
CatchpointのIPMプラットフォームがAmazonの2日間の検索障害を検出した方法
翻訳: 島田 麻里子
この記事は米Catchpoint Systems社のブログ記事 How Catchpoint’s IPM Platform Detected Amazon’s Two-Day Search Issueの翻訳です。
Spelldataは、Catchpointの日本代理店です。
この記事は、Catchpoint Systemsの許可を得て、翻訳しています。
全てのインターネット障害がWebサイトをダウンさせるわけではありません。
中には、一部のユーザにしか影響を与えないものや、サイト機能の一部にしか影響を与えないものもあります。
さらに、これらは相対的に「隠された」性質を持っているため、苦情を出すユーザも少なく、企業は必ずしもすぐそれに気づかないかもしれません。
しかし、このような障害は深刻な結果を招く恐れがあるため、できるだけ早く発見し、問題の軽減と解決に努めたいものです。
検出は、口で言うほど簡単なことではありません。
多くのサイトでは、基本的な稼働率監視(場合によってはトップページの監視のみ)に頼っているため、断続的あるいは部分的なサイト障害が発生している企業では、その検知を見落とす可能性があります。
2021年12月初め、私たちのトランザクション監視の機能により、まさにそのような問題がAmazonで検出されました。
Amazonの検索失敗の検出
Catchpointのシステムは、2022年12月05日12時51分02秒(米国東部時間)にAmazonの検索機能に関する初期障害の検出を始めました。
以下に示すように、これらは断続的に発生しました。
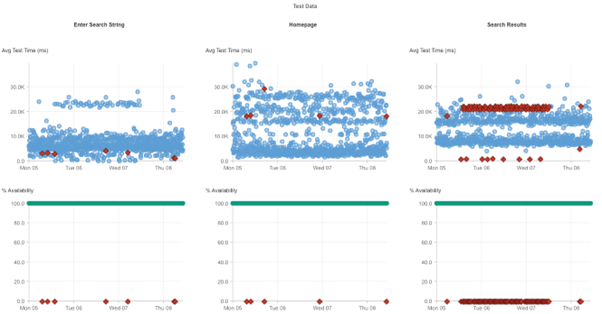
このエラーは2022年12月7日11時13分44秒(米国東部時間)まで22時間続き、断続的に発生して、Amazonのデスクトップおよびモバイルサイトで商品検索を行おうとしている世界中のユーザに引き続き影響を及ぼしました。
当社のSyntheticのデータによると、全世界のユーザの約20%が全時間帯で影響を受けています。
ある一定の割合のユーザにとっては、22時間の間、検索が完全にダウンし、使用不能となりました。
エンドユーザがサイト上で購入する商品を検索しようとすると、上記のようなエラーメッセージが表示されました。
このようなネガティブなユーザ体験は(数年前にも同様の事象を検知しています)、ブランドの評判、ひいては影響を受けた企業の収益に深刻な影響を与える可能性があります。
インターネット・スタックのどの層に責任があったのか?
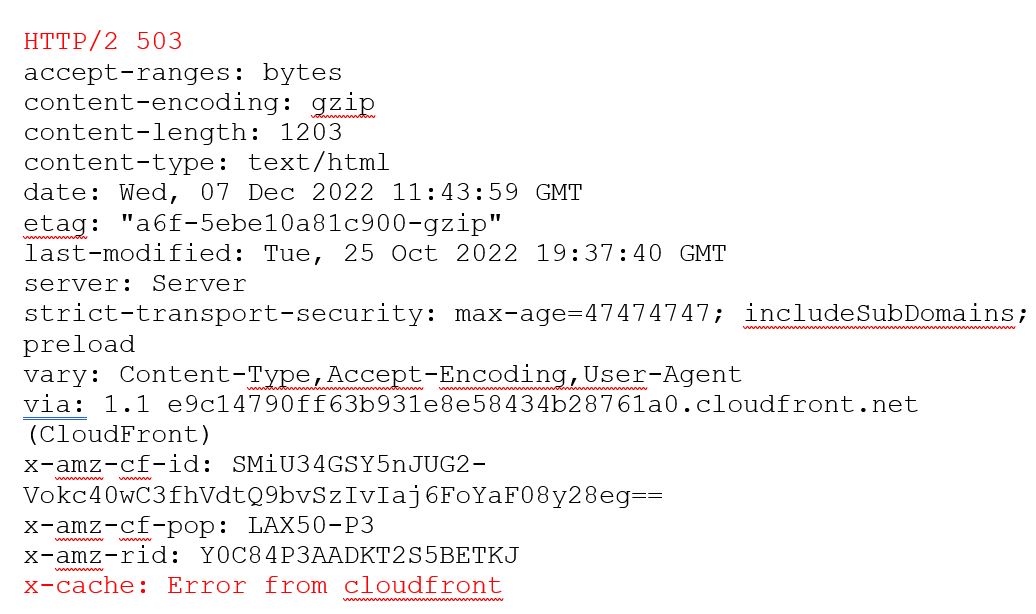
Catchpointのインターネットパフォーマンス監視・プラットフォームは、インターネット・スタックのどの層がこの問題の原因であるかを正確に特定することができました。
この場合、ヘッダー(下記参照)を見て、問題はAmazon CloudFrontからHTTP 503が返された結果であることがすぐに確認できました。
(HTTP 503……HTTPステータスコードの一つ。一時的にサーバにアクセスできないことを示す。)
問題の迅速な検出と、根本的な原因を素早く特定する能力により、発生した障害をすぐに確認し、トラブルシューティングすることができます。
