
デジタル従業員体験の基本を学ぶ
翻訳: 竹洞 陽一郎
この記事は米Catchpoint Systems社の学習記事 "Learn the Fundamentals of Digital Employee Experience"の翻訳です。
Spelldataは、Catchpointの日本代理店です。
この記事は、Catchpoint Systemsの許可を得て、翻訳しています。
はじめに
リモート勤務やサテライトオフィスで働く従業員は、デスクトップ構成、VPNアクセス、DNSルックアップ、WiFiの遅延、APIのレイテンシ、またはサードパーティアプリケーションプロバイダの問題といった技術的摩擦により、生産性を失っています。
従来のIT監視ツールは、リモートのエンドユーザと企業のデータセンター内のシステムとの間のトランザクション経路上にあるこれらの要素を監視しないため、システム全体が正常であると報告し続けます。
この視点のギャップにより、企業は生産性の損失として年間数十億ドルを失っており、多くの組織がこの摩擦がどこで発生しているのかを特定するツールを持っていません。
デジタル従業員体験(DEX)モニタリングは、アプリケーションサーバや企業ネットワークの健全性ではなく、エンドユーザの体験を測定することでこのギャップを埋めます。
このソリューションは、従来の監視の上にユーザ体験スコアを重ね、システムパフォーマンスとユーザへの影響を結びつけた統合ビューを作成します。
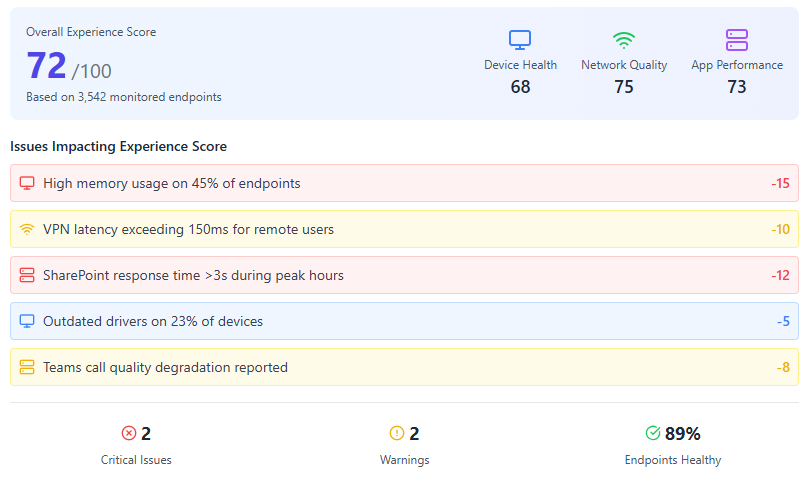
たとえば、以下のダッシュボードは、画面右上に表示される3つのスコアで構成された全体的なユーザ体験スコアを示しています。
- エンドユーザコンピュータなどのデバイスの健全性
- パブリックインターネットやユーザのWiFiネットワークを含むネットワーク品質
- サードパーティのSaaSアプリケーションを含むアプリケーションパフォーマンス
スコアの下のセクションには、デスクトップ構成やVPNのレイテンシなど、スコア低下の原因となる根本的な問題が表示されます。
この統合ビューは、従業員の体験と、その劣化につながる要因を監視するために設計されています。
この記事では、デジタル従業員体験の健全性スコアが実際にどのように機能するのか、なぜそれが従来の監視を上回るのか、そして技術チームがどのようにして指標を現実に即したものにするためにデジタル従業員モニタリングを効果的に実装できるのかについて解説します。
デジタル従業員体験の健全性スコアリングに関する主要な概念の要約
| デジタル従業員体験モニタリングの構成要素 | 体験スコアへの影響 |
|---|---|
| アプリケーション層 | フロントエンドの遅延、APIチェーン、従業員の生産性やタスク完了に直接影響するエラーを追跡します。 |
| ネットワーク層 | 従業員とアプリケーション間でネットワーク問題が正確にどこで発生しているかを特定し、対象を絞った修復を可能にします。 |
| エンドポイントパフォーマンス | アプリケーションの使用状況に基づいて監視強度を調整し、デバイス性能に影響を与えずに関連するパフォーマンスデータを取得します。 |
| データ収集 | システムリソースを圧迫することなく、完全な体験データを取得するためにさまざまな監視メカニズムを統合します。 |
| 相関エンジン | 技術的な問題を実際のビジネスインパクトに結び付けることで、生の指標を実用的なインサイトに変換します。 |
生産性への影響分析のためのアプリケーションメトリクスの取得
従業員の不満は、アプリケーション層で発生します。
