
エージェンティックAI:強力だが脆弱——知っておくべきこと
著者:
Howard Beader
翻訳: 逆井 晶子
この記事は米Catchpoint Systems社のブログ記事「Agentic AI: Powerful But Fragile—What You Need to Know」の翻訳です。
Spelldataは、Catchpointの日本代理店です。
この記事は、Catchpoint Systemsの許可を得て、翻訳しています。
AIについての理解が深まる中で、次に注目すべきは「自律型のAI」、すなわち「エージェンティックAI」です。
これは、支援するだけでなく、意思決定やタスク処理、他システムとの通信まで自律的に行うAIと考えてください。
この技術はサプライチェーンやお客様体験を一変させていますが、落とし穴もあります。
これらの自律型エージェントは多数の外部サービスに依存しており、その1つでも障害が起きると、全体が停止してしまうのです。
あるeコマース企業を対象とした調査では、回答者の88%が、インターネットの障害によって1か月あたり10万ドル以上の損失を出したと報告しています。
エージェンティックAIの普及とともに、依存先の数も増加し、ダウンタイムのリスクはますます高まります。
AIが停止すれば、業務は止まり、収益は下がり、評判にも傷がつきます。
このようなリスクを抑えながら、エージェンティックAIの価値を最大限に引き出すには、どのような仕組みが求められるのでしょうか?
答えはシンプルです——「可視性」です。
舞台裏で何が起きているかを把握することが、なぜ重要なのかを解説します。
自ら考え動くAIの可能性
