
API監視ツール:現代のAPI環境における必須機能
翻訳: 竹洞 陽一郎
この記事は米Catchpoint Systems社の学習記事 API monitoring tools: must-have features for the modern API landscapeの翻訳です。
Spelldataは、Catchpointの日本代理店です。
この記事は、Catchpoint Systemsの許可を得て、翻訳しています。
はじめに
今日では、先進的な組織の多くがAPIファーストの環境で運用しており、アプリケーションは単独の存在ではなく、マイクロサービスの相互接続網となっています。
この変化に伴い、APIのヘルスチェックは単なるエンドポイントのPingから、多面的な可観測性へと進化しています。
組織は、リアクティブな監視アプローチを採用して問題が発生した際に修正するか、先進的な可観測性シグナルとOpenTelemetryのサポートを活用したプロアクティブな戦略に投資することができます。
リアクティブなアプローチは、しばしば基本的なものとされています。
しかし、高度な監視プラットフォームによって強化された即時使用可能なソリューションは、より包括的な予防戦略を提供します。
ただし、これらのツールを最適に活用するには、複数の要素を考慮する必要があります。
本記事では、API監視ツールの主要な機能、それが重要である理由、および全体的な監視戦略の支援方法について掘り下げます。
現代のAPI監視ツールに必要な8つの必須機能
以下の表は、DevOpsエンジニアが現代のAPI監視ツールに求める8つの必須機能をまとめたものです。
なお、ダッシュボード、レポート、アラートなど、あらゆる監視ツールに標準装備されている基本的な機能については、本リストには含めていません。
| 番号 | 必須機能 | 説明 |
|---|---|---|
| 1 | APIの可観測性シグナル | メトリクス、トレース、ログを活用します。 |
| 2 | トランザクション経路全体の監視 | DNS、CDN、インターネットのトランジットポイントを含め、ユーザ体験に影響を与えるサードパーティ依存関係を完全に可視化します。 |
| 3 | OpenTelemetryオープンソースフレームワークのサポート | 最新のベンダーが対応するCloud Native Computing Foundation (CNCF) ツールキットを活用し、ベンダーロックインを回避します。 |
| 4 | サービスカタログとAPIドキュメントのサポート | OpenAPIなどのツールを使用し、APIドキュメントやサービスカタログを管理します。 |
| 5 | CI/CDパイプラインとの統合 | 継続的デリバリーに統合し、「Shift Left」戦略を採用してコードリリース前の監視を実施します。 |
| 6 | すべての種類のAPIをサポート | SOAP、HTTP、REST、GraphQLなど、複数のプログラミング言語で実装されたAPIを監視します。 |
| 7 | マイクロサービスとサーバレスコンピューティングのサポート | AWS API Gateway(サーバレス対応)、gRPC、Istio、Consul(HashiCorp製)、Linkerdなどのサービスメッシュを統合し、監視を強化します。 |
