
AWSの「12月の障害祭り」から何を学ぶか?
翻訳: 島田 麻里子
この記事は米Catchpoint Systems社のブログ記事 What Can We Learn from AWS’s December Outagepalooza?の翻訳です。
Spelldataは、Catchpointの日本代理店です。
この記事は、Catchpoint Systemsの許可を得て、翻訳しています。
2021年に発生した相次ぐインターネットの停止や混乱は、インターネットのエコシステム同士がいかに繋がっていて、相対的に脆弱であるかを示しています。
例を挙げるなら、12月に発生したAmazon Web Services(AWS)の3連続の障害です。
この障害は「サービスが失敗するのに大きいも小さいもない」という事実を如実に物語っています。
US-EAST-1地域で発生したこの大規模な障害により、数百万人のユーザが影響を受け、Amazon、Amazon Prime、Amazon Alexa、Venmo、Disney+、Instacart、Roku、Kindle、その他複数のオンラインゲームサイトなど、主要なオンラインサービスが停止しました。
この障害により、倉庫や配送業者、Amazon Flexの従業員が利用するためのアプリケーションも停止しました――年末商戦のホリデーシーズンに、です。
AWSのステータスダッシュボードには、障害の根本原因が複数のネットワーク機器の障害であることが記されていました。
オレゴン州のUS-West-2地域とカリフォルニア州北部のUS-West-1地域で発生したこの騒動は約1時間続き、Auth0、Duo、Okta、DoorDash、Disney、PlayStation Network、Slack、Netflix、Snapchat、Zoomなどの主要なサービスが停止しました。
AWSのステータスダッシュボードによると、この問題は、AWSバックボーンの一部とインターネットサービスプロバイダの一部との間で発生したネットワークの混雑が原因で、ネットワーク外の混雑に対応して実行されたAWSのトラフィックエンジニアリングによって引き起こされました。
とのことです。
この障害は米国-EAST-1リージョンのデータセンターの停電が引き金となり、Slack、Udemy、Twilio、Okta、Imgur、Jobvite、さらにはニューヨークの裁判所システムのWebサイトなど、AWSのお客様に一連の問題を引き起こしました。
障害そのものは比較的短時間で済みましたが、その影響は非常に大きく、一部のAWSユーザは17時間後までこの問題に関連したトラブルを抱えていました。
現実に言うなら、次の障害は「もしも」ではなく、「いつ」「どこで」「どのくらいの期間」起きるのかということになります。
このような問題が存在しない、あるいは起こらないように装うということは、無意味であるだけでなく、ビジネスに悪影響を及ぼします。
此度の3度にわたる12月の障害を振り返ると、以下の4つのポイントが見えてきます。
1. AWSの事態のような障害に対応するには、早期発見が重要
Catchpointは、この3つの障害全てを、AWSのステータスページに表示されるよりもかなり前に観測しました。
- 2021年12月7日の障害
Catchpointでは、AWSサービスヘルスダッシュボードに投稿された米国東部時間の午後12時37分の発表よりもかなり早く、午前10時33分からAWSサーバの接続問題を確認しました。

- 2021年12月15日の障害
Catchpointは、米国東部時間午前10時15分頃、またAWSの発表前である午前10時43分頃に再び障害を確認しました。
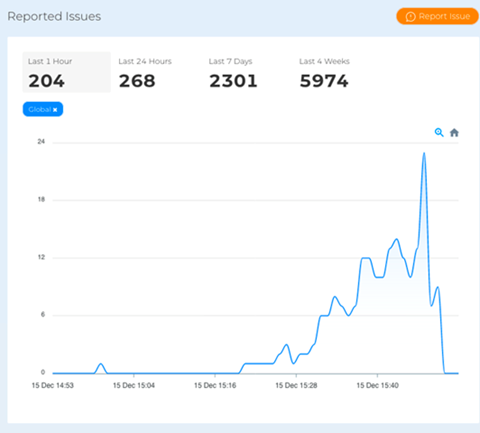
- 2021年12月21日の障害
Catchpointが問題を最初に観測したのは、AWSの発表より24分前の米国東部時間午前7時11分でした。
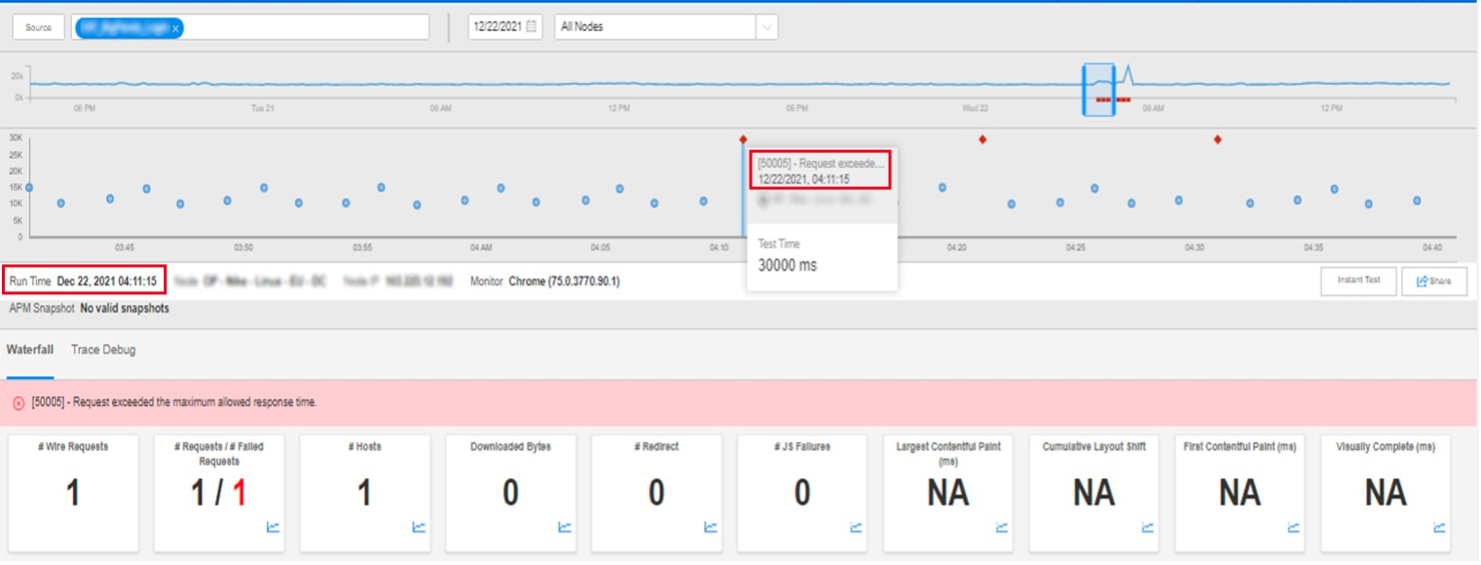
早期発見により、企業はお客様に影響を与える前に潜在的な問題を解決し、潤滑なフェイルオーバーを確保するため、不慮の事態に対する解決策を早急に実施することができます。
また、問題が継続している場合は、お客様に状況を正確に伝え、チームが解決に向けて取り組んでいることを積極的にアピールすることができます。
2. 包括的なオブザーバビリティにより、障害発生時の迅速な対応が可能に
AWSの監視はAWSに任せたいと思うかもしれませんが、それでは観測性の面で不安が残ります。