従来のAIは、人間の判断を前提とする補助的な存在でした。
エージェンティックAIはさらに一歩進み、こうした自律型エージェントがタスクを処理し、意思決定を行い、外部システムと自律的にやり取りします。
サプライチェーンの自動化から、お客様サービスのパーソナライズまで、その可能性は非常に大きいです。
しかし、ここにも落とし穴があります。
これらのエージェントは、外部サービスのネットワークに依存しており、たとえ小さな障害でもすべてを停止させる可能性があります。
一つのリンクが切れると、その影響は即座に、そして広範囲に及びます。
エージェンティックAIの落とし穴:見えにくいリスクと複雑な依存関係
最近のAI障害は、技術同士が複雑に結びつくほどに、全体の脆弱性が増すことを明らかにしています。
エージェンティックAIのエージェントは、複数の外部サービスからデータを取得しますが、それぞれが新たな障害点となります。
何か問題が発生したとき、原因の特定は簡単ではなく、エンドツーエンドの可視性が必要ですが、多くの監視ツールはそれを提供できません。
可視性がなければ、すべてが停止する中で、問題を特定しようとしても暗中模索となってしまいます。
チームが行き詰まる典型的な場面は下記の通りです。
- AI駆動のサービスが失敗または低速であることは分かっている
- 問題が自社内部にあるのか、AI提供者側なのか、それともネットワーク経路にあるのかが分からない
たとえば、金融サービス企業が、取引や投資に関するお客様の問い合わせに対応するため、AIエージェントに依存しているケースを考えてみてください。
これらのエージェントは、下図に示すように、いくつもの重要なコンポーネントに依存しています。
