
インシデント・レビュー - AWSサービスを使用するアプリケーションでAWSの停止により応答時間が急増
翻訳: 竹洞 陽一郎
この記事は米Catchpoint Systems社のブログ記事 Incident Review – AWS Outage Led To Spikes In Response Times For Applications Using AWS Servicesの翻訳です。
Spelldataは、Catchpointの日本代理店です。
この記事は、Catchpoint Systemsの許可を得て、翻訳しています。
8月31日(火)、西海岸の広い地域(US-West-2リージョン)のユーザが、レスポンスタイムの大幅なスパイクによる影響を受けました。
AWSの最も重要なサービスのうち、LambdaやKinesisなどが影響を受けました。
SREチームは、サービスレベル指標(SLI)やサービスレベル目標(SLO)を気にしており、この実践はSREチームにとって必須です。
しかし、SRE の創始者であるGoogleとは異なり、ほとんどの企業は、インフラやサービスをAWSやGCPなどの他のプロバイダとCDN(複数のCDN)に依存しています。
つまり、自社のアプリケーションやサービスにSLIやSLOが必要なだけでなく、プロバイダやベンダーをよく見極める必要があるのです。
というのも、ほとんどの企業のSLOやSLIは、使用しているベンダーやプロバイダに依存しているからです。
クラウドでホストされている場合、クラウドベンダーが問題を抱えていれば、それは、あなたがSLOを達成できないという事を意味します。
ベンダーのSLOを監視することで、ベンダーのSLOやシステムアーキテクチャへの影響を理解し、目指すレベルの体験を適切に提供することができます。
火曜日に発生したAWSのインシデントは約4時間続き、Webサイトのダウン、サイトの機能の使用不可、アプリケーションへのログインの困難など、一連の頭痛の種がUS-West-2地域全体に広まりました。
企業、開発者、DevOpsチームは、ソーシャルメディアやニュースサイトでその怒りを共有しました。
コメントを寄せたのは、The Seattle Times、大手ゲーム会社のZwift、SaaSプラットフォームのUbiquitiなどです。

CatchpointがAWSの障害をいち早く検知してアラートを出す
このブログ記事では、何がいつ、どのように起こったのかを明確にお伝えすることを目的としています。
Catchpointのプロアクティブ・モニタリング・プラットフォームでは、火曜日の午前11時(PST)にお客様の問題を最初に検知しました。
データ分析の結果、米国西海岸地域で広範囲にわたる接続障害が発生していることがわかりました。
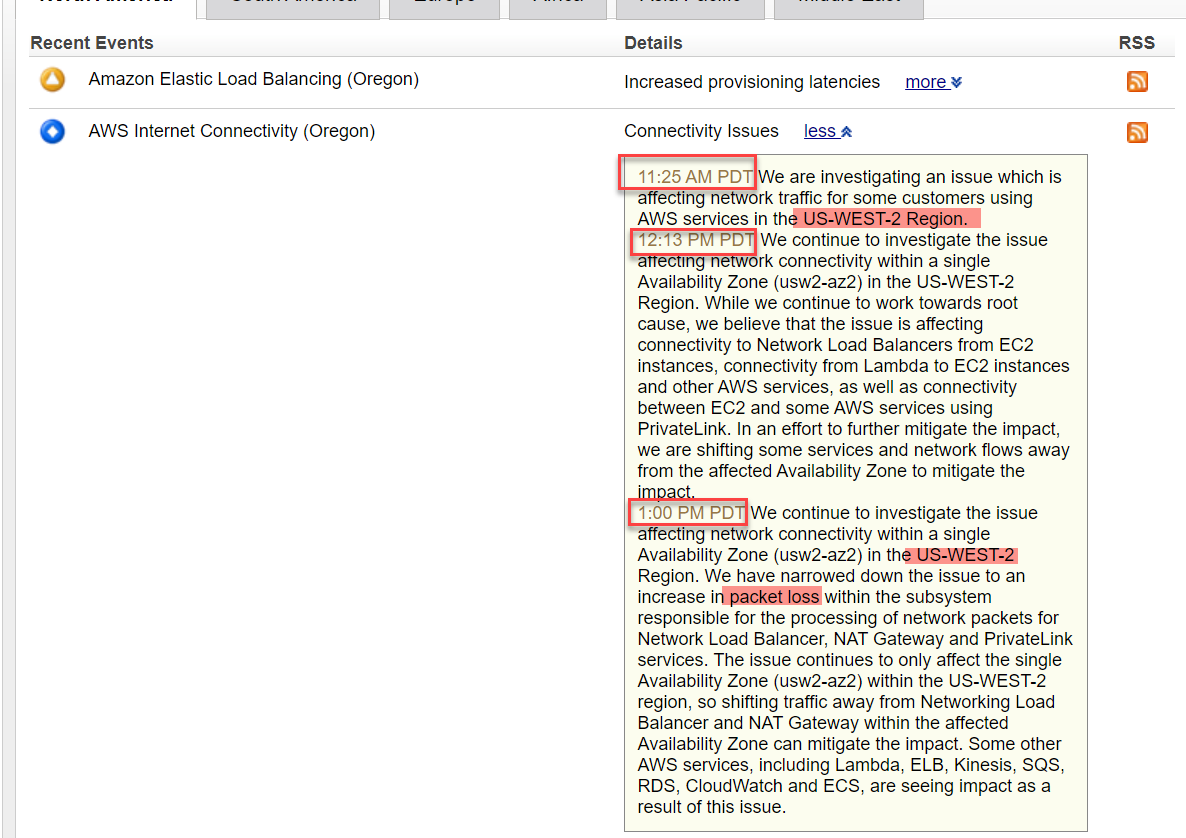
AWSが問題を認識する25分前に、私たちは直ちに最初の警告を発しました。AWSがこの問題を調査していることをステータスページで最初に言及したのは、11時25分(PST)でした。
2年前のAWSのDDoS問題でも同じようなことがありました。