しかし、多くの監視メカニズムはインフラ層で止まってしまいます。
従業員体験スコアリングのためのアプリケーション層メトリクスは、監視ダッシュボードが「全システム正常」と表示していても、アプリケーションが従業員の業務遂行能力にどのように影響しているかに焦点を当てる必要があります。
以下は、アプリケーションのパフォーマンスをデジタル従業員体験および生産性と直接関連付ける、最も重要な要素のいくつかです。
フロントエンドパフォーマンスの測定
効果的なフロントエンド測定を行うためには、特定のインタラクションパターンを追跡する必要があります。
| インタラクションパターン | 意味 | 例 |
|---|---|---|
| Time to Interactive (TTI) | コンテンツが表示されるだけでなく、ユーザが実際に操作を開始できるようになるまでの時間を測定します。 | インターフェースは2秒で読み込まれても、JavaScriptの処理によりさらに5秒間クリックできない状態が続くことがあります。 |
| 入力レイテンシ(Input latency) | ユーザの操作と視覚的な反応との間の遅延を測定します。 | 従業員が検索ボックスに入力したとき、文字が表示されるまでの時間を測定します。 「保存」をクリックしてからシステムがクリックを認識したことを示すまでの時間を測定します。 |
| 累積レイアウトシフト(Cumulative Layout Shift, CLS) | 画面上の視覚的不安定性を定量化します。 | 誰かがクリックしようとした瞬間に送信ボタンが別の位置に移動してしまう場合があります。 |
フロントエンドの遅延は、バックエンドのパフォーマンスとは異なるスケールで発生します。
Googleの調査によると、インターフェースの応答に3秒以上かかる場合、ユーザの53%がタスクを放棄するとされています。
企業ユーザはツールに依存しているため、すぐに離脱することはできませんが、最終的にはそのツールに対して否定的な印象を持つようになります。
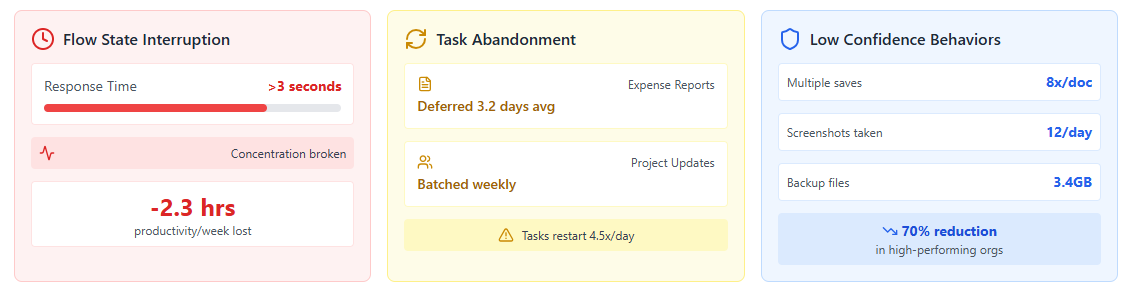
以下のスクリーンショットは、ワークフローの中断が従業員体験に与える典型的な影響を示しています。
左側に表示されているアプリケーションユーザインターフェースの応答時間は、ユーザがセッションを放棄する要因となり、UIの応答が遅いためにユーザがドキュメントを何度も保存するなど、アプリケーションに対する信頼の低下を示す行動の増加につながります。
APIパフォーマンス監視
フロントエンド監視で問題が検知された場合(例:「ログインページが遅い」)、次のステップは高いレイテンシに寄与しているコンポーネントを特定するために基盤となるAPI呼び出しを調査することです。
現代のアプリケーションは、ユーザインターフェースを描画するために一般的な操作でも平均30〜50のAPI呼び出しを行います。
各呼び出しはレイテンシを追加し、失敗は予期せぬ形で連鎖します。
従業員体験をスコアリングする際の要点は、最も頻繁な従業員タスクの背後にある重要な体験パスとしてAPIチェーンを特定し、監視することです。
平均的な従業員が日々の特定の中核タスク(顧客レコードの更新、通話の記録、案件の作成など)をどのように完了するかを考えてみてください。
これらのタスクに関与するすべてのAPIをマッピングし、タスクの頻度とビジネス上の重要性に基づいてそのパフォーマンスに重み付けをすることができます。
しかし同時に、ユーザの視点からAPIパフォーマンスを測定することも同じくらい重要です。
認証APIの平均応答時間が50msであっても、その平均は不満につながる重要なデータポイントを覆い隠してしまう可能性があります。