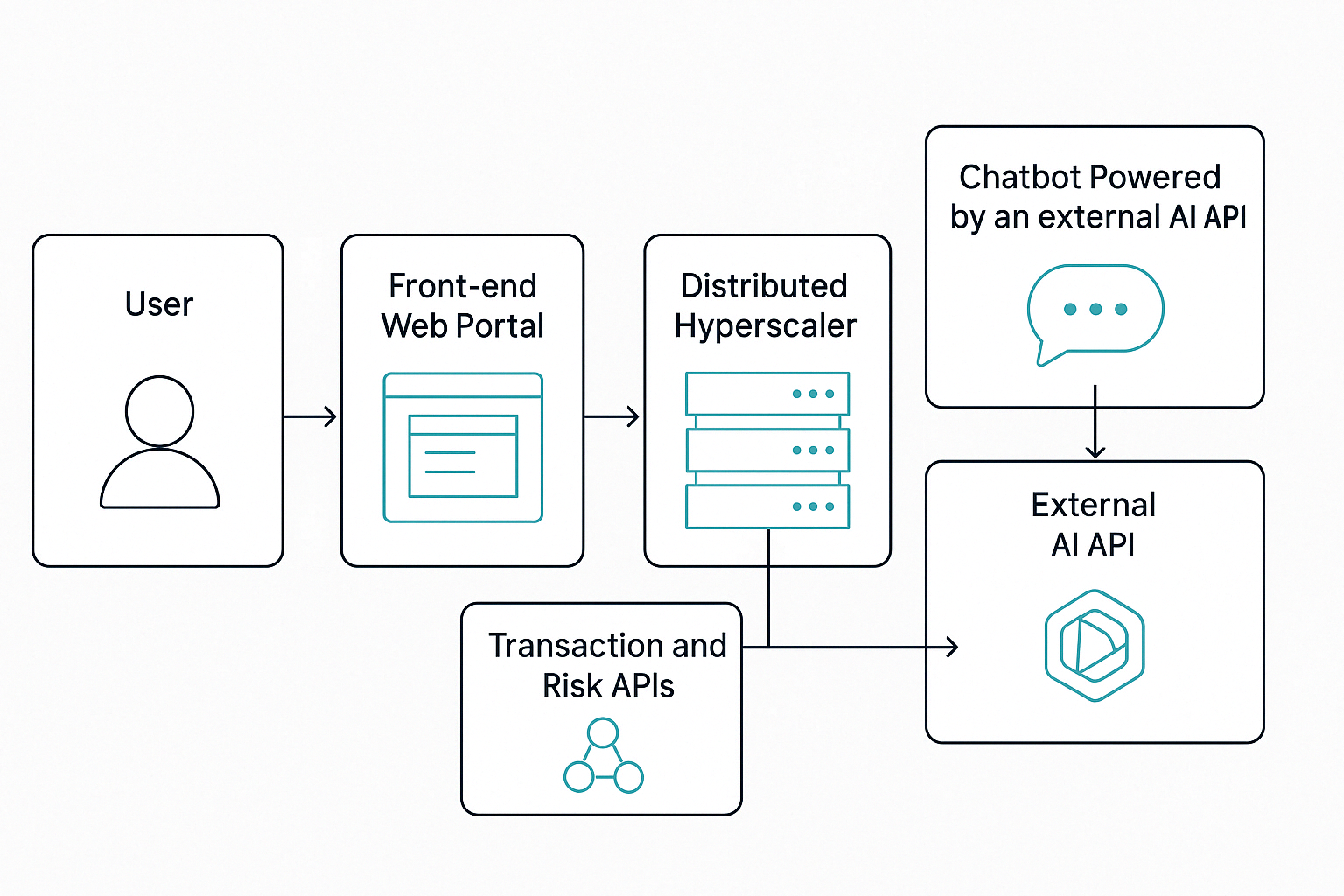
あるエージェントが外部サービスからデータを取得しようとすると、それによって一連のイベントが発生します。
エージェントとシステム間のあらゆるアクションが、全体の複雑性を増加させます。
こうしたサービスの一つでも障害が起きれば、プロセス全体が停止し、クライアントへのサポートが提供できなくなります。
金融業界のように信頼が最優先される分野では、わずかな信用の揺らぎが、クライアント離れや競合流出につながりかねません。
だからこそ「可視性」が重要なのです。
障害がどこで発生したのかを特定できなければ(自社のインフラストラクチャか、AI提供者か、ネットワーク経路か)、すぐに修正することはできません。
そして金融業界のように、1分間のダウンタイムが収益の損失や重大な評判リスクに直結する業界では、それが命取りとなります。
エージェントの依存関係を統合的に把握できなければ、復旧には時間とコストがかかります。
その結果、非効率な「ウォールーム」対応が必要となり、社内外の両方で不満が高まります。
止まらないエージェンティックAIへ:可視化と復旧力を高める実践ステップ
エージェンティックAIシステムを障害から守るには、先手を打てる監視体制を備えることが不可欠です。
AIが依存する外部サービスを正確に把握し、システム全体の中で、障害が起こり得るポイントを把握しておくことが重要です。
こうした可視性が欠けていると、チームは根本原因の特定に手間取り、復旧が遅れてしまい、クライアントへの影響も避けられません。
以下に、そのための手順と実行方法を示します。