| 8 | マルチレベルのインフラ監視 | ホストだけでなく、KubernetesのPod、ロードバランサー、コンテナなど、あらゆるインフラレベルを監視します。 |
APIの可観測性シグナル
APIの可観測性は、プライベート、パートナー、パブリックを含むすべてのAPIタイプのパフォーマンスを最大化するためにチームを支援します。
これを実現するために不可欠なのが、可観測性シグナルであるメトリクス、イベント、ログ、トレースです。
これらを組み合わせることで、APIの動作を詳細に理解することができます。
4つのテレメトリータイプはそれぞれ単独でも価値を持ちますが、統合的に分析することで、APIの健全性とパフォーマンスを包括的に把握できます。
トレース(Traces)
トレースは、システム内のトランザクションの流れをマッピングし、APIエンドポイントの動作を深く理解するための手法です。
トレースは、個々のAPI呼び出しを特定のアクションと結び付けることで、より詳細なインサイトを提供します。
例えば、ユーザートラフィックの急増がKubernetesの自動Podスケーリングを引き起こすケースを考えてみましょう。
トレースを利用すると、リクエストがロードバランサー、APIサーバーを経由し、新しく作成されたPodインスタンスに到達するまでの流れを把握できます。
これにより、自動スケーリングにおけるレイテンシーやエラーを特定することができます。
1つのトレースは、複数のスパン(Span)で構成されます。
それぞれのスパンは、異なるマイクロサービスやシステムコンポーネントに対応します。
各操作をスパンとして捉え、それらのスパンの集合がトレースとなると考えると理解しやすいでしょう。
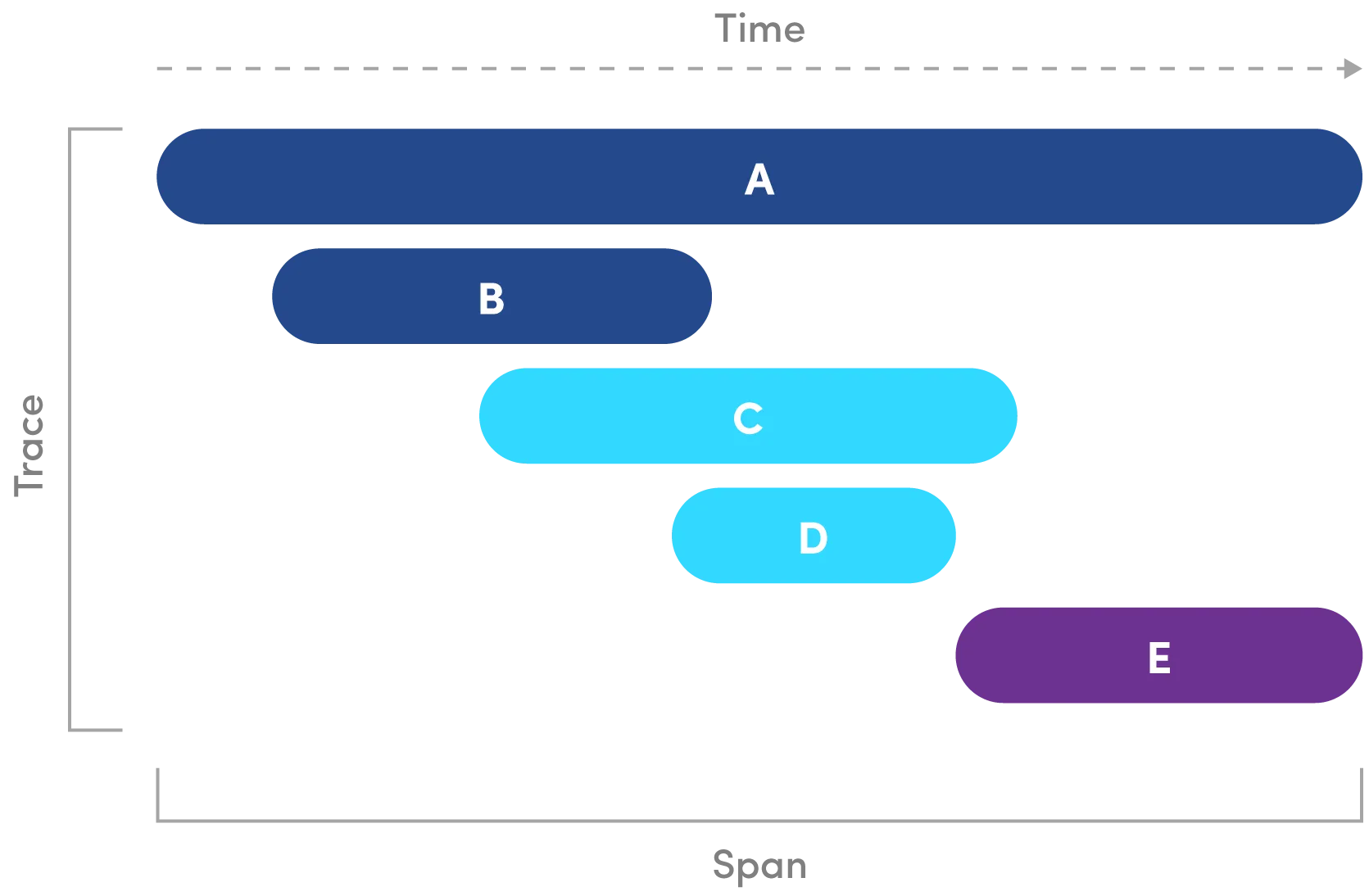
API監視ソリューションを評価する際には、トレース機能の高度さと柔軟性を考慮することが重要です。
高度なトレース機能を備えたツールでは、各スパンにコンテキスト情報を埋め込むことができます。
例えば、実行されたSQLクエリやCPUキャッシュの状態などをスパン内に記録できます。
また、これらのスパンをメトリクスやログとリンクさせることで、包括的なトレースグラフを作成できます。
ツールの可視化機能が、サービス間の相互作用を正確にマッピングし、ボトルネックやサービスの非効率性を特定できるかを確認することが重要です。
さらに、トレースソリューションが、アプリケーションスタックで使用されているすべてのプログラミング言語やデータベース技術をサポートしているかを確認しましょう。
対応範囲が不十分だと、監視の盲点が生じ、高精度なトレースが実現できなくなります。
スパンとトレースの詳細については、次のセクションで詳しく説明します。
メトリクス(Metrics)
メトリクスは、APIの状態を把握するために、ミリ秒単位から数時間単位までの異なる間隔で測定・収集されます。
また、特定のAPIエンドポイントへの接続時間など、各リクエストのリアルタイムテレメトリーとして記録されることもあります。
この2つのアプローチを組み合わせることで、スナップショットとしての視点と継続的な監視の両方が可能になり、APIパフォーマンスの包括的な把握が実現します。
