
可観測性はツールの問題ではありません。それは「真実」の問題です
著者:
Wasil Banday
翻訳: 逆井 晶子
この記事は米Catchpoint Systems社のブログ記事「Observability isn’t about the tool. It’s about the truth」の翻訳です。
Spelldataは、Catchpointの日本代理店です。
この記事は、Catchpoint Systemsの許可を得て、翻訳しています。
あるエンタープライズクライアントが遅延を報告しました。
あなたのダッシュボードにはすべて正常と表示されています。
クライアントはあなたを非難します。
あなたはクライアントを非難します。
しかし、どちらも証明することはできません。
これこそが、監視の取り組みがつまずく典型的なポイントです。
会話はしばしばダッシュボードやツールに終始し、本当に重要な真実には触れられません。
可観測性とは、メトリクスを収集したり、見た目が良いダッシュボードを作成したりすることではありません。
それは、「真実を知ること」、すなわち、評判や収益がかかっているときに、迅速に問題の根本にたどり着ける能力のことです。
虚栄心を満たす指標ではありません。
形式的に要件を満たすだけの機能でもありません。
ただ迅速で、エンドツーエンドで、否定できない「真実」です。
2つの企業が同じ問題を異なって捉えた場合、何が起きるでしょうか?
大手金融サービスプロバイダー(仮にCompany Aとしましょう)は突然、緊迫した状況に直面しました。
重要なエンタープライズクライアントであるCompany Bが、自社のお客様向けアプリに組み込まれたAPIで、3〜6秒の遅延が発生していると報告したのです。
- Company B:「あなたのAPIが遅いです。私たちのお客様体験に影響しています。」
- Company A(Datadog APMを使用中):「こちら側ではすべて正常です。」
結果として、膠着状態に陥りました。
まさに、可観測性が失敗している典型的なケースです。
Datadogが問題を発見できなかったのはなぜでしょうか?
これは、Datadogを非難するものではありません。
Datadogは優れたアプリケーションパフォーマンス監視(APM)ツールですが、自社インフラストラクチャの範囲外を可視化するために作られてはいないのです。
Company A は堅牢な APM とログ収集体制を持っていましたが、自社ネットワーク外の可視化については十分ではありませんでした。
Company Bのインフラストラクチャにエージェントをインストールすることも、他社のコードベースにReal User Monitoring(RUM)スクリプトを挿入することもできませんでした。
以下は、各ツールが「できること」と「できないこと」です
- APM(Datadogなど)
- アプリ内のトラフィックが到達してからの状況は把握可能
- RUM
- フロントエンドの洞察に優れるが、自社アプリのみが対象
- ログ
- すでに発生した事象には有用だが、パケットが転送中にどこで詰まったかはわからない
これら3つに共通して言えることは、いずれもシステム間で「何が起きているか」を可視化できないという点です。
なぜAPIは企業間の「死角」を生むのでしょうか?
APIは企業間のインターフェースであり、ソフトウェア界のウェイターのような存在です。
レストランでキッチンに入ってシェフに直接話しかけることがないように、企業同士もお互いのファイアウォールの裏側を覗くことはありません。
代わりに、定型化されたリクエストとレスポンスをAPIでやり取りし、相手側で何が起きているのかは見えないままです。
このようにして、死角が生まれてしまうのです。
2つのシステムがAPIを通じて通信する場合、互いの内部の動作に対する可視性がありません。
リクエストが自社の管理範囲を離れた時点で、それは「他人の問題」とされるブラックボックスへと移行します。
その先には、自分たちが所有も管理もしていないインフラストラクチャやネットワーク、さまざまな依存関係が存在しています。
根本的な問題は、「インターネットは観測可能ではない」という点です。
制御外のネットワークやインフラストラクチャにエージェントやRUMスクリプトをデプロイすることはできません。
そのため、従来の可観測性ツールではネットワークの外側までは可視化できません。
その先にあるのは「未知の領域」です。
しかし、優れたデジタル体験を提供するには、複数のネットワーク、プロトコル、エージェント、サブシステムが連携して機能する必要があります。
これらの依存関係は、インターネットスタックと呼ばれるものを構成します。
具体的には、DNS、CDN、BGP、ISP、ラストマイル、バックボーンなどが含まれます。
この連鎖のどこかでパフォーマンスが崩れれば、それが自分の責任かどうかに関係なく、お客様には影響が出ます。
結局のところ、APIは「可視性」ではなく「効率性」のために設計されたものだからです。
ここで、Internet Performance Monitoring(IPM)が必要不可欠になります。
IPMは、サービスに影響を及ぼすインターネットのすべての層を詳細に可視化します。
IPMは「インターネットスタック向けのAPM」と考えてください。
つまり、自分では所有していないものの、サービス提供に不可欠なシステムを監視するために特化して設計されたものです。
APMが不十分なとき、どのように「真実」にたどり着くのでしょうか?