- 1. AIの依存関係をマッピングする
-
まず、AIエージェントが依存するすべての要素をマッピングすることから始めます。
理想的には、すべてのマイクロサービス、API、CDN(content delivery network)、DNSルートを、シンプルでインタラクティブなリアルタイムマップで視覚化します。
これにより、AIが依存するエコシステム全体をライブで確認でき、パフォーマンスに影響を及ぼす問題を即座に特定できます。
外部サービスの全体像を把握することで、問題の診断が迅速になり、平均特定時間および平均復旧時間の改善が見込めます。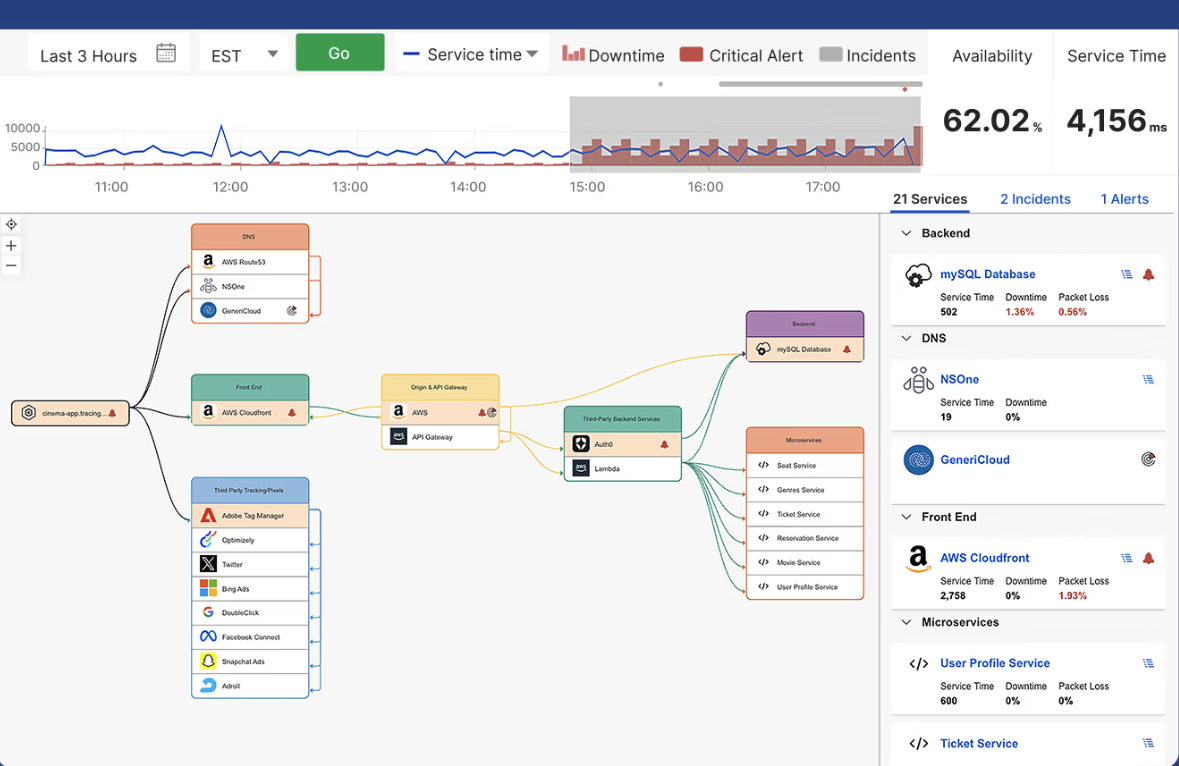
CatchpointのInternet Stack Map - 2. 継続的に監視する
-
AIシステムの安定運用には、継続的かつリアルタイムなインターネット性能の監視が不可欠です。
ユーザージャーニーを模擬的に再現することで、問題が深刻化する前に異常の兆候を検知できます。
これにより、インターネットスタック全体を監視し、サービス停止のリスクを未然に防ぐことが可能です。
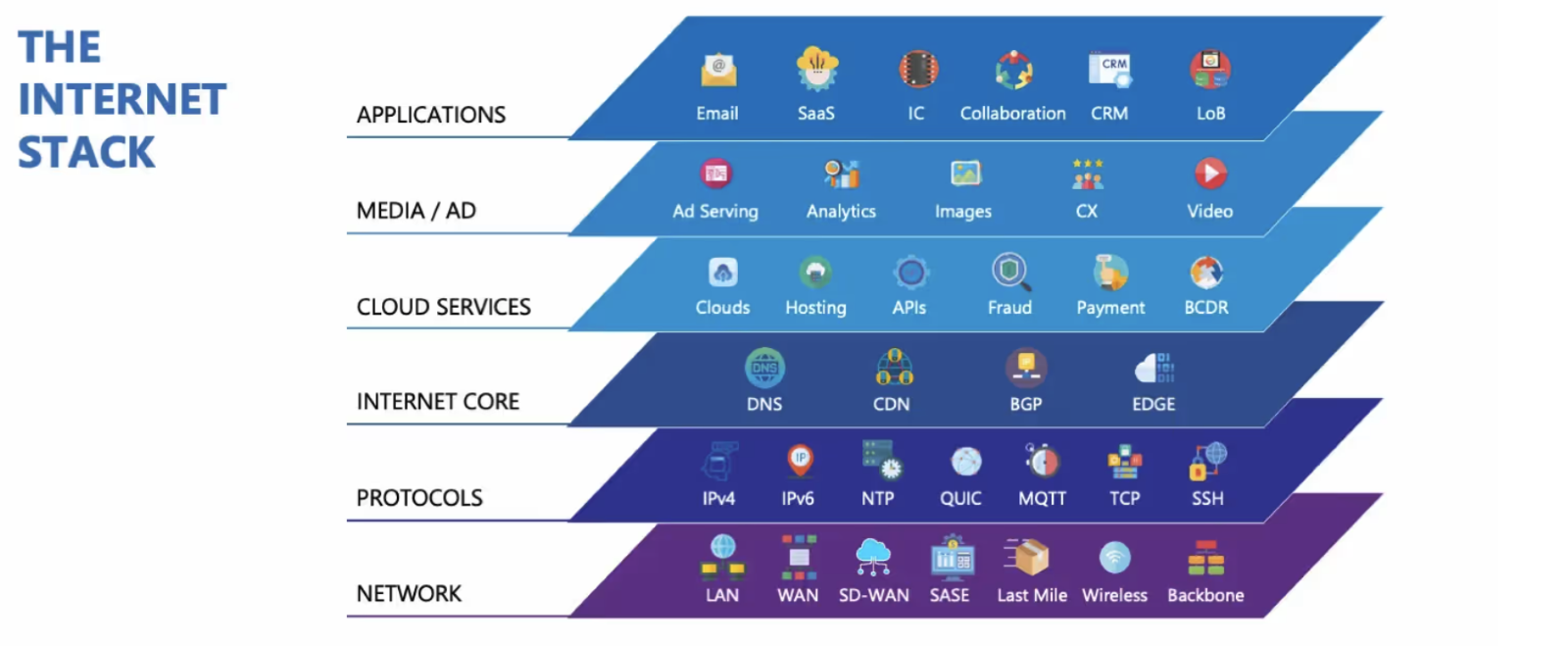
インターネットスタック 障害を先回りで把握することで、サービスの可用性を維持し、ユーザ体験の質を向上させることができます。
- 3. 自動化ツールを活用したエンドツーエンドのワークフローテスト
-
Playwrightなどの自動化ツールを使って、実際のユーザインタラクションを模擬し、ワークフロー全体をテストしましょう。
たとえば、商品のカート追加、チェックアウト、AIエージェントとの対話などのプロセスをスクリプト化します。