メトリクスは細かく分類されることで、何が起こっているのか、そしてなぜ起こっているのかをより詳細に分析できるようになります。
メトリクスの集約(Aggregation)は常に選択肢の一つですが、平均値からのデアグリゲーション(分解)では概算しか得られません。
より多くの生のメトリクスを収集することで、分析の解像度が向上します。
サンプリングによっておおよその傾向を把握することは可能ですが、各リクエストのパフォーマンスメトリクスを完全に取得することで、瞬間ごとの正確な評価が可能になります。
以下の表に示すようなメトリクスのいくつかは、APIのパフォーマンスに直接または間接的に影響を与えます。
| メトリクス名 | カテゴリ | 説明 | 関連性 |
|---|---|---|---|
| エラー率 | 運用 | 1秒あたりの失敗リクエスト数 | APIの信頼性を測定 |
| リクエスト数/秒 | 運用 | 1秒あたりに受信したAPIリクエスト数 | 負荷と需要を示す |
| CPU負荷 | インフラ | CPU使用率の割合 | リソースの使用状況を把握 |
| ディスクI/O | インフラ | 1秒あたりのディスクの入出力操作数 | データフローのボトルネックを検出 |
| APIトークン使用率 | カスタム | 特定のAPIトークンの使用頻度 | セキュリティと利用パターンを監視 |
| クエリ効率 | カスタム | データベースクエリの実行時間 | バックエンドのデータベースパフォーマンスを評価 |
メトリクスを取得した後、それらを整理し、より扱いやすく洞察を得られる形に統合することが重要です。
集約手法を用いることで、生のデータポイントを整理し、特定のパフォーマンス問題に対する回答を導き出すことができます。
代表的な集約手法には以下のものがあります。
- 合計
-
すべての値を加算。
API呼び出しの総数を把握するのに有効。 - 平均
-
すべてのメトリクス値の平均値。
バランスの取れた視点を提供するが、外れ値に影響を受けやすい。 - 中央値
-
値の中央(50パーセンタイル)。
平均値よりも安定した中心傾向を示す。 - パーセンタイル
-
観測値のうち、特定の割合のデータがどの範囲に収まるかを示す。
外れ値の分析や、異なる負荷条件下でのシステムの挙動を理解するのに役立つ。
集約手法に加えて、ヒストグラムを活用すると、API監視の精度をさらに向上できます。
ヒストグラムはデータポイントを範囲(ビン)ごとに分類し、頻度分布を視覚的に示します。
例えば、レイテンシ(応答時間)を分析する際に、パーセンタイルを用いることで、大半のリクエストが高速で処理されていることがわかるかもしれません。
しかし、ヒストグラムを用いると、ごく一部のリクエストが極端に遅くなっているケースを特定でき、問題の調査につなげることができます。
メトリクスの管理能力、各種集約手法の適用範囲、ヒストグラムの活用精度など、ツールの高度な機能は選定時の重要な要素となります。
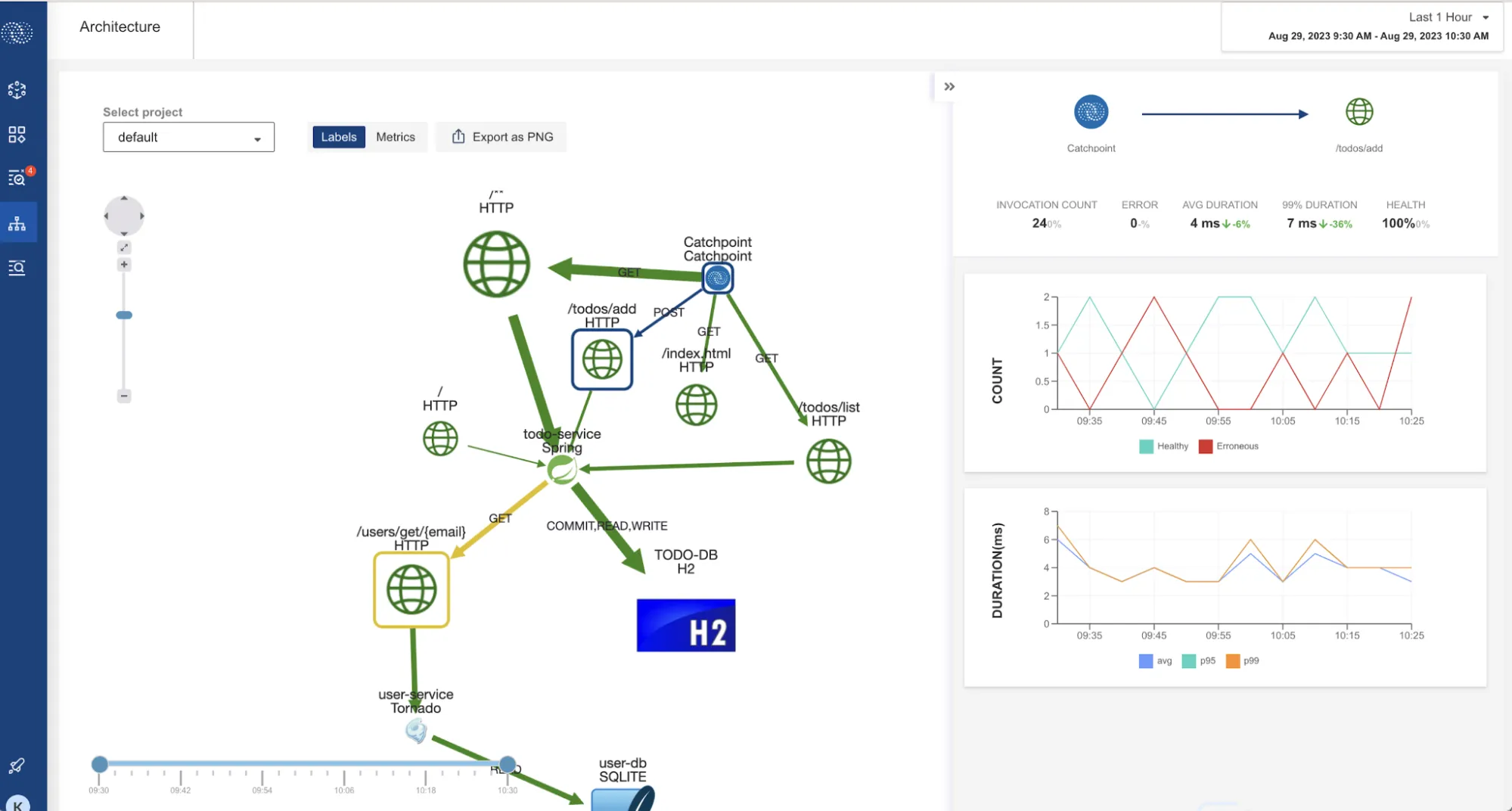
ログ
ログは、詳細で網羅的な情報を提供します。
標準的なAPIログのエントリには、リクエストID、呼び出されたサーバレスコンピュート関数(AWS Lambdaなど)、キャッシュのヒット/ミス率、関連するデータベースクエリなどが含まれることがあります。