API監視は部分的な失敗も考慮しなければなりません。
たとえば、ドキュメントのアップロード自体は成功しても、インデックス作成サービスが失敗する場合があります。
その結果、従業員はファイルを保存できても、後からそれを検索できない状態になります。
体験スコアリングに最も価値のあるAPIメトリクスは以下の通りです。
| メトリクス | 説明 | 例 |
|---|---|---|
| ワークフロー完了時間 | タスク開始から確認までの総時間を計測し、APIチェーン全体を追跡します。 | 「新規プロジェクト作成」タスクは5つのサービスに跨る15回のAPI呼び出しを伴い、累積処理時間が従業員にとって長すぎる可能性があります。 |
| 依存関係の影響スコアリング | 波及効果を追跡し、単一点の遅延がどのように広範な不満へと連鎖するかを定量化します。 | 認証サービスが500ms遅くなったとき、どれだけ多くの下流の体験が劣化しますか。 |
| ピーク時のパフォーマンス | 重要な時間帯を閑散時よりも高い重みで評価します。 | APIは平均的には良好でも、ビジネスにとって重要なタイミングで失敗することがあります。 |
エラートラッキングと影響の定量化
より広範な利用を目的としたアプリケーション、特にエンタープライズレベルの環境では、エラーデータを暗黙的に生成してエラー率を算出できる場合や、監視システムと明示的に統合して主要業績評価指標(KPI)として計算・表示することが可能です。
しかし、エラー率は必ずしも正確な状況を表しているとは限りません。
例えば、エラー率が0.1%であっても、それが重要な時間帯に1,000人のチームに影響を与える場合、再作業や報告遅延によって分単位で大きな損失が発生する可能性があります。
実際の有用性を確保するために、体験スコアリングシステム内でのエラー分類は、常に従業員の業務効率およびビジネス全体の文脈に対する直接的な影響に焦点を当てるべきです。
参考までに、これを典型的なJavaScriptエラーに関連付けて理解すると次のようになります。
- クリティカルパスエラー
-
主要な業務機能を妨げるエラーです。
例:勤務表を提出できない、請求書を承認できない。 - 機能劣化エラー
-
機能性を低下させるエラーです。
例:高度な検索が失敗し、基本検索にフォールバックする。 - 外観上のエラー
- 機能に影響しない視覚的な不具合です。
各カテゴリーは異なる対応レベルを必要とします。
例えば、社内ディレクトリの外観上のエラーは対応不要かもしれません。
一方で、出張シーズン中の経費システムにおけるクリティカルパスエラーは即時の対応が求められます。
このようなアプリケーションの優先順位付けは、技術的な指標をビジネスコストに変換する助けとなります。
影響をより深く理解するためには、セッションリプレイを活用して、ユーザがエラー発生時にどのような操作を行おうとしていたのかを把握することが有効です。
これにより、同じ操作を複数回試みて諦める従業員の行動や、特定のエラーが多発するステップで一貫してワークフローを放棄する傾向などを監視することができます。
従業員デバイステレメトリによるネットワーク影響の測定
ネットワーク経路は一見単純に見えますが、従業員はアプリケーションにアクセスする前にDNSルックアップやCDNリダイレクトを経由しなければなりません。
多くの監視は最終的な接続に焦点を当てていますが、DNS解決が遅いと、他の処理が始まる前に数秒の遅延が発生します。
同様に、静的コンテンツがパフォーマンスの低いCDNエッジからロードされる場合、バックエンドが非常に高速であってもアプリケーションの動作は遅く感じられます。