従来の可観測性ツールで遅延の原因を説明できなかった部分を、IPM が補いました。
推測ではなく、Company AはIPMを使って実際のネットワーク環境でAPIのsyntheticテストを実行しました。
- ユーザのISP(米国の主要キャリアや光回線プロバイダ)から
- バックボーンおよびエンタープライズの視点から
- Company A自身のインフラストラクチャ内部から
各テストは実際のAPI呼び出しをシミュレートし、トレース可能なリクエストIDとタイムスタンプを含んでいました。
その結果は、否定できないものでした。
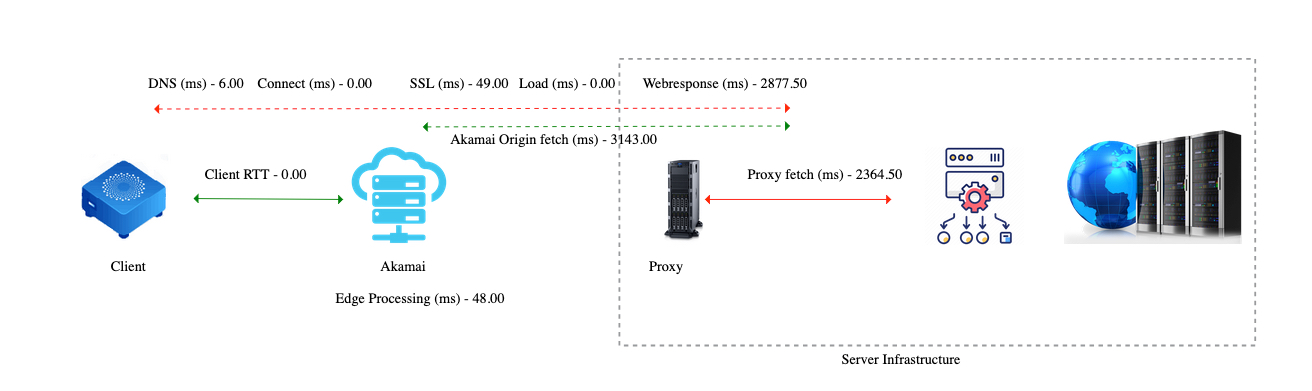
この図は、クライアントからAkamaiを通り、社内のプロキシインフラストラクチャや上流システムへ至るまでの API 呼び出しの全経路を示しています。
どの区間で遅延が発生しているのかが一目でわかる構成になっています。
- DNS、接続、SSLの時間は無視できる程度
- Akamaiのエッジ処理は高速(約48ミリ秒)
- 大きな遅延は、オリジンフェッチ(3,143ミリ秒)とプロキシフェッチ(2,364ミリ秒)で発生 — どちらもサーバ内部
- これは、問題がクライアントやCDNではなく、バックエンドの奥深くにあることを示しています。
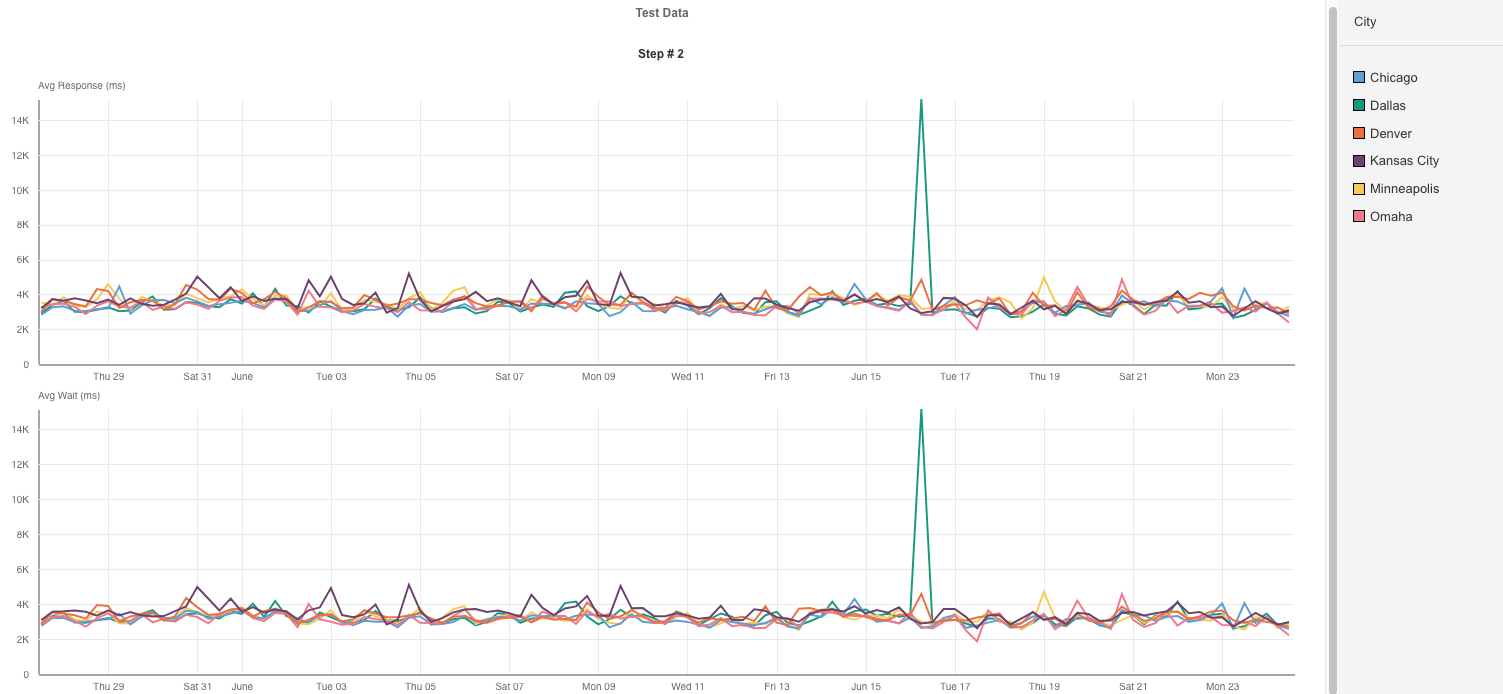
このチャートは、米国の主要都市ごとの平均レスポンスタイムと待機時間を追跡しています。
重要な洞察は以下のとおりです。
- 地理的に見てもレイテンシパターンは非常に一貫している
- 特定の地域だけでなく複数地域でスパイクが同時に発生しており、場所に依存する問題ではないことが明らか
- ボトルネックが外部ネットワークではなく、オリジンインフラストラクチャ内部にあることを裏付ける結果

ここでは、ISPごとのパフォーマンスが分析されています(例:AT&T、Comcast、Verizon)
- 多少のノイズはあるものの、全体的に各プロバイダでパフォーマンスは安定している
- 特定のISPだけが一貫して悪いということはない
- AT&Tの一時的なスパイクも、都市レベルのデータと同じタイミングで発生している
その結果、3〜6秒のレイテンシが、内部・外部ともに一貫して確認されました。
得られた情報により、疑わしい要因を順に切り分けることができました。
- ISPではなかった
- CDNでもなかった
- DNSでもなかった
- プロキシ(Envoy)でもなかった
これは、論理的な診断手法として非常に効果的でした。