こうした動作を再現することで、AIが期待どおりに動作しているかを確認できます。
ユーザ体験に影響を及ぼす前に、摩擦ポイントやパフォーマンスの問題を特定できるため、先手を打って対応可能です。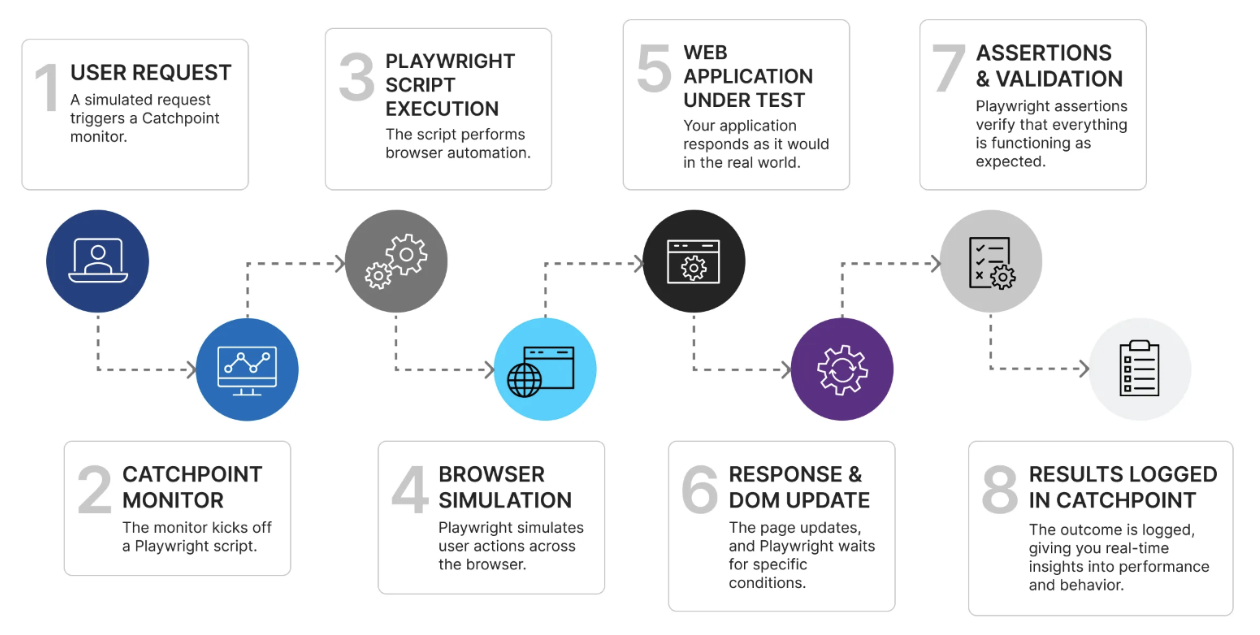
CatchpointにおけるPlaywright自動テストのE2Eワークフロー - 4. フェイルオーバーを計画する
-
重要なAIサービスが停止した場合のバックアッププランはありますか?
障害時の影響を最小限に抑えるには、代替モデルへの切り替えやタスクの一時待機などを含む、明確なフェイルオーバー方針を事前に策定しておくことが重要です。 - 5. パフォーマンスデータを定期的にレビューする
-
障害が起きてから対応するのではなく、定期的にAIの依存関係のパフォーマンスレビューを行いましょう。
レスポンスタイムの微増や、断続的なタイムアウトといった兆候は、潜在的な問題を示すサインです。
これらの機能と実践的な手順を組み合わせることで、エージェンティックAIシステムのレジリエンスを高め、ダウンタイムの最小化が可能になります。
AIワークフローを明確に把握し、継続的な監視体制を整えることで、障害を管理し、サービスを円滑に保つ準備が整います。
次に発生しうるAIの障害にも、事前に備えて対応できるようになります。
エージェンティックAIを守る準備はできていますか?
Internet Stack MapでAI依存関係を可視化し、「本当に重要なもの」の監視を始めましょう。
お打ち合わせのご希望は下記お問い合わせフォームよりご連絡ください。