私たちは、彼らよりも5時間早く問題を検知しました。
当時、Catchpoint社から警告を受けた後、あるトップカスタマーがAWSのサポートに問題について問い合わせたところ、AWSのサポートはインシデントが発生していることを知りませんでした。
他のオブザーバビリティ・プラットフォームとは異なり、Catchpoint社はクラウド・プロバイダにホストされていないため、クラウド・プロバイダが自社のソリューションに影響を与えるインシデントが発生しても、当社には影響がありません。
当社のプラットフォームは継続して動作し、何か問題を検出したらすぐにアラートを出します。
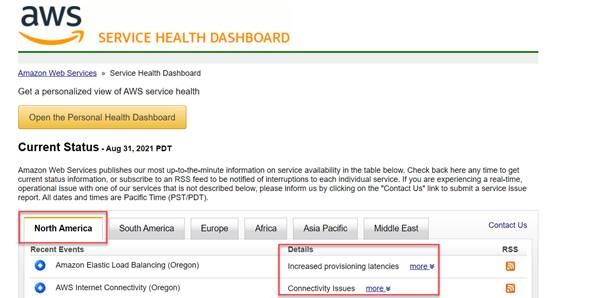
AWSステータスダッシュボードで、レイテンシーの増加と接続性の問題が判明
AWSサービスヘルスダッシュボードでは、オレゴン州のAmazon Elastic Load Balancingへのプロビジョニングレイテンシーの増加と、同じ地域でのAWSインターネット接続の問題が明らかになりました。
影響を受けたAWSサービス
影響を受けたAWSサービスは、Lambda、ELB、Kinesis、RDS、CloudWatch、ECSです。
AWS-WEST-2リージョンで発生したインシデント
影響を受けたのはUS-WEST-2リージョン、つまりオレゴン州(アマゾンの本社があるシアトルを含む)のユーザのみです。
西海岸には他に2つのAWSリージョンがあります。
北カリフォルニアとAWS GovCloudです。
しかし、どちらも影響を受けませんでした。
根本原因が判明: ネットワーク接続の問題
午後2時26分(PDT)、AWSはUS-WEST-2リージョンのネットワーク接続に影響を与えている問題の根本原因を、「ネットワークロードバランサーのネットワークパケットの処理を担当するサブシステム内のコンポーネント」と特定しました。
これにより、NTゲートウェイとプライベートリンクのサービスに障害が発生し、ヘルスチェックが正常に処理されなくなり、さらにパフォーマンスが低下しました。

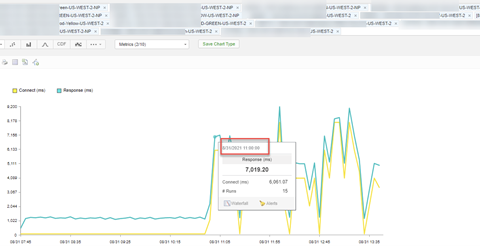
Catchpoint社のデータセットに戻ると、障害の原因がネットワーク接続の問題であることを検証するために、追加のメトリクスを含めることもできます。
Catchpoint社は50以上のメトリクスを提供しており、問題を特定のコンポーネントに絞り込むことができます。
そして、「問題を引き起こしているのは、ネットワークなのか、それともアプリケーションなのか?」という疑問に答えることができます。
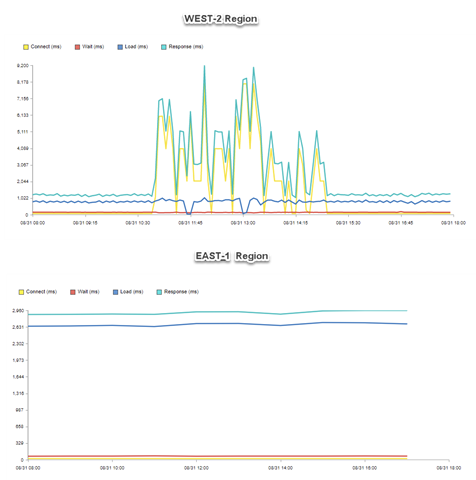
このケースでは、ネットワークの影響を受けるサーバへの接続時間が長くなったために、全体のレスポンスタイムが急上昇したことがわかります。
しかし、サーバの処理時間に関連する負荷や待ち時間は、アプリケーションやサーバ側の問題を示すものですが、急上昇することなく横ばいになっています。
このような障害を検知するためのエンド・ツー・エンドの監視は実施されていますか?