この詳細な情報は、イベントログの相関分析や正確なセキュリティ評価に役立ちます。
API監視ツールを評価する際は、中央集約型のログ管理機能が備わっているかを確認することが重要です。
この機能により、APIゲートウェイ、エンドポイント、サービスレイヤー全体のログを統合できます。
これにより、単一のAPIコールが複数のサービスを経由する際の流れを追跡しやすくなり、デバッグを簡素化し、インシデント解決のスピードを向上させます。
また、コンテキスト化されたデータを一元管理することで、API固有の問題とシステム全体の問題を区別しやすくなります。
- サービス依存エラー
-
2023-09-22T12:35:50Z [API-Service] DependencyError GET /service-b/resource
上記のログエントリは、GETリクエストを処理する際に依存サービスで発生したエラーを示しています。
中央集約型ログ管理を利用することで、このような**連鎖的な障害(カスケードフェイル)**の影響を迅速に分析できます。 - レート制限超過
-
2023-09-22T12:35:01Z [API-Gateway] RateLimitExceeded /api/v1/trekkers
このログは、/api/v1/trekkersへのリクエストがレート制限を超えたことを示しています。
中央集約型のログを活用すれば、過剰なリクエストを送信した主体を迅速に特定し、適切な対策を講じることができます。
ログの保存には大量のストレージを必要とするため、無制限にすべてのログを収集することはコスト面で非効率です。
一般的な間違いとして、すべてのデバイスからあらゆる種類のログを常時収集し続けることが挙げられます。
より戦略的なアプローチとして、**トラブルシューティングの価値が高く、本番環境での関連性が高いログを選別して収集すること**が推奨されます。
マルチステップテスト
従来のテストは、主にエンドポイントを個別に検証することが一般的です。
しかし、API監視ツールを選定する際には、単独の呼び出しではなく実際の利用シナリオをシミュレートするマルチステップ負荷テストを実施できるかを確認することが重要です。
包括的なAPIテスト戦略には、以下のようなユースケースが含まれるべきです。
- セキュアで多様な認証方法のサポート
-
APIがさまざまなセキュリティコンテキスト内で適切に機能するかを確認する必要があります。
仮想ユーザ(Virtual User)や、OAuthやJWT(JSON Web Token)などの異なる認証方法をサポートしているかをチェックしましょう。
マルチステップテストでは、これらの異なる認証メカニズムを適切にエミュレートできることが重要です。
これにより、実際のユーザの動作に近いシナリオを再現し、APIの耐久性を評価できます。 - 地理的な一貫性の確保
-
APIのグローバルな信頼性を保証するために、マルチステップテストは異なる地理的なロケーションから実施することが望ましいです。
これにより、どの地域のユーザも同じレベルのサービスを受けられるかを検証できます。
