
インシデント・レビュー - 12月に入って3回目 AWSの障害-泣きっ面に蜂
翻訳: 島田 麻里子
この記事は米Catchpoint Systems社のブログ記事 Incident Review – The Third AWS Outage in December: When it Rains, it Poursの翻訳です。
Spelldataは、Catchpointの日本代理店です。
この記事は、Catchpoint Systemsの許可を得て、翻訳しています。
以下は、2021年12月22日に発生したAmazon Web Services(AWS)の障害を分析したものです。
AWSの大規模な障害が発生した際、もちろん三度目の正直とはいきませんでした。
この3週間で3回目の障害が発生し、AWSのステータスページによると、パブリッククラウドの大手企業が障害を報告しており、今回の障害は「米国のEAST-1地域の1つのアベイラビリティゾーン(USE1-AZ4)内の1つのデータセンターで発生した」とのことです。
インシデント・レビュー - AWSの障害でAmazonを含む主要なオンラインサービスがクラッシュ
インシデント・レビュー ‐ 今週もAWSの障害が発生
Catchpointでは、AWSの発表より24分早い午前7時11分(米国東部時間)に初めて問題を確認しました。
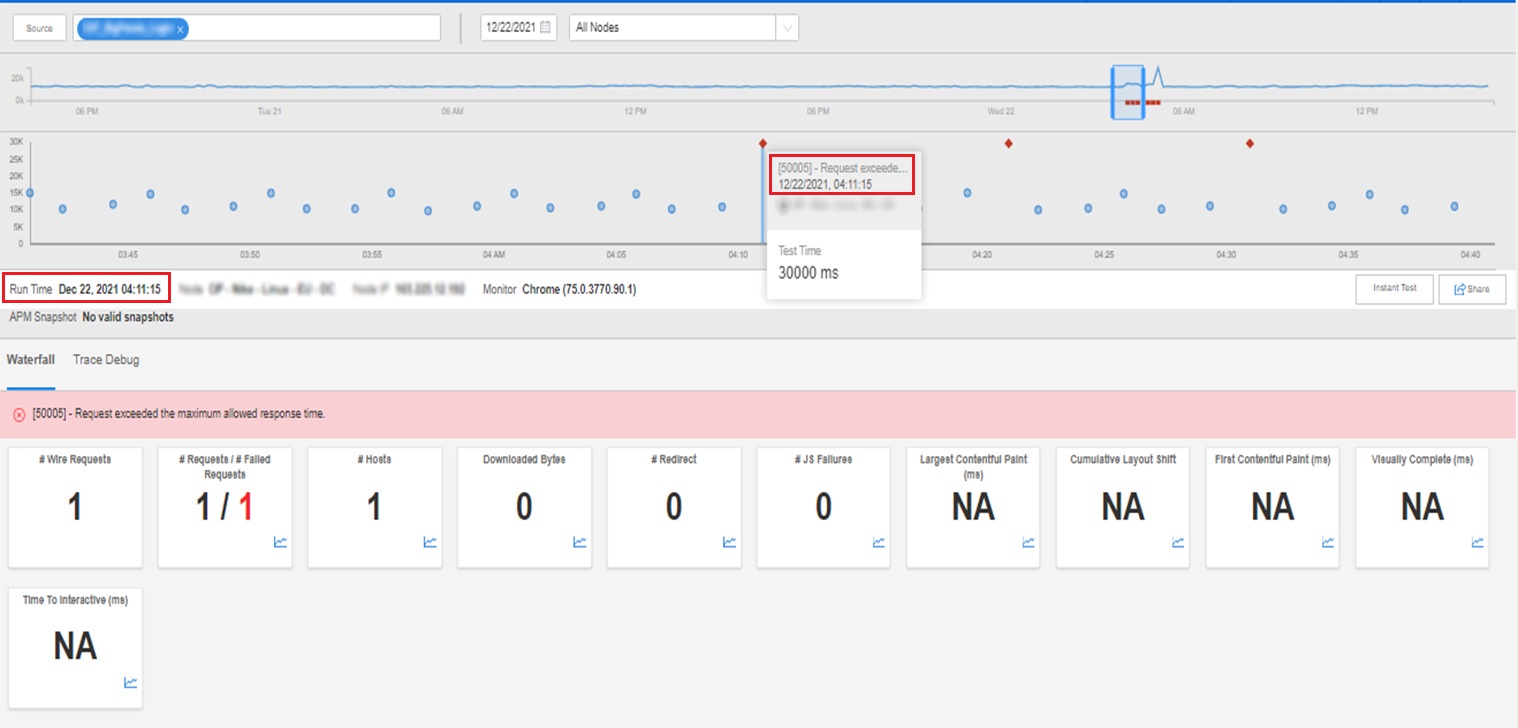
今回もまた、この障害が引き金となり、巻き添え被害の不幸な連鎖が起こりました。
AWSの障害をさらに詳しく調査したところ、Slack、Udemy、Twilio、Okta、Imgur、JobviteなどのAWSの顧客に問題が発生していることがわかりました。
ニューヨークの裁判所のWebサイトでも確認されました。
停電自体は比較的短いもので、アマゾンは午前9時51分(米国東部時間)に停電が復旧したことを報告しました。
しかし、本格的な回復にはそれ以上の時間がかかりました。
同社は午後12時28分(米国東部時間)に「残りの大部分のシステムへの基本的な接続を回復した」と報告しました。
不具合は主にボストン、ニューヨーク、フィラデルフィア、トロントの周辺に集中していました。
回復への長い道のり
一部のAWSユーザでは、この障害に関連した問題が引き続き発生しており、付随的な影響は根強く残っています。
例えば、Slackのステータスページでは、この問題が完全に解決したとマークされたのは、米国東部時間の午後8時26分でした。
特に注目されたのは、AWSと深い関係にあるクラウドコミュニケーションプラットフォームサービスのTwilio社が被った障害です。
同社がこの問題を最初に指摘したのは、米国東部時間の午前7時17分でした。
当社の監視システムは、複数のサービスで潜在的な問題を検出しました。
当社のエンジニアリングチームは警告を受け、積極的に調査を行っています。
詳細な情報が入り次第、更新いたします。
そこから次々と状況が更新されていきましたが、事態が完全に解決したのは17時間後の午前12時38分(米国東部時間)でした。
