
2023年の障害を防ぐために
翻訳: 島田 麻里子
この記事は米Catchpoint Systems社のブログ記事Preventing Outages in 2023の翻訳です。
Spelldataは、Catchpointの日本代理店です。
この記事は、Catchpoint Systemsの許可を得て、翻訳しています。
ここCatchpointでは、過去18ヶ月間にわたる障害に焦点を当てたホワイトペーパー「2023年の障害を防ぐために―最近の失敗事例から学んだこと」を発表したばかりです。
CatchpointのIPM(Internet Performance Monitoring)プラットフォームが特定した10件の大規模・断続的な障害について深く掘り下げ、データから見えてくるものを検証しています。
完全なる障害から断続的なものまで
2021年12月に発生したAWSの3連続に及ぶ障害から、Facebook、Instagram、WhatsApp、および相互に関連するサービスをダウンさせた2021年10月の障害まで―これらの障害は、インターネットの巨大企業と、私たちが直面したITレジリエンスの最大の失敗のいくつかに及んでいます。
さらに、見逃しがちな断続的な障害についても見ていきます。
2022年12月には、Amazonの検索機能が2日間にわたり全世界のユーザの20%で使用できなくなるなど、規模は小さいものの、これらの障害は主要な機能に影響を及ぼしています。
これらのブランドにとって、このような重大な事件が発生したときに問題となるのは、収益や純利益だけでなく、会社の評判や汚名です。
だからこそ我々は、お客様の目や耳としての責任を重く受け止めています。
障害の発生を完全に防ぐことは誰にもできませんが、適切な戦略を講じることで、再びニュースになってしまう可能性があった事件の影響を、企業が大幅に軽減できることを、私たちは繰り返し目の当たりにしてきました。
大きな影響を与える障害を防ぐには
ホワイトペーパーのそれぞれの記事には、各インシデントに特有の重要なポイントが記載されています。
また、ホワイトペーパーの冒頭では、障害による深刻な影響を防ぐために、当社のエンジニアと最高製品・技術責任者が語った6つの重要な教訓を紹介しています。
このブログでは、最初の2つ―「1.重要なことを監視する」「2.インターネットスタックをマップする」に焦点を当てます。
1.重要なことを監視する
これはお決まり事のように聞こえるかもしれませんが、Catchpointを立ち上げるきっかけとなったのは、共同創業者が他の会社で可視性のギャップに悩まされたことでした。
彼らのビジョンは、継続的に成長するグローバルなオブザーバビリティ・ネットワークを搭載した、比類ない広さと深さを持つIPMプラットフォームを構築することでした。
CatchpointのCEO兼共同創業者のMehdi Daoudi氏は、DoubleClick社でクオリティ・オブ・サービス部門を立ち上げました。
毎日何十億ものトランザクションを配信するDARTインフラを監視するため、社内外の監視ソリューションの構築、展開、利用を担当したのです。
この部門をゼロから立ち上げた背景には、彼が身をもって体験した2つの重要な事柄がありました。
従業員への影響(危機的状況に陥り、何がどこで起こっているのかわからない...せっかく多くの監視ツールがあったのに)。
お客さまへの影響、広告の発注・広告の配置・メディアのアップロードなどの時間的なプレッシャーにさらされる広告運用チーム、そして問題が発生するたびに、彼らの生活への影響を目の当たりにしてきました!
