
LLMは止まらない:AIモデルをどう監視し、信頼するか
著者: Sheikh Mursaleen
翻訳: 逆井 晶子
この記事は米Catchpoint Systems社のブログ記事「LLMs don’t stand still: How to monitor and trust the models powering your AI」の翻訳です。
Spelldataは、Catchpointの日本代理店です。
この記事は、Catchpoint Systemsの許可を得て、翻訳しています。
ある大規模言語モデル(LLM)は、ブランドのイメージに合った文体を見事に再現します。
しかし、モデルのアップデートによって、その再現性が失われることもあります。
別のモデルは非常に高速です。
しかし、ピーク時間帯には遅延が発生します。
さらに別のモデルは優れた回答を返す一方で、特定の地域では性能が低下します。
LLMの選定と維持が難しい理由
オープンソースからプロプライエタリ(クローズドソース)まで、あらゆる種類のLLMは固定されたものではなく、常に動的に変化します。
知らないうちに更新され、予期せぬ誤答(いわゆるハルシネーション)を起こすことがあり、使用状況に応じてコストが変動し、地域・タスク・入力内容によっても性能が変わります。
つまり、昨日選んだモデルが今日も最良とは限らないのです。
チームに必要なのは、依存するLLMを継続的に評価する仕組みです。
比較、検証、ドリフト(性能変化)の監視、異常の早期検出などは、導入時だけでなく、運用中も毎日行う必要があります。
要約
LLMは強力ですが予測不能です。
その性能、精度、コスト、安全性は予告なく変化します。
そのため、継続的な監視と実地でのテストが不可欠です。
LLMを静的なツールとして扱うのではなく、信頼性、関連性、コスト効率を維持するために、定期的にテストと比較を行うべきです。
LLMの種類と監視への影響
LLMには、完全なオープンソース、クローズドソースAPI、ハイブリッドモデルなど、さまざまな形式があります。
- オープンソースLLM
- モデルの重みや一部の学習データ・コードにアクセスでき、自社環境での運用も可能です。
- クローズドソースモデル(例:GPT-4、Claude)
- プロプライエタリで、API経由で利用します。
- ハイブリッドモデル
- モデル自体はクラウド上の事業者によって提供されますが、完全にブラックボックスというわけではなく、モデル構造や調整パラメータに関する一部の情報が公開・設定可能です。