下図に示すように、AWSの障害により、一部の顧客には完全なダウンタイムが発生しましたが、他の顧客には全期間を通じて断続的な障害が発生しました。
多種多様な影響を受けた様々なサイトで見られた症状は、彼らのシステムがAWS上に構築されており、AWSの前にあるCDNに依存しているために生じました。
一方で、影響を受けたサイトやアプリケーションの中には、システムの構築方法や復旧に必要なものが異なっていたため、AWSの障害から完全に復旧するまでに時間がかかったものもありました。
あるケースだと、Jobviteは彼らの問題を完全に解決するのに24時間かかりました。
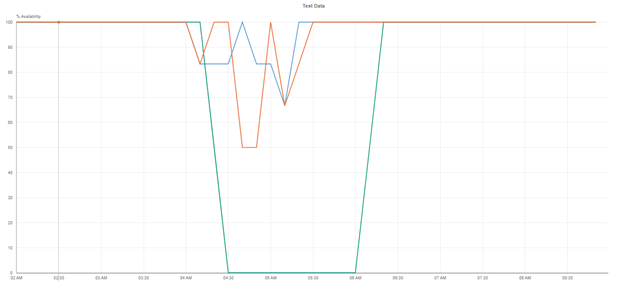
ほとんどのサイトで回復が始まる前に、この状態が約2〜3時間続きました。
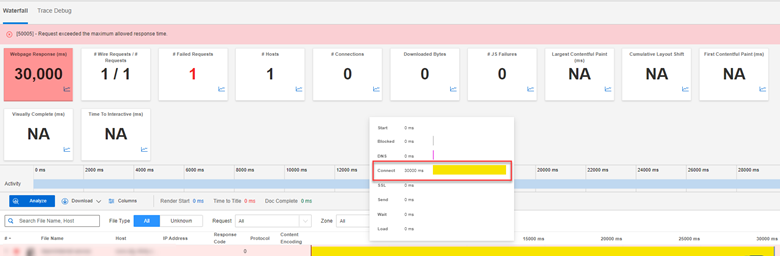
一部のサイトでは、AWSサーバへの接続に問題が発生しました。
以下のスクリーンショットは障害発生時に撮影されたものですが、クライアントはサーバとの接続を確立しようとしており、30秒後に失敗しました。
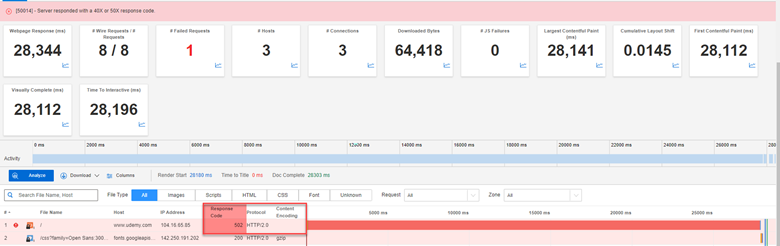
Udemyのような他のサイトでは、bad gatewayやgateway timeoutのエラーが返されました。
以下のスクリーンショットは、サーバがリクエストに対して502レスポンスコードを返したことを示しています。
502 Bad Gateway Errorは、接続しているWebサーバが他のサーバからの情報を中継するプロキシとして動作しているが、他のサーバから不正又は無効なレスポンスを受け取ったことを意味します。
デジタルドミノ効果
この3週間のAWSの障害を振り返ってみると、それぞれ根本的な原因は異なります。
しかし、これらの事件はいずれも、一企業の問題がオンラインサービスに及ぼす深刻なダウンストリーム効果を明確に示しています。
実際、Catchpoint社は顧客のSaaSアプリケーションの1つに障害が発生したことを動作中のドミノ効果のデジタルイラストとして検知しました。
です。
肝心なことは何でしょう?
企業の可用性と事業継続性を確保することは、一人でできることではありません。
パートナー、顧客、サードパーティ・プロバイダに起因する問題が自社のシステムをダウンさせる可能性がある場合、拡張されたデジタル・インフラをサポートするために設計されたコラボレーション戦略を構築する必要があります。
そのためには、包括的なオブザーバビリティが重要です。
もっと詳しく知りたいですか?
障害を予防、準備、対応するためのベスト・プラクティスをもっと知りたいと思いませんか?
こちらをダウンロードしてご覧ください。
2021 Internet Outages: A compendium of the year’s mischiefs and miseries – with a dose of actionable insights