
セマンティックキャッシング:測定結果とその重要性
著者: Rahul Raj
翻訳: 逆井 晶子
この記事は米Catchpoint Systems社のブログ記事「Semantic Caching: What We Measured, Why It Matters」の翻訳です。
Spelldataは、Catchpointの日本代理店です。
この記事は、Catchpoint Systemsの許可を得て、翻訳しています。
概要
セマンティックキャッシングは、意味の近いクエリに対して過去の結果を再利用することで、AIシステムの応答を高速化し、コストを削減する技術です。
しかし、ユーザーの言い回しの違いやモデルのアップデート、そして時間とともにベクトル表現が少しずつ変化する「ベクタードリフト」によって、キャッシュが正しく機能しなくなることがあります。
このようなログに現れない問題が起こると、応答時間やコストが予想以上に増加してしまいます。
私たちのテスト環境では、たった1回のキャッシュミスで応答が2.5倍も遅くなるケースが確認されました。
本記事では、エージェント型AIにおけるセマンティックキャッシングの重要性と、見えにくい失敗の要因、監視と改善の方法について解説します。
セマンティックキャッシングは、重複した大規模言語モデル(LLM)への呼び出しを削減することで、AIシステムをより高速かつ安価にすることを約束します。
しかし、期待通りに機能しなかった場合はどうなるでしょうか?
私たちはそれを調べるためにテスト環境を構築しました。
セマンティックキャッシングシステムを用いて、意味的に類似したクエリがどのように処理されるのかを評価しています。
キャッシュが有効に働いた場合、応答時間は大幅に短縮されました。
一方で、キャッシュが機能しなかった場合には、処理コストが急激に増加する結果となりました。
実際、たった1回のセマンティックキャッシュミスによって、応答が通常の2.5倍以上も遅延するケースが確認されています。
こうした失敗はAPIログ上には記録されず、表面化しませんが、裏では確実に時間とコストの損失が発生していました。
このブログでは、セマンティックキャッシングの重要性、その失敗要因、そしてそれを効果的に監視する方法について共有します。
セマンティックキャッシングとは?
従来のキャッシングは、完全一致に基づいて応答を保存します。
同じ質問を以前に(一語一句同じように)したことがあれば、キャッシュから迅速な応答を得られます。
しかし、少しでも言い回しが違うと、それは全く新しいリクエストとして扱われます。
セマンティックキャッシングは異なります。
テキストではなく意味によってマッチングを行います。
「埋め込み」と呼ばれる数値表現を用いて、クエリの意図を把握し、新しいリクエストが過去のものとどれだけ似ているかを判断します。
2つのクエリが意味的に類似していれば、LLMで再処理することなく同じ結果を返すことができます。
これは、ユーザーが同じことを何通りもの方法で尋ねるAIシステムにおいて特に有用です。
セマンティックキャッシングにより、「Who’s the President of the US?(アメリカの大統領は誰?)」と「Who runs America?(アメリカを動かしているのは誰?)」が同じキャッシュされた応答を引き出すことができ、時間、計算資源、コストを節約できます。
エージェント型AIシステムにおけるセマンティックキャッシングの重要性
エージェント型AIシステムは、単に命令に応答するだけでなく、複数のステップにわたって計画、推論、行動を行います。
これらの各ステップは、しばしばLLMの呼び出しを含みます。
ドキュメントの取得、応答の言い換え、次に何をすべきかの判断などです。
問題は?