オープンソースの利点
- ライセンスコストが不要
- 柔軟性が高い(特にオンプレミスで)
- より高い透明性(モデルにより異なる)
ただし、オープンソースか否かにかかわらず、真の課題は、モデルの信頼性を時間の経過とともに監視・維持することです。
AIエージェントはどのように適切なLLMを選択するのか?
現代のAIエージェントは、ニーズに応じてタスクを異なるモデルにルーティングすることがよくあります。
選択の基準は以下の通りです。
- タスクの種類
- 推論、創造性、検索、リアルタイムな問い合わせ。
- 性能目標
- 速度、コスト、一貫性。
- セキュリティ要件
- プライベートインフラかクラウドか。
ルーティングの前に、AIエージェントは通常、チャットボットやフォームのようなフロントエンドインターフェースを通じて、質問やタスク要求などのユーザー入力を受け取ります。
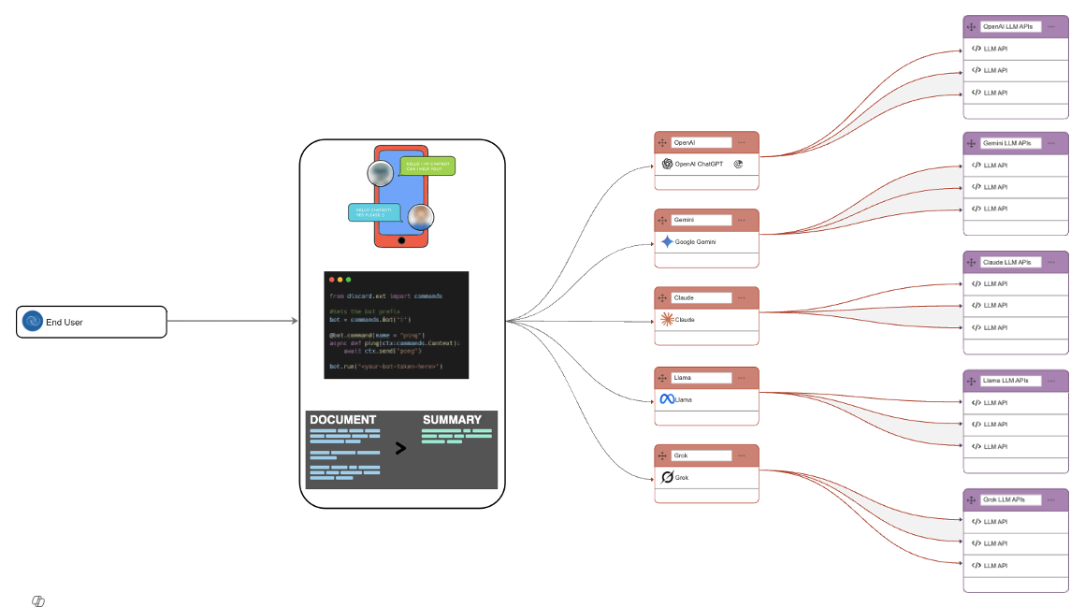
AIエージェントはルーターのように機能し、各プロンプトをビジネスロジックに基づいて最適なモデルにマッチングさせます。
よくあるLLMルーティングシナリオ
- GPT(OpenAI)
- 研究向けで、汎用的なテキスト生成に最適です。
- LLaMA
- 軽量で、オンプレミス環境にも適したオープンソースの代替モデルです。
- Gemini
- 推論能力に優れ、Googleとの統合性も高いです。
- Grok
- 動画生成やマルチメディア関連のタスクに適しています。
- Claude(Anthropic)
- 規制の厳しい分野においても、安全性の高い応答を提供します。
条件ベースのロジックが使用されます。
例えば、「入力が動画処理を含む場合 → Grokを使用する」といった具合です。
本当の課題は、一度LLMが選ばれた後、そのモデルが継続して良好に動作し続けるかどうかです。
ここで、Catchpointの監視が役立ちます。
CatchpointによるLLMのテストと監視アプローチ
CatchpointのLLM監視フレームワークは、要約からコード生成まで多様なタスクに対してモデルがどのように応答するかを評価し、実際のユースケースにおける信頼性を測定します。
3,000以上のインテリジェント・エージェントを活用し、GPT、Claude、Geminiなど各プラットフォームの応答の健全性、品質、レイテンシを厳密に監視できます。
具体的には以下を実施します。
- 世界中の複数の地域から複数のLLMにライブプロンプトを送信