包括的なデジタルオブザーバビリティ計画には、自社の技術的要素だけでなく、自社ではコントロールできないサービス配信チェーンのコンポーネントも含める必要があります。
例えば、コンテンツ・デリバリー・ネットワーク(CDN)やマネージドDNSプロバイダ、バックボーンとなるインターネットサービスプロバイダ(ISP)などのサードパーティベンダーのシステムを把握する必要があります。
これらは自社のコードやハードウェアではないかもしれませんが、ユーザが経験する問題によって影響を受け、それがビジネスにも影響を与えます。
エンド・ツー・エンドの体験を観察していれば、自分ではコントロールできないことがユーザに影響を与えているときに行動することができます。
また、DNS、BGP、TCPコンフィグレーション、SSL、データが通過するネットワークなどの基本的なコンポーネントの障害を検出するために、システムを継続的に観察することも意味しています。
また、ほとんど変更することのないインフラの単一障害点を検出することも同様です。
この問題は、クラウドによって基盤となるネットワークの多くが開発、運用、ネットワークチームから抽象化されているという事実により、さらに悪化しています。
そのため、問題を発見するのが難しくなります。
そのため、これらの基本的な部品に不具合が発生すると、私たちは驚くことになります。
もしチームが適切な準備をしていなければ、検出、確認、また根本原因を見つけるために無駄な時間がかかり、コストもかかります。
そのため、システムのこれらの側面を継続的に監視し、障害が発生した場合の対処法についてチームを訓練しておく必要があります。
3. 企業の可用性と事業継続性の確保は個人の努力では成り立たない
AWSの事件はいずれも、ある企業の障害が他の企業に与える影響を明確に示しています。
デジタルインフラは今後もますます複雑化し、相互接続されていくことでしょう。
今日の企業は、複数のクラウドにまたがってシステムを運用しています。
また複数のチームに依存しており、その中にはクラウドコンピュート、CDN、マネージドDNSなどの他のベンダーも多数含まれています。
パートナーやサードパーティ・プロバイダなどの外部組織に起因する問題が自社のシステムをダウンさせる可能性がある場合、拡張されたデジタル・インフラをサポートするために設計されたコラボレーション戦略を構築する必要があります。
そのためには、コンテンツの配信に関わる全てのサービスプロバイダを包括的に観測できることが重要です。
4. 監視対象となる環境に設置された監視ソリューションだけでは不十分
世の中には多くの監視ソリューションがありますが、監視対象となる環境以外のソリューションにフェイルオーバーできる「ブレイクグラスシステム」があるかどうかを確認してください。
多くの可視化ソリューションはクラウド上に設置されているため、クラウド技術がダウンした場合には脆弱になります。
このため、ThousandEyes、Datadog、Splunk (SignalFX)、およびNewRelicは、12月7日および12月15日の障害による影響を報告しています。
始めの障害では、Datadogが複数の製品に影響を与える遅延を報告し、Splunk(SignalFX)がAWSクラウドのメトリックシンカーのデータ取り込みに影響を与えたことを報告し、NewRelicは米国でAWSインストラクチャーとポーリングのメトリックの一部が遅延したことを報告しました。
また、12月15日の障害がきっかけとなって、いくつかの問題が発生しました。
- DatadogはAWSの統合メトリクスの収集に遅延があると報告
- ThousandEyesはAPIサービスの低下を報告
- NewRelicはsyntheticのユーザインターフェースに影響があったほか、APMのアラートの一部やインフラストラクチャメトリクスのデータ取り込みにも影響があったと報告
- Dynatrace社はAWSクラスターにホストされている同社のコンポーネントの一部が影響を受けたと報告
- Splunk(RigorおよびSignalFX)は米国西海岸でのエラー発生率の上昇と同社のログ・オブザーバーのパフォーマンスの低下を報告
オブザーバビリティの欠如は決して良いことではありませんが、停止期間中はそれが著しく悪化します。
興味深いことに、AWSのエイドリアン・コッククロフト氏がMediumへの投稿でこの問題を指摘しています。
まず役に立つのは、監視しているインフラとは無関係の故障モードを持つ監視システムです。