LLMの呼び出しは高コストであり、同じ質問のバリエーションに対して繰り返されると特にコストがかかります。
クエリのバリエーションをすべて再処理する代わりに、意味的に近い過去のリクエストの結果を再利用できます。
ここにリスクがあります。
エージェント型AIにおいては、セマンティックキャッシュの見えない失敗が、単なるAPIコールの遅延にとどまらず、マルチステップで構成されたAIワークフロー全体に悪影響を及ぼす可能性があります。
セマンティックキャッシュミスが発生すると、クエリは直接バックエンドのLLMに送られ、レイテンシーが高まり、コストが急上昇します。
加えて、これらの失敗は多くの場合、ログやシステム上では検知されません。
APIは200 OKを返しますが、裏ではコストとパフォーマンスに影響を与えているのです。
重要なポイント
従来のキャッシュとは異なり、セマンティックキャッシュには新たなリスクが伴います。
- モデルの突然の更新により、埋め込みが変わりマッチしなくなる。
- ベクタードリフトにより、類似したクエリでもキャッシュミスが発生する。
- ユーザーの言い回しの違いにより、予期せぬミスが生じる。
私たちのラボで観察したこと
セマンティックキャッシングがユーザー体験およびインフラストラクチャコストにどのような影響を与えるかを検証するため、私たちはローカルにテスト用のラボ環境を構築しました。
以下に、その構成と動作の流れを示します。
- FastAPI アプリケーションをローカルで作成し、
/searchエンドポイントを公開して外部アクセスを可能にしました。 - 受信した検索クエリは、以下のロジックで処理されます。
- Cosmos DB を参照し、クエリテキストをキーに、類似するセマンティッククエリが既に存在するかを確認します。
- ✅ キャッシュヒットの場合
- キャッシュされたベクトル埋め込みを直接返し、時間とコストを削減します。
- ❌ キャッシュミスの場合
- Gemini Pro を呼び出して新たなベクトル埋め込みを生成し、それを Cosmos DB に保存して今後の再利用に備えます。
- Azure AI Search にベクトルを送信し、ベクトル検索で最も関連性の高いドキュメントを取得します。
- 最終的に、検索結果とともに、以下の2つのカスタムHTTPヘッダーを送信します。
X-Semantic-Cache:- キャッシュヒットかミスかを示します。
X-Semantic-Score:- 新しいクエリと過去のクエリとの意味的な類似度を示します(例:0.8543)。
テスト結果
Catchpointテストを設定し、ユーザーのクエリを再現して公開エンドポイントに送信しました。
このテストでは、以下の3つの観点で検証を行いました。