- 各モデルの応答(トーン、一貫性、新しさ)を記録
- ドリフト、ハルシネーション、性能低下といった問題を特定
生成AIをワークフローに導入する際のリスクを軽減する、再利用可能なテストフレームワークです。
モデルの挙動に対する可視性と、選択・制御の柔軟性を提供します。
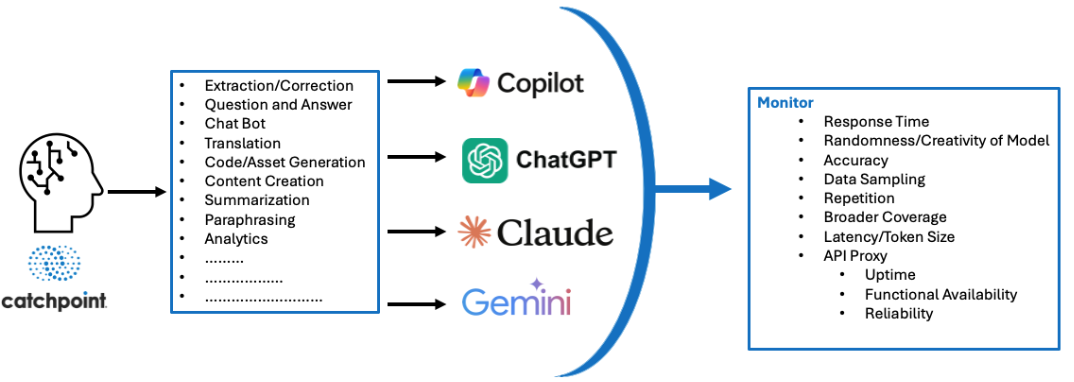
テスト対象となる主な機能
- プロンプトの解釈と自然言語での応答生成
- 同一入力に対する複数の視点の提示
- 多様なハイパーパラメータ下での挙動の検証
LLMの動作に影響を与える主要なAPIパラメータ
モデルの応答スタイルは、アーキテクチャだけでなく、プロンプトパラメータの設定に大きく依存します。
これらのパラメータはランダム性、冗長性、トーンを制御し、わずかな調整で結果が大きく変わることがあります。
以下は、LLM APIリクエストの例です。
- キーパラメータが応答をどのように構成するか
- 品質と性能の両面でどのようなメトリクスを追跡すべきか
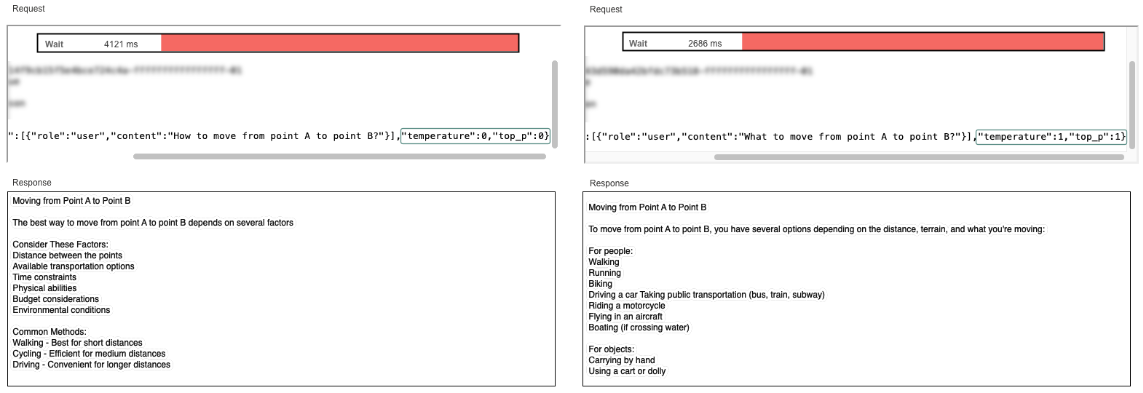
Catchpointでは、実際に以下のようなスクリプトを用いて複数モデルにプロンプトを送り、結果を比較しています。
Catchpoint Script例
var apiURL = "https://abc.com/models/openai|anthropic|google";
var apiData = {
"messages": [
{ "role": "user", "content": "What does Catchpoint do?" }
],
"temperature": 0.7,
"top_p": 0.9,
"frequency_penalty": 0.3,
"presence_penalty": 0.1,
"max_tokens": 500
};
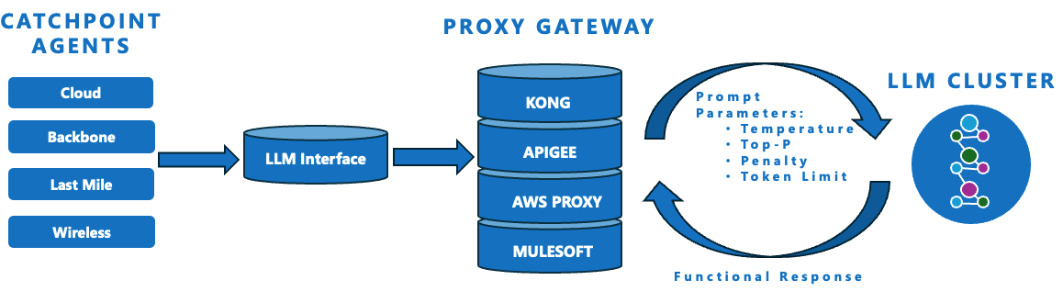
APIパラメータとその用途
これらのチューニングパラメータは、出力の長さやスタイル、創造性の度合いなど、LLMの応答を制御します。
小さな変更でもトーン、精度、コストに大きな影響を及ぼします。
| パラメータ名 | 制御内容 | 使用用途 | 例 / 推奨範囲 |
|---|---|---|---|
| 創造性の度合い(Temperature) | 創造性/ランダム性 | トーンや文体の調整 | 0.2 = 安定、0.8 = 創造的 |
