことがあります。
- クラウドに依存したテストは「自己を自己で監視する」構造となり、誤った安心感を生みます。
真の可視性は、クラウドの外側―つまり実際のユーザが存在するインターネットの“エッジ”から得られます。
なぜなら、最も必要なときに監視が止まるようでは意味がないからです。
インターネットが不安定なときこそ、レジリエンスが問われます
6月12日の障害は、Google Cloudだけでなく、Cloudflare、CDN、業務プラットフォーム、AIツールにまで波及しました。
この出来事は、デジタルシステムがいかに深く相互依存し、つながっているかを鮮やかに示しました。
これらの障害は抽象的な問題ではなく、現実に影響を与えました。
たとえば、病院が患者の記録や薬のデータベースにアクセスできなくなったとしたら、それは単にランチが注文できないというレベルの話ではありません。
これは、最悪のタイミングで重要なサービスが停止するという、「生死」に関わる問題です。
Catchpointでは、この責任を真剣に受け止めています。
今回の障害時において
- 当社のInternet Performance Monitoring (IPM)プラットフォームは、障害発生中も一貫して稼働を維持しました。
- 当社の監視はクラウドに依存せず、外部から継続して行われていました。
- 一部のお客様ではサードパーティサービスへの接続に支障が見られましたが、Catchpoint自身の可視性と安定性は常に確保されていました。
私たちは、レジリエンス、透明性、可視性を徹底的に重視し、自社プラットフォームにとどまらず、お客様のビジネスを支えるインターネット全体に対して責任ある姿勢で取り組み続けます。
インパクトをもたらしたツールたち
Google Cloud障害に対応していたCatchpointのユーザには、2つの大きな強みがありました。
- Internet Sonar
- インターネットの主要サービスをリアルタイムかつ独立して監視し、サードパーティの問題を早期に検知し、その範囲を理解し、迅速に対応できます。
- Internet Stack Map
- 自社サービスの依存関係をライブで可視化し、連鎖的な障害の根本原因を迅速に特定できます。
次のインシデントに備え、Catchpointがどのように御社を支援できるか、ぜひ下記フォームよりお問い合わせください。