この夏の最新の障害(6月に発生したFastlyの障害についてはこちら、火曜日に発生したAkamaiのパフォーマンス低下の問題についてはこちら)は、企業が監視、観測、フェイルオーバー戦略を含む自社のインフラ設定を評価、検証する上での注意点となります。
また、盲点となる可能性のあるクラウドのみの監視戦略に頼らないようにすることも重要です。
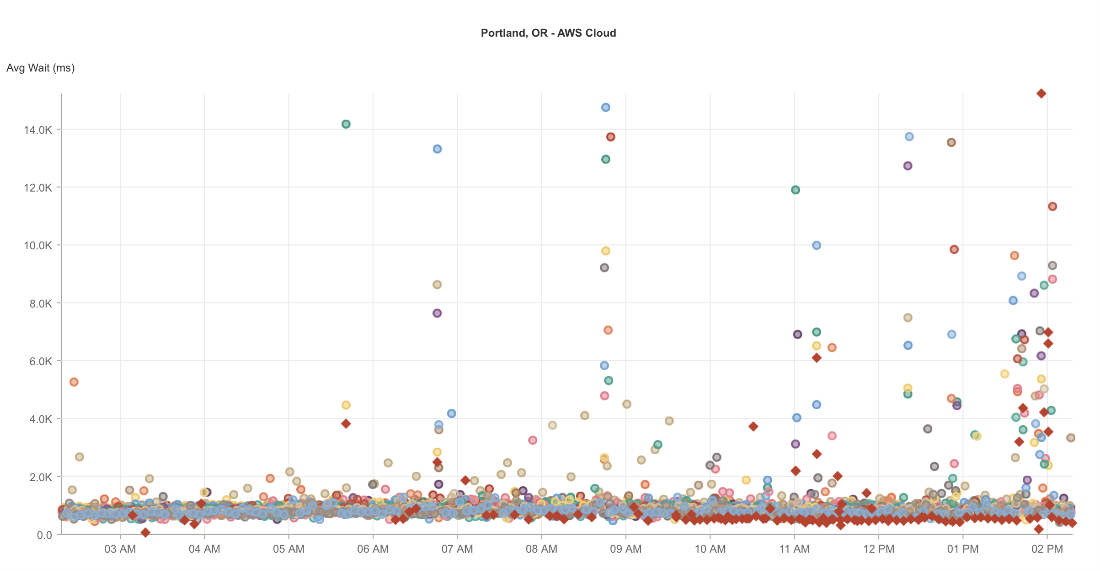
上の画像からわかるように、ポートランドのAWSノード(影響を受けたリージョン)のモニタリングデータを見てみると、レスポンスタイムのスパイクが観測されました。
クラウド上だけの場所から監視している場合、クラウド・プロバイダに問題があると、その監視では問題があるように見えてしまいます。
言い換えれば、この地域から監視していても、その地域でホストされているサービスやインフラを持っていなかった場合、火曜日に問題が発生したことを知らせるアラートを受け取っていたかもしれません。
つまり、これらは偽陰性であり、オンコール・チームは不必要なアラートを受け取っていることになります。
全体的なモニタリングとオブザーバビリティ戦略を導入することで、ノイズを減らし、時間とリソースを節約することができます。
Catchpoint社は、業界最大規模のクラウド・ノードのネットワークを有していますが、それだけでなく、エンド・ユーザ・エクスペリエンス全体をシミュレートしています。
つまり、ローカルISP、主要なバックボーン、モバイルネットワーク、そしてエンドユーザがサイトにアクセスしたりアプリを使用したりする際に接続するクラウド上にノードを設置しています。
ホリスティック(総合的・全体的)なモニタリングとオブザーバビリティ戦略は、どこからでもリアルタイムで障害やパフォーマンスの問題を検出できることを意味します。
単一障害点の防止
最終的に、サービスレベル指標とサービスレベル目標は、自社のサービスだけでなく、サードパーティ・プロバイダ、そして単一障害点となるインフラの全てに適用されます。
これが、法務部門がCatchpoint社のようなSaaSプロバイダを含むクラウド・プロバイダとの間でSLA条項の締結を保証する理由です。
オンデマンド・ウェビナー「The Journey to SLO Maturity」では、SLOに基づいた意思決定によってユーザがビジネス・ゴールを達成した実際のシナリオを紹介していますので、ぜひご覧ください。