| 語彙選択の範囲(Top-p) | 言い換えの多様性 | 一貫性を保った言い換え表現 | 0.9 = 一般的な多様性 |
| 繰り返し抑制(Frequency Penalty) | 冗長な語句の抑制 | ループや繰り返しの回避 | 0.5〜1.0 = 冗長さを抑えた出力 |
| 新しい話題の導入(Presence Penalty) | 新しい話題やアイデアの誘導 | 斬新な発想や幅広い視点の生成 | 0.5〜1.0 = 多様な視点や発想 |
| 最大トークン数(Max Tokens) | 出力の長さ | 出力の簡潔化と処理コストの最適化 | 100 = 短文、1000以上 = 長文出力 |
この表は、創造性、多様性、繰り返し、応答長など、主要なモデル挙動を調整するための参考資料です。
実践的なアドバイス
スタイルを調整する際は、「創造性の度合い(Temperature)」または「語彙選択の範囲(Top-p)」のいずれか一方を使用し、両方を同時に使わないようにしましょう。
これらの変数を細かく調整することは、モデルの挙動をビジネス目標に合わせるうえで重要です。
CatchpointでLLM性能をベンチマーク・比較する理由
LLMがさまざまなタスクでどう振る舞うかを理解するために、Catchpointは一貫したフレームワークを使って複数のモデルをテストしています。
これにより、トーン、レイテンシ、コストなどを比較できます。
この仕組みを使うことで、導入側のチームは次のような検証や比較が可能になります。
- 同じプロンプトをGPT、Claude、Geminiなど複数のモデルに送信
- 応答の遅延、スタイル、精度、コストを並列で測定
- 出力のドリフト(予期しない変化)を検出
- モデルの応答品質の低下や障害時を想定したフォールバックルーティングの検証
- 地域ごとのプロンプトを使ってローカライズやコンプライアンスを検証
最近のマルチモデルテストでは、ローカル環境での応答時間が27秒を超えるスパイクが記録された一方、OpenAIはClaudeやGeminiより平均的に応答が遅いものの、ばらつきは少なく比較的安定していました。
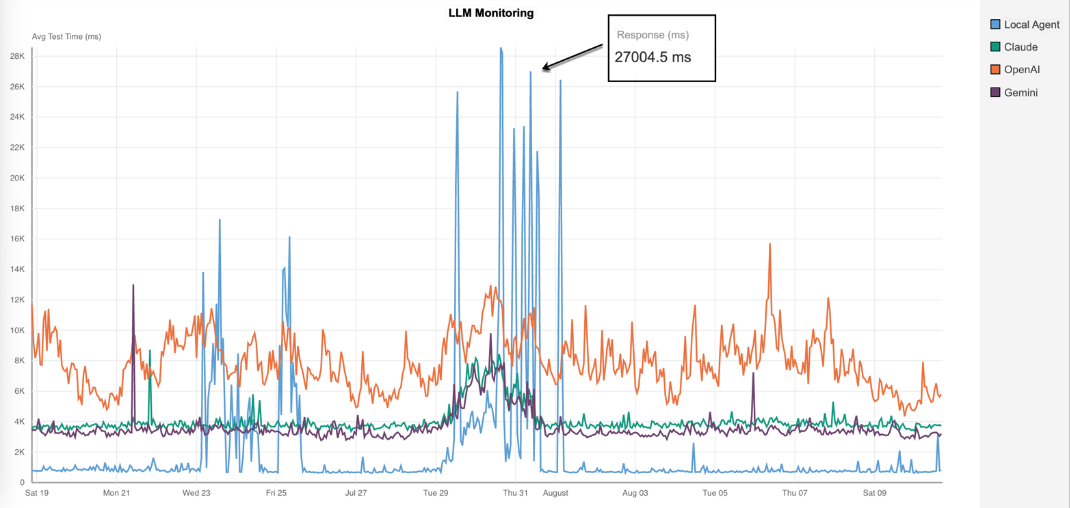
上のグラフは、同じテスト環境で各LLMが同じプロンプトに対してどのように応答したかを示しています。
各線は異なるモデルの応答を表しており、突発的なスパイクや持続的な遅延の傾向が見られます。
これにより、チームは性能と信頼性を評価するための根拠を得ることができます。
