
ギャップを埋める: ネットワークとアプリケーション監視の統合による完全な可視化
著者: Wasil Banday
翻訳: 竹洞 陽一郎
この記事は米Catchpoint Systems社のブログ記事「Bridging the gap: Integrating network and application monitoring for complete visibility」の翻訳です。
Spelldataは、Catchpointの日本代理店です。
この記事は、Catchpoint Systemsの許可を得て、翻訳しています。
技術が進歩しアプリケーションがますます絡み合う中、従来のネットワークを個別に監視する方法ではもはや不十分です。
ネットワークとアプリケーションのチームはしばしば別々のツールを使用し、異なる目標に焦点を当てて、サイロの中で作業しています。
この分割されたアプローチは、両方の側が問題を部分的にしか理解できないことが多く、両方の領域にまたがる問題を特定して修正するのが難しくなります。
ネットワークとアプリケーションの監視を統合することは、迅速な問題解決と大幅なパフォーマンス向上を達成するために重要です。
以下の顧客ケーススタディで、両方の分野を組み合わせることによってどのように以下が達成されたかをご覧ください。
- MTTRの迅速化
- アプリケーションの読み込み時間の2倍の改善
- 最初のバイト時間(TTFB)の3倍の改善
ケーススタディ: ネットワークとアプリケーション監視の統合
あるクライアントとの概念実証の取り組み中、技術運用チームはオフィス内の一部のユーザにとってアプリが非常に遅いという緊急のメールを受け取りました。
チームが最初に行ったのはネットワークの確認でしたが、これは誰もネットワークに関して明示的に苦情を言っていないにもかかわらずです。
誰も「アプリが遅いのはネットワークのせいだ」とは言っていませんでした。
この即座の仮定は典型的な考え方を示しています。
何かが遅い場合、それはネットワークのせいに違いないというものです。
ネットワークは常に最初に責められるものです!
チームはネットワークとルーターの精査を始めましたが、元々の問題はアプリ自体が遅いというものでした。
AWSにホストされ、CDNを使用するSaaSアプリケーションです。
そこでCatchpointは、当社のインターネットパフォーマンス監視(IPM)プラットフォームの全機能を活用して、より詳しく調査することにしました。
問題の遅いSaaSアプリケーションをオンボードし、地域内のバックボーンロケーションを含む様々な視点からアプリケーションのパフォーマンスに関する貴重な洞察を収集し始めました。
チェックを実行して数分以内に、遅延がクライアントの内部ネットワークに特有のものではなく、アプリケーションに外部からアクセスするユーザに影響を与えるグローバルな問題であることが明らかになりました。
この重要な情報を基に、ネットワークからアプリケーション自体に焦点を移しました。
アプリケーションのパフォーマンスを監視し続ける中で、以下の2つの主要な問題を特定しました。
- 巨大なJavaScriptファイル
- CDNキャッシュの誤設定
これらの問題は、特に効果的にキャッシュされていない静的オブジェクトの読み込みにおいて、アプリケーションの遅延を引き起こしていました。
その後、SaaSベンダーに連絡し、問題を修正するための実用的な洞察を提供しました。
ベンダーは数時間以内に必要な変更を行い、その効果は即座に現れました。
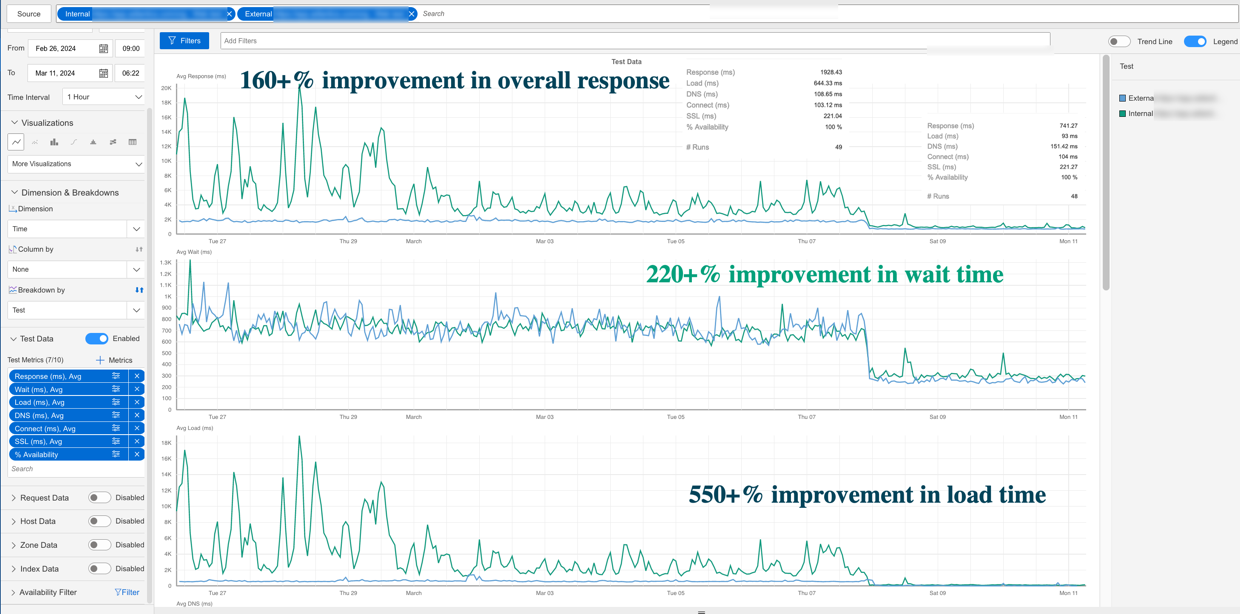
アプリケーションの読み込み時間は約30秒以上から約15秒に急減しました。
さらに印象的なのは、最初のバイト時間(TTFB)の劇的な改善で、1.535秒から0.568秒へとほぼ3倍の改善が見られました。
ユーザと技術運用チームの両方の安堵のために、さらに改善に向けて取り組んでいます。

この経験は、監視とトラブルシューティングにおいて包括的なアプローチを取ることの重要性を強調しています。