ネットワークが従業員体験に与える影響を真に理解するには、従業員のデバイスからテレメトリデータを取得し、実際の作業中の体験を記録する必要があります。
これは、自宅からリモートで働くユーザのデスクトップや、サテライトオフィスに設置されたネットワーク機器などからの実測データを指します。
ここで重要なのは、データセンターからの合成テストではなく、実際の業務中のリアルな測定であるという点です。
難しい点は、異なる場所・異なるネットワーク環境で働く全員のデータを正規化することです。

従業員がパフォーマンスに不満を訴えた場合、問題がどこにあるのかを正確に特定する必要があります。
従業員の所在地からのトレースルートデータを確認することで、従業員とアプリケーションの間に存在するすべてのホップを把握できます。
これは体験スコアリングにおいて重要です。なぜなら、ホップ3(おそらくISP)で200msの遅延が発生する場合と、ホップ12(アプリケーション付近)で同じ遅延が発生する場合では、必要な対処が異なるためです。
この粒度がなければ、スコアは「問題がある」ことを示しても、「何を修正すべきか」はわかりません。
ネットワークメトリクスは本質的にノイズを多く含むため、体験スコアリングの仕組みはこれらのデータを賢く処理する必要があります。
真の洞察は、これらのネットワーク測定値をアプリケーションイベントと相関させることで得られます。
サポートチームは、再送信のスパイクが「ファイルアップロード中」に発生したのか、それとも別のタイミングだったのかを知る必要があります。
適切な文脈を得るためには、ネットワーク、実ユーザ体験、APIをすべて1つのプラットフォームで監視できるツールを選択することが望ましいです。
コンテキスト対応パフォーマンスデータのためのエンドポイント計測
エンドポイント(例:エンドユーザのデスクトップやモバイルデバイス)が業務体験に与える影響を理解するためには、他の監視と同様にコンテキスト対応のアプローチが必要です。
これは、エンドポイントデバイスのメトリクスおよびシステム構成を監視する必要があることを意味します。
従業員体験を理解するためには、エンドポイントデバイス上にエージェントをインストールし、次のようなシステムメトリクスを監視する必要があります。
CPUおよびRAMの使用率、OS上で稼働しているプロセス(例:Microsoft Teamsアプリケーション)、ネットワークインターフェースカード(NIC)の活動、システムおよびアプリケーションログ、さらにシステム構成設定などです。
ただし、データ収集はエンドユーザにとって明確に感じられるような監視オーバーヘッドによるシステムの遅延を避けるために、賢く実施する必要があります。
例えば、Microsoft Teamsの通話がアクティブなときのみ詳細なメトリクスを収集し、Teamsを使用していないときは収集を行わないようにするなどの方法があります。
最良の結果を得るためには、アプリケーションエラーが記録されたときなど、問題発生時にのみデータ収集を強化し、通常の運用中は収集頻度を下げる「アダプティブサンプリング」を活用することが推奨されます。
エンタープライズグレードの体験プラットフォームには、数千のエンドポイントに対応できるスケーラブルなアーキテクチャが求められます。
典型的な設計では、複数の収集手法を階層的に組み合わせます。
- Webアプリケーションのタイミングやエラーを取得するためのブラウザ監視
- デスクトップパフォーマンスを監視するためのOSレベルの測定