特定の地域でのみパフォーマンスが低下するケースなどを早期に発見するのに役立ちます。 - 多様なユーザプラットフォームへの対応
-
APIは、モバイルアプリ、デスクトップブラウザなど、さまざまなクライアントからアクセスされます。
マルチステップテストでは、この多様性を考慮し、異なるプラットフォームをエミュレートする機能が必要です。
これにより、APIの全体的なパフォーマンスをより包括的に評価することができます。
トランザクション経路全体の監視
API監視における大きな見落としの一つは、組織のネットワーク内にあるコンポーネントにのみ焦点を当ててしまうことです。
しかし、多くのAPIはトランザクションを完了するために、サードパーティサービスやパブリックインターネット上のさまざまな要素に依存しています。
したがって、API応答時間に影響を与えるパブリックインターネットやサードパーティコンポーネントを含む、トランザクション経路全体を分析できる監視ツールを選択することが重要です。
合成(Synthetic)および実ユーザ監視(RUM):現実をシミュレーションし、検証する
前のセクションでは、トレーシング(Tracing)によってトランザクション経路上の問題を特定する方法を説明しました。
ここでは、エンドユーザが実際に体験するパフォーマンスを測定するための合成監視(Synthetic Monitoring)と実ユーザ監視(RUM: Real User Monitoring)について説明します。
APIエンドポイントが正常に機能していても、エンドユーザが遅いUI応答時間を経験することがあります。
これは、トランザクション経路上の予期しない問題によるものかもしれません。
そのため、実際のユーザ体験を測定することが不可欠です。
合成監視は、API環境内で「もしも」シナリオ(What-if scenario)をテストするための制御実験として機能します。
負荷が低い、またはほぼゼロの状態でも、API呼び出しをシミュレートし、パフォーマンスデータを生成できます。
これにより、通常時と負荷がかかった状態の比較を行い、システムの動作を把握できます。
合成監視では、実際のエンドユーザの端末(例:動作の遅いPC)が影響することなく、一貫したトランザクションのシミュレーションを実現できます。
さらに、異なる地理的ロケーションやネットワークプロバイダをエミュレートし、APIが異なる環境でどのように動作するかをテストできます。
例えば、合成テストにより「APIは北米では最適に動作するが、アジアではレイテンシが発生する」といった知見を得ることができます。
合成テストがスクリプト化されたシナリオを提供する一方で、RUMは実際のエンドユーザの操作を測定します。
これにより、リアルワールドでのAPIのパフォーマンスを確認し、問題の特定と改善を行うことができます。
例えば、RUMを用いることで、アジアのユーザが遅延を経験していることをユーザの苦情や遅いトランザクション時間から検証できます。
この2つのアプローチを組み合わせることで、APIの内部的なパフォーマンスと外部的なユーザ体験の両面から包括的な監視が可能になります。
結果として、世界中のユーザが一貫した最適なAPIパフォーマンスを享受できるようになります。
ユーザ中心の監視:プラットフォームやブラウザの違いを超えて