この問題は、最終的にAmazonのグローバルユーザの5分の1に影響を与えましたが(グローバルな収益への影響を想像してみてください)、IPMソリューションがあれば、はるかに迅速に解決できたはずです。
オブザーバビリティ・ゴールデントライアングルへの挑戦
近年、APMではログ、トレース、メトリクスという「オブザーバビリティ・ゴールデントライアングル」に大きな注目が集まっています。
ゴールデントライアングルのみに着目したアプローチの大きな問題点は、断続的に発生するインシデントの検出に遅れが生じることです。
ゴールデントライアングルは素晴らしいものですが、問題を早期に発見するためには、それだけに頼るのでは大きな欠点があります。
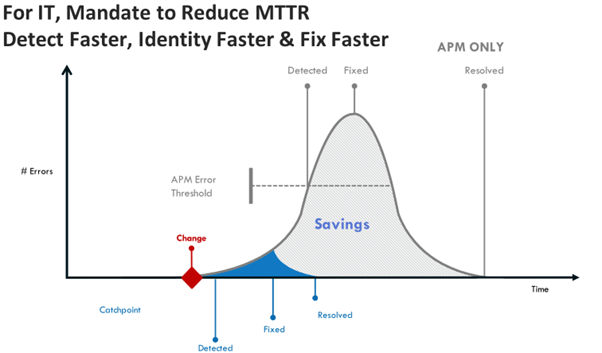
中でも重要なのは、高いエラー閾値に起因する問題の検出の遅れです。
ログやトレースに依存して問題を検出するシステムの多くは、エラーの閾値が高く設定されています。
これは、特にヒット数が多い状況において、誤検出を避けるためというのが大きいです。
しかし、上の図を見ると、APM側で設定した閾値が高いために、変更後の問題の検出が遅れてしまうことがわかります(例えば、デプロイの失敗によるエラーの増加など)。
なぜここでIPMが重要なのか
インターネットパフォーマンス監視、特にプロアクティブ・監視を中心とした戦略が重要になるのはまさにこの時です。
なぜなら、設定される閾値が低く、それによって私たちができることがあるからです。
- エンドユーザに影響が及ぶ前に、より早い段階で問題を検出することができる
- トラフィックの100%に影響を与えていないかもしれない断続的な問題を検出する(Amazonの検索障害のケースがこれでした)
プロアクティブシンセティック監視は、インターネット・スタックの無数のコンポーネントに対してより厳しい閾値を設定することができ、極めてターゲットを絞った監視が可能です。
ベスト・オブ・ブリードな監視戦略が必要な理由
このような障害が発生した場合、特定の活動に特化した最善のソリューションを活用した監視戦略をとることが非常に重要です。
-
以下を含んだIPM
- プロアクティブ監視により、インターネットスタックのどの層から問題が発生し、どの機能が影響を受けているかを把握し、問題を迅速に検出する
- ビジネス的な観点からの影響(ページビュー、収益、コンバージョン、地域的な影響)を解明するためのリアクティブ・監視
- APM(ログ、トレース、メトリクス)により、影響を受ける可能性のあるシステム内部コンポーネントをより深く理解する
Google Cloudの信頼性アドボケイトであるSteve McGhee氏が、Catchpointの2023年SREレポートの結論で強調したように、専門家が自分のタスクを最適な方法で達成するために単一のソリューション、ツール、プラットフォームに決して依存しないのには理由があります。
「熟練労働者、あるいは『オペレーション』に関しては、将来必要と思われるものを先に決めてしまうのではなく、適切なタイミングで適切なツールに手を伸ばせるようにすることが必要です。」とスティーブは書いています。
Catchpointの計測・監視サービスについてはSpeeddataのトップページをご覧ください。