やり方を変える必要がありました。
これらの人々の生活をより良くする必要があったのです。
この2つの経験は、私のDNAに刻み込まれたものであり、その見解です。「常にエンドユーザの視点から監視しなければならない!」
MehdiがCatchpointを設立し、初期のチームが当社のIPMプラットフォームを構築したとき、彼らは従来のWeb Syntheticに留まることはありませんでした。
Internet Syntheticを生み出し、現在では40以上のテストタイプや無限の監視オプションが利用できるようになりました。
つまり、お客様が問題を抱えているときはいつでも、トリアージ、根本原因の特定、障害切り分けを加速させ、エンドユーザの視点から問題を理解することができるのです。
2.インターネットスタックをマップする
お客様からいただいた名言の中に、ユーモアのセンスに溢れたものがあります。
「Catchpointは、私たちのオペレーションチームが手に入れられるものの中で、最もナイキルに近いものでしょう」
(訳注…ナイキル:風邪のあらゆる症状に効く米国の総合感冒薬)
しかし、Carl Levine氏(大手ネットワーク企業NS1社の当時のシニアテクニカルエバンジェリスト)の軽妙な語り口の裏には、運用チームにとって可視性のギャップはあまりにも過度なストレスとなり、トラブルシューティングのプロセスを遅らせるという深刻な指摘がありました。
そう、私たちが直接コントロールできる領域、つまりコンテナ、VM、ハードウェア、そしてコードを監視する必要があるのです。
しかし、障害に立ち向かうには、APMでは決して十分ではありません。
ITチームはIPM、つまりアプリケーションスタックを超えてインターネットスタックまで可視化する必要があります。
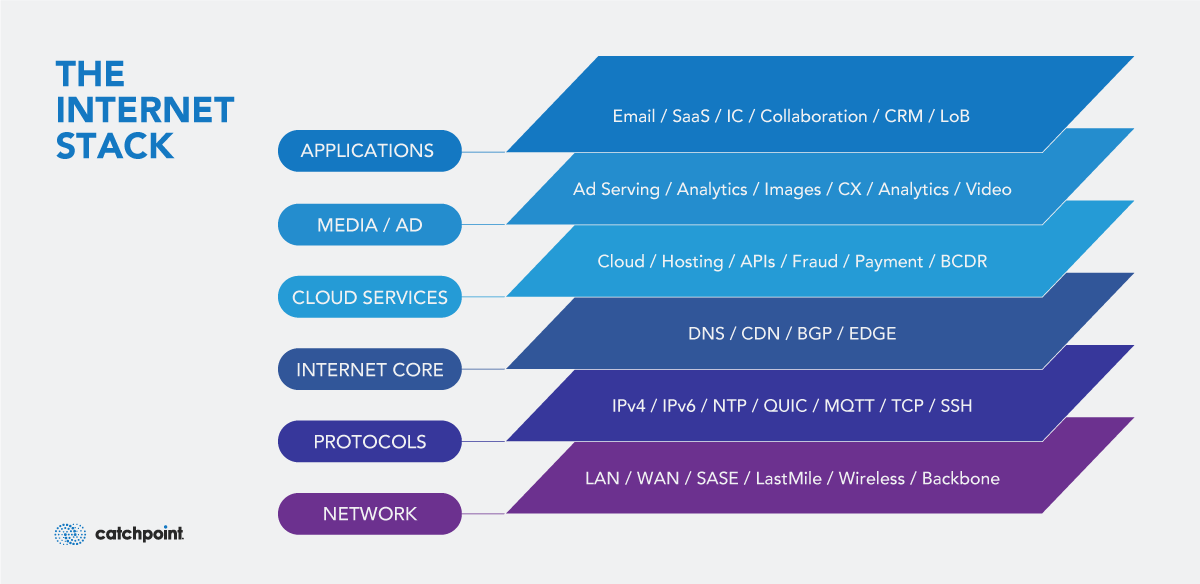
ご覧のように、インターネットスタックは、「システムおよびサブシステム」「アプリ、サービスとマイクロサービス」「ファイバー、ブロードバンド、ローカルISP、モバイルネットワークにまたがる外部ネットワーク配信」「データセンターまたはクラウドプロバイダ」「サードパーティAPI」「DNSプロバイダ」「API」など、お客様がサービスを提供するために依存するすべてのもので構成されています。
インターネットは複雑で、日々よりその複雑さを増していますが、監視の方法はシンプルで、これらのコンポーネントの一つ一つを確実に監視することです。
何故か? あなたのビジネスを守るためです。
インターネット上で1つのページを読み込むには、インターネットスタック上の複数の関係者が複雑に絡み合った振り付けが必要です。
DNSやCDN、APIの不具合など、その中に弱点があると、波及効果で障害や遅延の問題に発展することがあります。
お客様に見えるのは動作していないページだけですが、その背後にはこれらのコンポーネントのいずれか1つの問題(または内部の問題)がある可能性があります。
運用チームが睡眠時間を確保し(インシデントが発生した場合にも、冷静な判断で積極的に影響を軽減することができます!)、監視のギャップをなくすことが唯一の方法です。
そうすれば、問題を解決する前にユーザがTwitterやLinkedInでその問題を報告するのを避けることができます。
最重要ポイント
自社のシステムを監視するように、これらのコンポーネントの出力とパフォーマンスを監視することで、インターネット・レジリエンスを実現するのです。
最終的には、ユーザ、そして収益が、関係なく影響を受けることになります。
さらに詳しく
ホワイトペーパー「2023年の障害を防ぐために―最近の失敗事例から学んだこと」をお読みください(登録不要)。