あるAPIが最新のWebブラウザでは正常に動作していても、古いブラウザやあまり一般的でないブラウザでは問題を起こすことがあります。
異なるプラットフォームやブラウザでは、JavaScriptエンジンの処理速度、キャッシュ機構、レンダリングパイプラインなどが異なるためです。
ユーザエージェント解析を活用し、ブラウザやOSごとにメトリクスを分類できるツールを選びましょう。
これにより、データプールが強化され、より精度の高い分析が可能になります。
異なる次元にわたってメトリクスをセグメント化できる機能を探してください。
これは、ターゲットを絞った最適化に役立ちます。
- ユーザのデバイス上の利用可能なメモリ量ごとにパフォーマンスデータをフィルタリングできますか?
- 都市部と地方のユーザ体験を区別できますか?
このような多次元分析により、データをより扱いやすい構造に変え、特定のユーザセグメントに影響を与えている可能性のあるパフォーマンス問題を特定しやすくします。
選択するツールは、クライアントサイドの実ユーザ監視(RUM)をサポートする必要があります。
これにより、実際のエンドユーザの使用状況から得られるメトリクス(ロード時間やプラットフォーム・ブラウザごとのトランザクション成功率など)を取得できます。
見えない遅延の管理: DNS、ISP、およびCDN
遅いDNSルックアップ、ISP経由のルートの遅延、応答しないコンテンツデリバリーネットワーク(CDN)は、APIの応答時間に予期しないレイテンシを引き起こします。
DNS伝播の遅延やCDNキャッシュミスなどの問題を検出するインテリジェントアラート機能を提供するツールを検討してください。
また、各ホップでのネットワークのボトルネックを可視化するトレースルート診断を含むべきです。
OpenTelemetryオープンソースフレームワークのサポート
可観測性シグナルは基盤となりますが、インストルメンテーションは、トレース、メトリクス、ログとしてシステムの内部状態を公開するための基盤を築きます。
Cloud Native Computing Foundation(CNCF)によって2019年にインキュベーションされ、2021年に正式なプロジェクトに昇格したOpenTelemetryは、テレメトリデータを収集、生成、エクスポート、保存するための統合可観測性フレームワークです。
このデータは、その後、さらなる分析のために可観測性バックエンドへ送信されます。
OpenTelemetryツールキットは、この点で2つの重要なユーティリティを提供します。
- データの所有権
-
独自のデータフォーマットやツールから解放され、生成されたテレメトリデータを完全に管理できます。
これにより、ベンダーロックインのリスクや、独自の可観測性ソリューションに対して高額なコストを支払うリスクを排除できます。
最終的に、ユースケースに最適なAPI監視ツールを選択し、移行する柔軟性を提供します。 - 標準化と拡張性
-
単一のAPIと規約を推進し、チームの学習曲線を簡素化します。
トレース、メトリクス、ログを扱う際に、OpenTelemetryフォーマットに準拠することで、異なる可観測性ツールへのデータ取り込みが簡素化されます。
基盤アーキテクチャを変更することなく、データの取り込みを効率化できます。