- クラウドベースのアプリケーションサービスからテレメトリデータを収集するためのAPI監視
このような多層的アプローチは、単一の技術ではすべての関連データを監視できないため不可欠です。
正確なスコアリングのための複数データ収集手法の活用
現代の体験監視プラットフォームは、複数の収集手法を組み合わせて利用します。
各収集方法はタイムスタンプの取り方や粒度が異なり、他の手法では検出できるイベントを見逃す場合もあります。
たとえば、主要なプラットフォームが実施しているように、実ユーザ監視(RUM)と合成監視データを連携させて、それぞれの手法の死角を補うアプローチがあります。
両者は根本的に異なるデータを異なるタイミングで収集しますが、「どちらがユーザ体験を正確に測定できるか」は常に議論の的となります。
RUM(実ユーザ監視)
RUMは、JavaScriptインジェクション、ブラウザプラグイン、またはアプリケーションフックを通じて実際の従業員体験を収集します。
これはユーザが実際に体験している内容を正確に示しますが、ユーザがアクティブに作業している時にのみデータを収集できます。
実装にはアプリケーションの修正やブラウザ拡張機能の導入が必要となるため、セキュリティチームが抵抗することもあります。
合成監視(Synthetic Monitoring)
一方、合成監視はスクリプト化されたトランザクションを継続的に実行し、従業員がアプリケーションを使用し始める前に問題を検出します。
たとえば、ユーザが朝にアプリケーションへログインする前に、シミュレートされたトランザクションによってネットワークまたはアプリケーションの問題を夜間に検出できる場合があります。

RUMは数百のアプリケーションにわたって計測が必要ですが、実際の問題を明確に示すことができます。
合成監視は主要なトランザクションスクリプトのみを必要としますが、アプリケーションの高度な機能を使用している際の遅延など、例外的なケースを見逃す可能性があります。
データ相関とAIを活用した迅速な問題解決
基本的な監視ツールを評価する場合、相関エンジンは必須ではなく、正確なデータ収集ができれば十分です。
しかし、従業員の技術的な問題を迅速に解決して生産性を向上させるソリューションを求めるなら、相関機能は不可欠です。
例として、通常の監視では「CPU使用率が90%」という情報しか示されません。
一方、機械学習と人工知能(AI)を活用してサイロ間のデータを相関させられる監視システムであれば、
「経理チームが月末処理を完了できないのは、ExcelマクロがウイルススキャンとCPUリソースを競合しているためです」と教えてくれます。

選定する監視プラットフォームは、異なるフォーマットのレポートを生成するまったく異なるソースからのデータを相関できる必要があります。
適切なプラットフォームは、互換性のないデータタイプを正規化するだけでなく、不完全なデータにも柔軟に対応できます。
たとえば、ネットワークモニターが5分間オフラインだった場合でも、その期間中のエンドポイントおよびアプリケーションの問題を相関できるでしょうか。
多くの場合、すべてのソースから完璧なデータを得るのではなく、確率的なマッチングが必要になります。
さらに重要なのは、監視プラットフォームが「どの接続が意味を持つのか」を理解しているかどうかです。
このツールは、タイムスタンプが完全に一致しなくても、数秒以内に発生したイベントを関連付けられるだけの知能を備えているべきです。
また、「5秒以内に発生したものはおそらく関連している」といった時間ウィンドウを用いて、関連イベントをグループ化できる必要があります。
監視ソリューションを選定する前に、確認すべき質問は以下のようなものがあります。