システムの各レイヤーを順に検証し、問題のない部分を除外していくことで、真の原因に近づいていきます。
たとえば x-envoy-upstream-service-time といったレスポンスヘッダを読み解くことで、遅延が Company A のサービス環境の奥深くで発生していることが判明しました。
エンジニアたちは大量のログを手作業で精査する必要がなくなり、効率的に原因究明へ進めるようになりました。
さらに、トレース ID とタイムスタンプを突き合わせることで、最終的にはアプリケーションの依存関係に起因する不具合が特定されています。
初期準備と検証を含めた一連の工程は、わずか 3 時間・約 15 回のテストで全容を把握するに至りました。
必要だったのは推測ではなく、明確な根拠でした。
内部で原因が確認された時点で、チームは改善作業へ移行しています。
作業は現在も継続中ですが、すでに主要な指標では改善傾向が見られています。
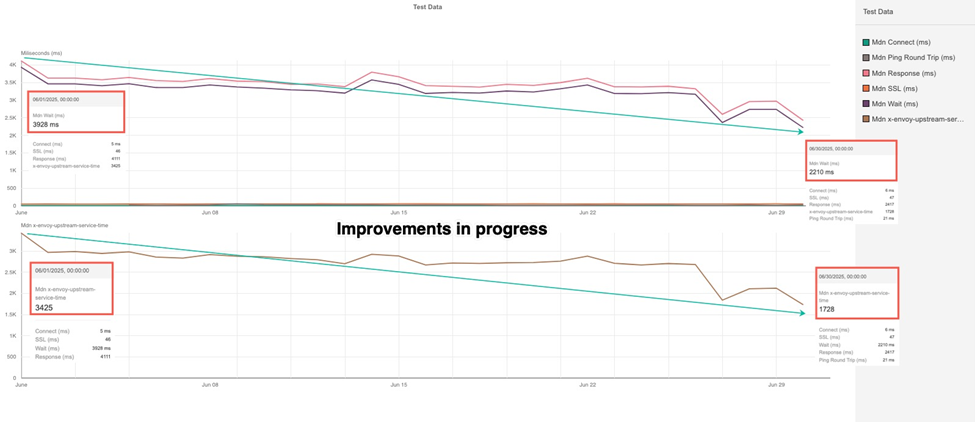
バックエンドのレイテンシは大幅に低下しました。
上流サービス(バックエンドの処理システム)の応答時間も、全体の待機時間も、ほぼ半分に短縮されました。
これらの成果は、最適化の取り組みが着実に実を結んでいることを示しています。
IPMが提供するもの、APMにはできないこと
はっきりさせておきましょう。
Datadog、New Relic、Dynatraceはいずれも、自社インフラストラクチャ内における監視という点では非常に優れたツールです。
しかし、インターネットそのものを監視するようには設計されていません。
Catchpoint IPMは、そのために設計されています。
以下のような特徴を持っています。
- 広大なグローバルエージェントネットワーク
-
- ラストマイル、バックボーン、クラウド、エンタープライズ、オンプレミスにまたがる3000以上のエージェント
- クラウド限定のテスト環境ではなく、実際のユーザネットワークをエミュレート
- 完全なシンセティックカバレッジ
-
- HTTP/S、API、ブラウザ、DNS、SSL、BGP、MQTT、QUIC、カスタムスクリプト対応
- 高度な診断機能
-
- パケットロス、ジッタ、経路トレース、ホップ分析
- 地域ごとのパフォーマンス低下を検知可能
- フロントエンドの可視性
-
- WebPageTestによる詳細なフロントエンドパフォーマンス分析
- フロントエンド計測が可能なチーム向けの、ブラウザおよびモバイル対応の RUM SDK
- シームレスな統合性
-