- 「NYC weather」「New York forecast」など、キャッシュヒットとミスの両方を引き起こすランダムプロンプトの送信。
- Catchpointでセマンティックヘッダーを解析し、以下を追跡。
- キャッシュ効率(ヒット率とミス率)
- セマンティック類似度スコア
- 収集したデータをダッシュボードで可視化し、ヒットとミスの間のレイテンシー差を確認。
これにより、セマンティックキャッシングが高コストなLLMバックエンドへのAPIコールをどれだけ削減し、応答時間をどのように改善するかについて、定量的な裏付けを得ることができました。
これらの洞察は、Catchpoint のInternet Performance Monitoring(IPM)ポータルで直接確認・測定可能です。
以下に、テストから得られた有用な知見をいくつか紹介します。
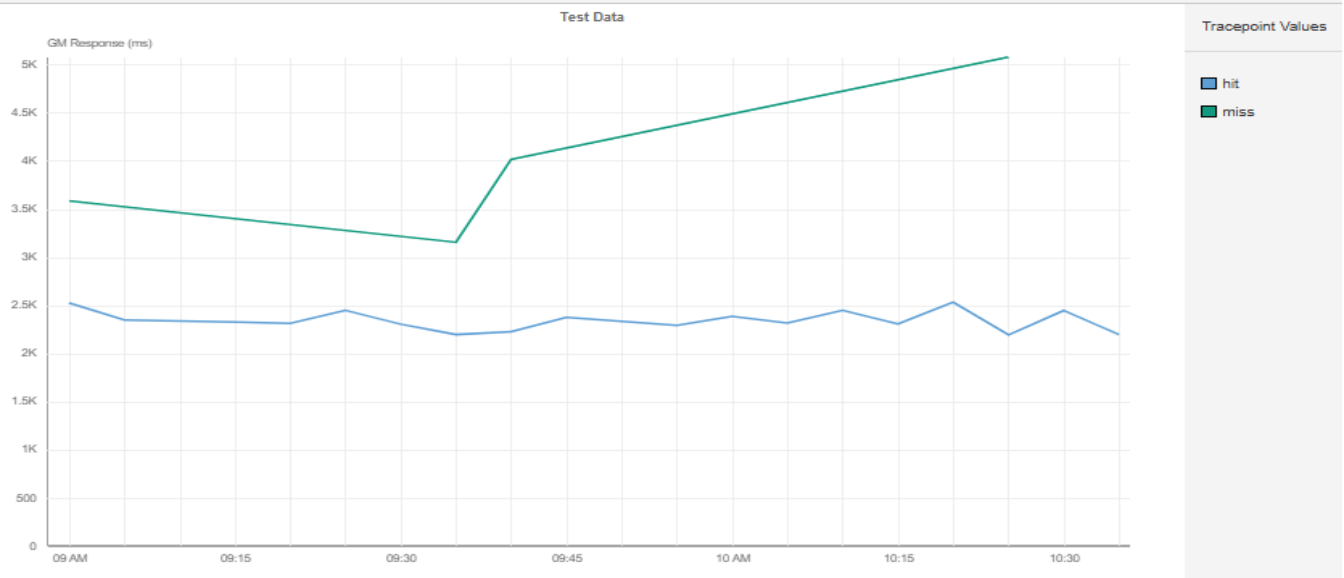
上記のグラフに示されているトレンドラインによると、セマンティックキャッシュがミスを返した場合、全体として応答時間がヒット時と比べて約50%〜250%高くなっていました。
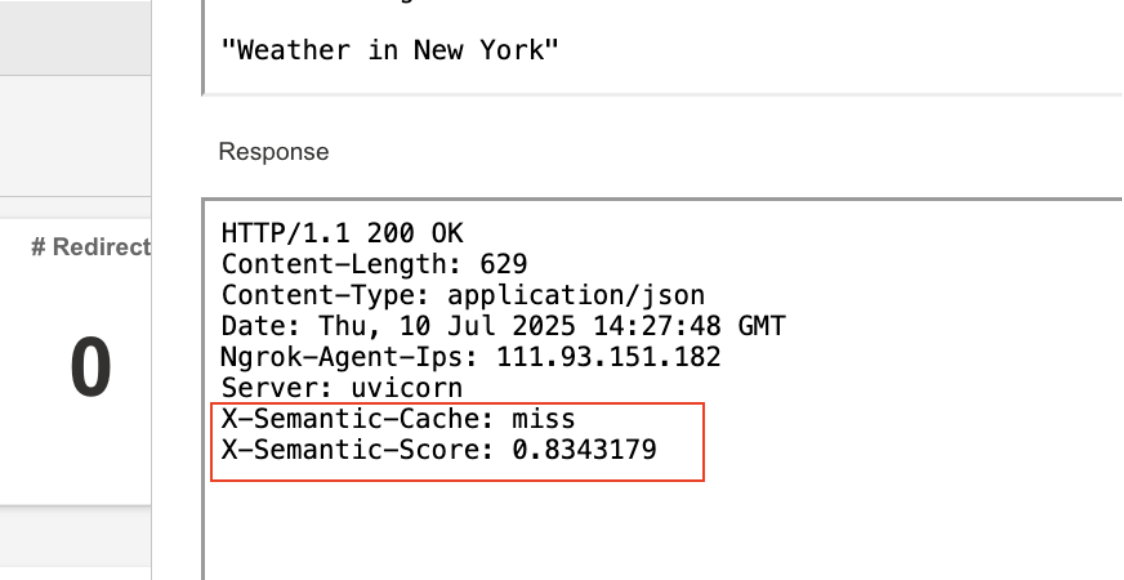
さらに詳しく見ると、プロンプトの初回実行時はキャッシュミスとなり、バックエンドに到達してレイテンシーとコストが増加していました。
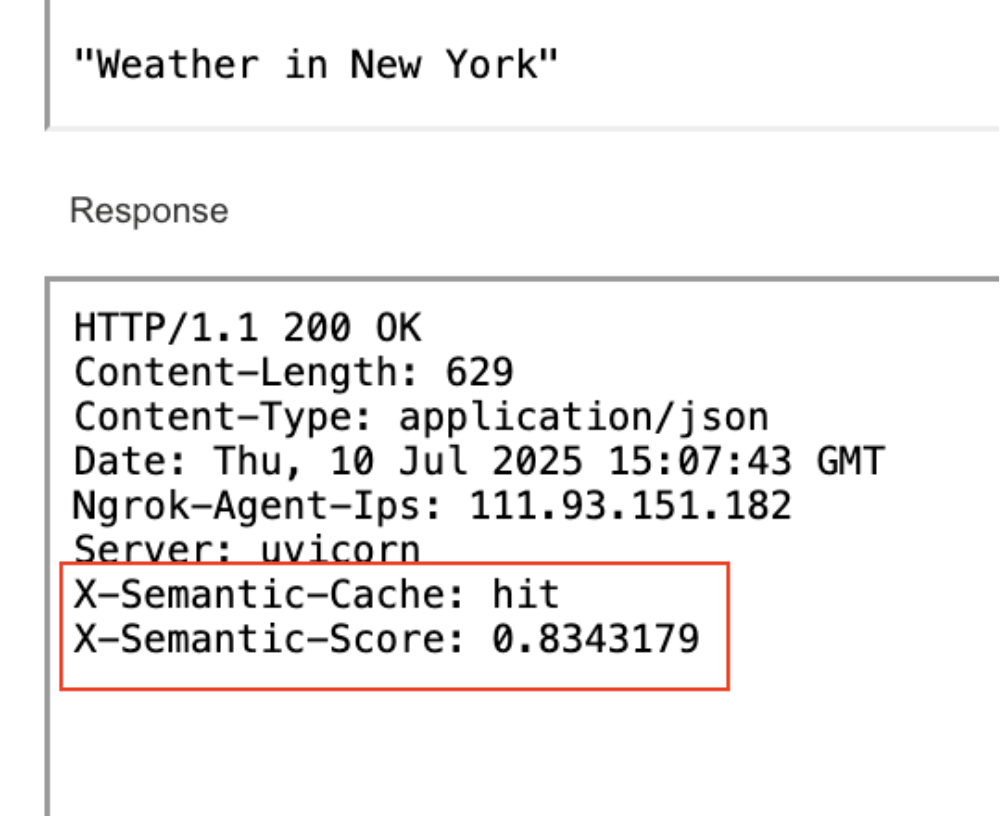
同じセマンティッククエリを再度実行した2回目では、キャッシュがヒットし、応答時間が50%短縮されました。

セマンティックキャッシングの信頼性を高めるためのモニタリング戦略
セマンティックキャッシングは、もはや裏方の最適化ではなく、リアルタイムに推論・行動するエージェント型AIシステムの基盤です。
しかし、その信頼性を確保するには、動作状況を継続的に測定する必要があります。
以下は、その信頼性を監視・改善するための3つの方法です。
#1. 意味的に類似したクエリをテストする
セマンティックキャッシングは、類似した質問をどれだけ正確にマッチできるかに依存します。
意図が同じで言い回しが異なるクエリを合成的にモニタリングしましょう。
- Who’s the President of the US?(アメリカの大統領は誰?)
- Who runs the US government?(アメリカ政府を動かしているのは誰?)
- Commander-in-Chief of America?(アメリカの最高司令官は?)
次に、その結果を比較します。
- それらはキャッシュヒットとなったか、ミスとなったか?
- セマンティック類似度スコアはいくつだったか?
このテストを通じて、キャッシングシステムがユーザーの意図を一貫して正しく認識できているかを確認できます。