- 数秒の差で発生したイベントを関連付けることができますか?
- 異なるタイムゾーンを使用するシステムのデータをどのように処理しますか?
- 問題を特定した際、単一の答えを提示するのか、それとも信頼度スコア付きで最も可能性の高い原因を提示しますか?
Catchpointによる従業員体験スコアリングの標準化
デジタル従業員体験の健全性は、根本的な問題の修正が複雑であっても、現在では比較的容易に測定できるようになっています。
Catchpointは、評価基準を統一されたスコアリング手法として体系化することで、デジタル体験モニタリングを簡素化してきました。
この手法は、デバイスのパフォーマンス、ネットワーク品質、アプリケーションの応答性を自動的に重み付けして評価します。
基本的には、Catchpointの監視をデジタルワークプレース全体に導入すると、各コンポーネントを評価し、包括的な体験スコアを算出します。
このプラットフォームは、エンドポイント・ネットワーク・アプリケーションという3つのサブスコアから計算された総合スコアを提供し、どの要素がパフォーマンスを低下させているのかを正確に特定します。
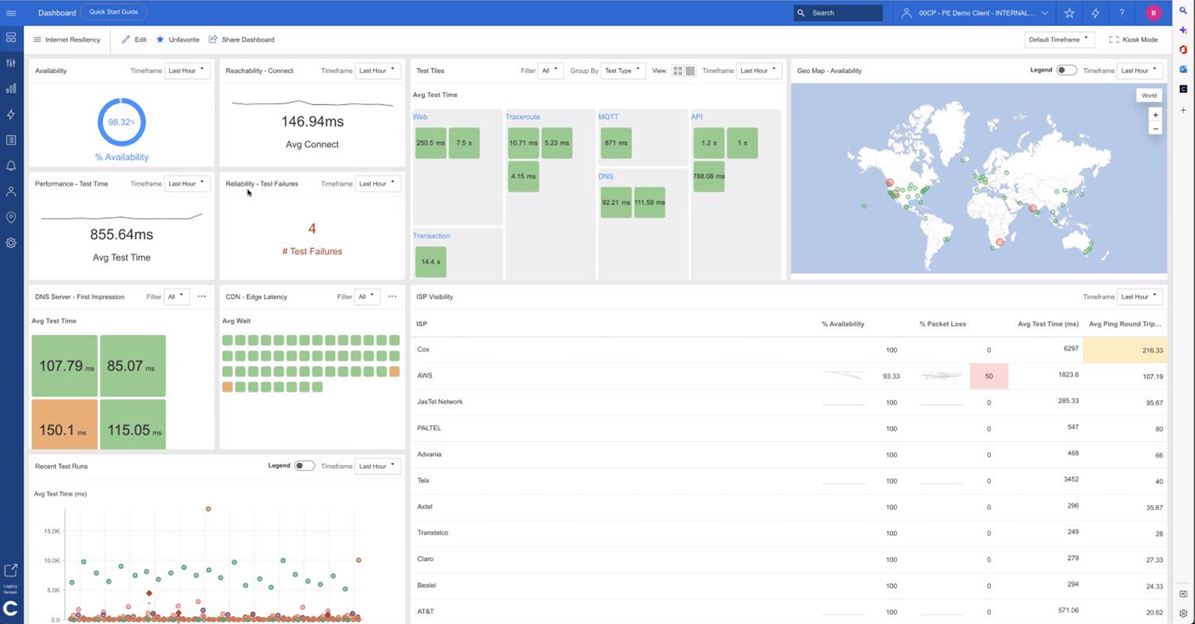
この標準化は、他の監視分野で起きた進化を反映しています。
Webサイトのパフォーマンスツールが「Core Web Vitals」などの標準指標を確立したのと同様に、Catchpointはフォーチュン500企業が従業員体験の唯一の信頼できる指標として採用する実証済みのフレームワークを構築しました。
このスコアにより、ITチームは体験品質を即座に可視化し、生産性に影響を与える特定の問題を詳細に分析できます。
真の革新はそのシンプルさにあります。
ばらばらのデータソースを相関させたり、従業員の苦情に頼ったりする代わりに、チームは次の根本的な問いに答える単一の実用的な指標を得られます。
― 「いま、従業員は良いデジタル体験をしているのか、それとも悪い体験をしているのか?」
Catchpointがどのように役立つかまだ確信が持てませんか?
無料トライアルを予約してみてください。
章構成
- デジタル従業員体験
- このデジタル従業員体験ガイドは、デジタル従業員体験の健全性スコアが実際にどのように機能するのか、なぜそれが従来の監視を上回るのか、そして技術チームがどのようにして指標を現実に即したものにするためにデジタル従業員モニタリングを効果的に実装できるのかについて解説します。
- 1. リモートデスクトップ監視
-
リモートデスクトップサービスのベストプラクティスと活用方法を学びます。
特に、セキュリティおよびコンプライアンスの観点からリモートデスクトップ監視の重要性を理解します。 - 2. VPN監視
- 最新のネットワーク環境において最適なパフォーマンス、セキュリティ、信頼性を確保するためのVPN監視のベストプラクティスを学び、今後の発展に備えます。
- 3. SaaSアプリケーション監視
-
問題を事前に検出し、ユーザインタラクションをシミュレートし、DevOpsと統合するSaaSアプリケーション監視の設定方法を学びます。
実ユーザ監視と合成監視の両方を活用します。 - 4. SaaS監視ツール
- SaaSアプリケーション監視の複雑さと課題、そして優れたSaaS監視ツールに求められる主な機能について学びます。
- 5. SaaS監視
-
SaaSパフォーマンス監視の課題とベストプラクティスを学びます。
インテリジェントエージェントの利点や、インターネットスタック全体の可視性の重要性についても理解します。