通常のOpenTelemetryセットアップでは、インストルメントされたアプリケーションコードがOpenTelemetryのAPIを介してスパンとメトリクスを生成します。
スパンは分散システム内でリクエストの流れを追跡するために使用され、一方でメトリクスはシステムのパフォーマンスを測定するために使用されます。
生成されたスパンとメトリクスは、APIパフォーマンスの測定、リクエストの追跡、レイテンシの理解に非常に役立つ生データを提供します。
しかし、このフレームワークの強みは単なるデータ生成にとどまりません。
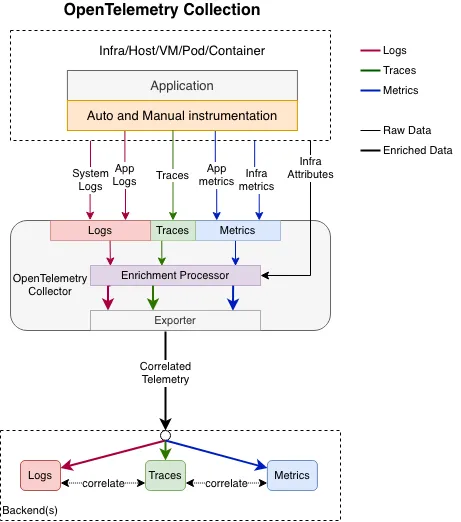
OpenTelemetry SDKは、サンプリングガイドラインを適用し、データをさまざまなプロセッサを通じてルーティングします。
サンプリングルールは、収集されるデータ量を削減し、一方でプロセッサはデータを変換および強化し、エクスポート前に適切な形に整えます。
このデータが可観測性バックエンドにエクスポートされると、APIの健全性を監視し、パフォーマンスメトリクスを追跡し、異常に対するアラートを設定することができます。
その利点は、APIを含むシステムのさまざまな部分からのトレースとメトリクスを統合し、単一の可観測性プラットフォーム上で表示、分析、相関付けることができる可能性にあります。
サービスカタログとAPIドキュメントのサポート
サービスカタログは通常、利用可能なさまざまなサービス(APIを含む)、それらに誰がアクセスできるか、他のサービスとどのように相互作用するかを説明する、より広範な視点を提供します。
API監視ツールを評価する際には、サービスカタログとOpenAPI Specification(OAS)との互換性と統合性を考慮してください。
APIの作成、管理、およびリアルタイムの変更をどの程度サポートしているかを評価してください。
OpenAPI Specification(OAS)は、HTTPベースのAPIの設計図を提供し、開発者と機械の両方に対応します。
この二重の機能により、APIドキュメントの作成だけでなく、実装ロジック、SDKの作成、モックサーバーを使用したテストを1つのOpenAPIファイルから実行できます。
監視戦略にOpenAPIを採用することで、OAS記述ファイルから監視チェックを自動生成し、明確なバージョン管理を実現できます。
これにより、非推奨(Deprecated)や古いAPIバージョンも監視対象から外れることがありません。
OpenAPIファイルには、APIエンドポイントやリクエスト/レスポンスの構造に関するすべての詳細が含まれています。
この情報は、監視ツールにとってAPIの挙動を検証するために必要なすべてのデータを提供します。
ツールはOpenAPI仕様に基づいて自動的に監視チェックを設定し、APIが常に許容範囲内の時間で動作していることを確認できます。
OpenAPIと統合できるAPI監視ツールを選択することが重要です。
これにより、異なるカタログ情報が分断され、時間とともに一貫性を失うことを防ぐことができます。
単一の情報源(Single Source of Truth)を確立することで、APIの管理と監視の整合性を確保できます。