エージェント型AIでは、単一の表現への対応だけでは信頼性が担保されず、意図のバリエーションすべてを正しく処理できることが不可欠です。
#2. セマンティック類似度スコアを追跡する
多くのセマンティックキャッシュは、新しいクエリが既存のキャッシュ済み応答とどれだけ近いかを示すスコア(例:0.85)を返します。
もしスコア(例:0.8343)が得られるなら、以下が可能です。
- 時系列での監視
- トレンドの可視化
- スコアが閾値を下回ったときのアラート設定
たとえば、我々のテストでは2つのリクエストが同じセマンティックスコア(0.85224825)を返しました。
しかし、モデルの変更やクエリの言い回しの変化により、スコアが低下し、予期せぬキャッシュミスとコストの増加が発生する可能性があります。
これらの数値を監視することで、セマンティックキャッシュの信頼性を確保し、不要なバックエンドコールの浪費を防ぐことができます。
#3. 実際のレイテンシー差を測定する
セマンティックキャッシングが約束する最大の利点の一つは速度です。
キャッシュヒットは、ミスに比べて明らかに高速であるべきです。
これをモニタリングすることで、次のような対応が可能です。
- キャッシュヒットとミスのメトリクスを分割
- 正確なレイテンシー差を表示
- キャッシュミスによる遅延発生時にアラートを出す
私たちのテスト結果
- キャッシュミス時の応答時間:約5秒
- キャッシュヒット時の応答時間:約2秒
これは、応答時間が2.5倍速くなることを意味します。
エージェント型AIの世界では、この差がスムーズな会話とイライラする待ち時間の差になります。
最終的なまとめ
セマンティックキャッシングは、もはや「あれば便利」な機能ではなく、リアルタイムAIシステムの中核インフラストラクチャとなりつつあります。
Fastly、AWS、Azure といったクラウドのリーダー企業は、すでに自社のアーキテクチャにセマンティックキャッシングを組み込んでいます。
しかし、この技術は同時に、非常に繊細で注意を要する側面も持ち合わせています。
言語表現の変化や埋め込みのドリフト、モデルの更新などにより、システムのパフォーマンスが徐々に低下する可能性があります。
セマンティックキャッシングとIPMを組み合わせることで、システムが「速い」だけでなく、「安定して速い」状態を維持できるようになります。
大規模にAIエージェントを運用している環境においては、セマンティックキャッシュの検知されにくい失敗は、単なる非効率では済まされません。
それは「リスク」です。
これを測定し、監視し、軽減する必要があります。
さらに詳しく知るには
エージェント型AIのレジリエンスモニタリング
AIアシスタントのパフォーマンスモニタリング