こうした異常を早期に検出することで、エンドユーザーへの影響が出る前に、バックアップモデルへ自動で切り替えることができます。
ベンチマークから継続的監視へ
Catchpointのベンダーニュートラルなプラットフォームは、利用者が複数のLLMを一つのインターフェース上で評価・比較・管理できるように設計されています。
以下の例では、Claude、OpenAI、Geminiがテスト期間中100%の稼働率を示す一方で、平均応答時間に明確な違いが見られました(Geminiは3.3秒、OpenAIは6.8秒)。
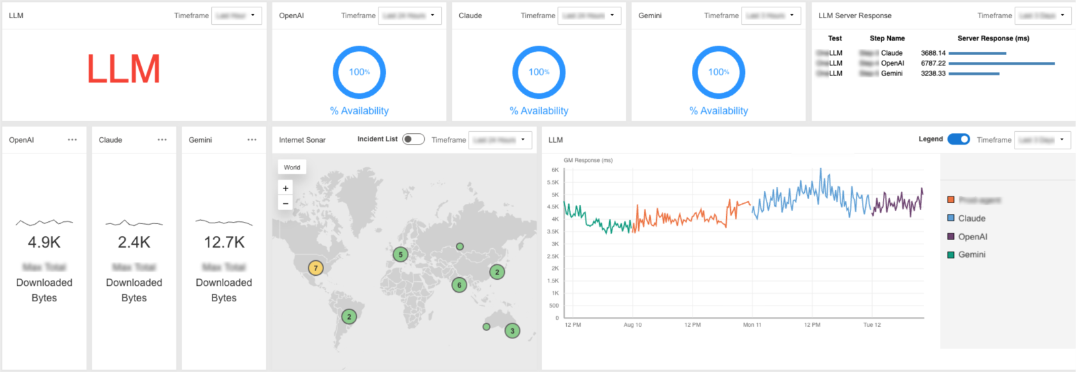
ダッシュボードでは、ダウンロードバイト量も追跡され、プロバイダごとの効率差が明らかになります。
また、インシデントを地図上で表示することで、どの地域で問題が発生しているかを特定できます。
Catchpointは、こうしたメトリクスにプロンプトレベルのスコアリングを組み合わせることで、LLMの性能をエンドツーエンドで可視化します。
これには、モデルの応答品質だけでなく、APIゲートウェイ、プロキシ、ネットワーク経路など応答配信に影響するすべての要素が含まれます。
以下が実際の運用例です。
- モデル統合前にトーン、コスト、性能を評価
- 自社データを用いて、精度、スタイル、ブランドトーンへの適合性をテストします。
- LLMのドリフト、ハルシネーションリスク、遅延をAPI経由で継続的に監視
- 出力の微細な変化やスタイルの不一致、品質の劣化を、エンドユーザーに届く前に検出できます。
- プロンプトスコアリングとフォールバックロジックによる並列テスト
- 出力品質を測定し、自動フェイルオーバー戦略を検証します。
- ゲートウェイおよびプロキシの信頼性を追跡し、LLMのエンドツーエンド配信を保証
- モデル本体だけでなく、リクエストが通る経路全体が正常に機能していることを確認します。
- あらゆるモデル、デプロイ形式、地域にテストを適用可能
- クラウド、オンプレミス、ハイブリッドのいずれのLLMにも、同一の監視アプローチを適用できます。
- セキュリティ・安全性に関するコンプライアンスの確認
- シンセティックプロンプトを使って、極端な入力やまれな状況を意図的に試し、モデルが公平性・安全性・透明性などを含む「責任あるAI」の原則に則って適切に応答するかどうかを検証します。
FAQ
- Q: 自社環境上で稼働するLLMも、グローバルなモデルと同様に監視できますか?
- A: はい。