ネットワークとアプリケーションのパフォーマンス監視を組み合わせることで、私たちは迅速に核心問題を特定し、解決することができ、大幅なパフォーマンス向上を達成しました。
主な推奨事項
- 1. サイロを終わらせる
-
今日の技術環境でネットワークとアプリケーションの監視を分けておくのは意味がありません。
ほとんどのネットワーク問題は実際にはネットワーク自体の問題ではありません。
約80%のネットワーク障害は人的ミスによるものであり、ハードウェアや環境の問題はそれほど一般的ではありません。
これらのサイロを壊すことで、ネットワークやアプリだけでなく、CDNからDNSの問題に至るまで、インターネット・スタック全体を見渡すことができます。
この統合アプローチは、問題を迅速に検出し解決するのに役立ちます。 - 2. 責任の共有
-
チームワークが重要です。
ネットワークとアプリケーションのチームが協力することで、責任の押し付け合いを止めることができます。
アプリの読み込みが遅い場合やネットワークの不具合など、各問題は皆で対処すべきものとなります。
この協力は問題解決の速度を上げるだけでなく、アプリケーションのトップレベルのパフォーマンスから詳細なネットワークメトリクスまで、全体像を理解するのにも役立ちます。
この共有された視点は「あなたの問題」を「私たちの課題」に変え、ワークフローと職場の雰囲気を向上させます。 - 3. チーム間でデータにアクセスし相関させる
-
ネットワークとアプリケーションのチームがデータにアクセスし相関させることができる監視プラットフォームを使用することで、両者の領域間のギャップを埋めることができます。
チームメンバーがお互いの専門分野を完全に理解していない場合でも、データを相関して見ることでサイロが壊れ、責任の押し付け合いが減ります。
互いに責めるのではなく、すべてのチームが特定のデータトレンドを共同で分析し、協力して問題を解決することができます。
統合監視戦略への移行
組織がユーザに優れたデジタル体験を提供しようと努力する中で、ネットワーク監視とアプリケーションデリバリの間の障壁を打破することが重要です。
一部の企業は、すべてを行う魔法のツールを持つことが最善だと説いていますが、実際にそのようなツールが存在するでしょうか?
例えば、フローデータはネットワークエンジニアにとって非常に有用ですが、これをIPMと組み合わせることで、ベストオブブリードのソリューションになります。
フローデータはセキュリティ映像のようなもので、リアルタイムの活動をキャプチャし、誰がいつ何にアクセスしているかを示します。
これはリアルタイムのユーザインタラクションを把握し、問題が発生した時に特定するために非常に価値があります。
しかし、このアプローチは反応的であり、事件が発生した後に何が悪かったのかを理解するためにセキュリティ映像を確認するのに似ています。
一方、Catchpointのような合成監視ツールは、セキュリティガードのように定期的にチェックを行い、問題を積極的に探します。
5分ごとに部屋をチェックするガードを想像してください。
盗難を記録するカメラに頼るよりも、盗難を防ぐ可能性が高くなります。
CatchpointのIPMはインターネットスタック全体を継続的に監視し、問題がどこにあるのか正確に特定し、ユーザに影響を与える前に修正することができます。
さらに、このすべてのデータはAPI経由で利用可能ですので、Catchpointポータルをメインの監視ツールとして使用する必要はありません。
他の好みのツールがあれば、APIを通じてデータを統合し、その効果を高めることができます。
「一つの」魔法の監視ツールは存在しないかもしれませんが、Catchpointはどのツールも強化し、はるかに効果的にすることができます。
これは統合監視戦略の強みです。
サイロを打破し、両方の世界の最高を組み合わせます。
このアプローチは問題のMTTRを短縮するだけでなく、協力とチームワークの文化を育みます。
戦争部屋や対立がなくなり、エンジニアは最適なデジタル体験の提供に集中でき、顧客と従業員の満足度が向上します。
Catchpoint IPMについてもっと知りたい方は、Spelldataにお問い合わせください。