- Datadog、Splunk、New Relic、Dynatraceへ直接フィード可能
- 既存基盤のまま実現する機能拡張
- インターネットスタック全体のリアルタイム依存関係マップを通じて、エンドツーエンドの可視性を提供
なぜチームは、目的に合わないツールを使い続けるのでしょうか?
馴染みのあるツールは安心感をもたらします。
すでに導入されていて、広く理解されており、社内での摩擦も起きにくいからです。
しかし多くの場合、能力よりも「安心感」が優先されてしまいます。
特に、大規模で成熟した組織では、ツール選定が「目的適合性」ではなく「惰性」で決まってしまうことが少なくありません。
けれども、秒単位で結果が問われ、お客様に影響が出るような状況では、必要なのは「安心感」ではなく「明快さ」です。
APIが遅いとき、誰が責任を取るのでしょうか?
今回のケースでは、Company BはCompany Aを非難しました。
Company AはCompany Bを非難しました。
しかし、どちらも証拠となるデータを持っていませんでした。
ユーザにとっては、技術的背景に関係なく、「動作が遅い」という印象だけが残りました。
エンドユーザは、API呼び出しが企業の境界をまたいでいることを知りません。
彼らが見ているのは、やり取りをしている「ブランド」だけです。
遅ければ、そのブランドが悪いと思われるのです。
だからこそ、パフォーマンス問題を迅速に解決することは、単なる技術的な衛生の問題ではなく、ビジネス関係やお客様の信頼を守るために必要なことなのです。
最後に:可観測性の“真の役割”とは?
可観測性の価値は、見た目の良さや高額なベンダー契約にはありません。
本当に重要なのは、どれだけ早く「真実」に到達できるかという一点です。
そして、その「真実」は往々にして、自社の視界の外に存在します。
AI が意思決定を担う世界では、データがその判断を左右します。
しかし、もしそのデータが不完全だったり、自社インフラストラクチャから得られるテレメトリに限定されている場合、AI は「判断」ではなく 単なる“推測” をしているにすぎません。
Catchpoint IPM は、チームに次の力を提供します。
- 自社の外側からシステムを評価する力
- 社内で立てた仮説を、外部データで検証・反証する力
- 原因を“日単位”ではなく“分単位”で突き止める力
なぜなら、可観測性の本質とは、ツールの多さではなく、いかに素早く「真実」へたどり着けるか にあるからです。
お使いのツールで解決できないレイテンシの問題にお困りではありませんか?
ぜひ下記フォームよりご相談ください。