Catchpointのシンセティックエージェントやローカルテストランナーは、自己ホスト型LLMに対しても、精度、レイテンシ、ドリフト、可用性を検証できます。
これにより、社内ネットワーク内とグローバルな観測点の両方から性能を測定できます。 - Q: Catchpointはオープンソースとクローズドソースの両方のLLMに対応していますか?
- A: もちろんです。
モデルが完全なオープンソースでも、API経由の利用でも、ハイブリッド形式でも、Catchpointのベンダーニュートラルなフレームワークは並列比較を行い、性能を測定し、品質の変化を追跡できます。 - Q: ドリフトや性能劣化のテストは、どのくらいの頻度で行うべきですか?
- A: 積極的なテストを推奨します。
高リスクまたは規制の厳しい環境では、ミリ秒単位のチェックが有効です。
Catchpointはこれらのテストを自動化し、ドリフト、レイテンシのスパイク、品質の劣化が検出された瞬間にアラートを発します。 - Q: 複数のLLMを同時にテストすることはできますか?
- A: はい。
GPT、Claude、Geminiなど複数のプロバイダーに同じプロンプトを送信し、トーン、精度、レイテンシ、コストを比較できます。
この並列テストにより、各ユースケースに最適なモデルを簡単に特定し、性能変化時には即座に切り替えることができます。
最終的なまとめ
LLMは変化し続ける存在であり、精度・コスト・信頼性といった要素が突然変わることもあります。
実運用環境では、「設定して終わり」は通用しません。
Catchpointを使えば、プロバイダー、地域、デプロイモデルをまたいだ性能を継続的に検証し、ドリフトや応答品質の低下をユーザーに影響が出る前に検出し、現実の条件下でのフォールバック戦略を検証できます。
レイテンシ、可用性、トーン、ブランドイメージとの一致といった測定可能な指標により信頼を運用可能な形にすることで、LLM監視は受動的な作業から能動的な優位性へと変わります。
その結果、問題解決が迅速になり、モデルの信頼性が向上し、どのLLMがどの瞬間に最適かを明確に理解できるようになります。
CatchpointのAI監視ソリューションについて詳しく知る
- エージェンティックAIのレジリエンス
- LLMに依存するAIエージェント、オーケストレーションロジック、ツールチェーンを監視し、エンドツーエンドの回復性を確保します。
- AIアシスタントの監視
- チャットボット、コパイロット、デジタルエージェントなど、AI搭載アシスタントの性能と信頼性を地域やプロバイダーをまたいで追跡します。