
IPMが、トップテクノロジーブランドによるOpenAIの障害を危機になる前に発見するのにどのように役立ったか
著者:
Brian Costain
翻訳: 逆井 晶子
この記事は米Catchpoint Systems社のブログ記事「How IPM helped a top tech brand catch an OpenAI outage before it became a crisis」の翻訳です。
Spelldataは、Catchpointの日本代理店です。
この記事は、Catchpoint Systemsの許可を得て、翻訳しています。
現在のデジタルビジネスは、かつてないほど相互に接続されています。
業界調査によると、74%の組織が「APIファースト」のアプローチを採用しており、平均的なアプリケーションは26~50のAPIによって動作しています。
このことはイノベーションを加速させる一方で、新たなリスクももたらします。
外部プロバイダーの障害は、即座に広域にわたる影響を引き起こす可能性があります。
あるグローバル企業は、重要なサードパーティプロバイダーであるOpenAIに不具合が生じたことで、その影響を実際に経験しました。
同社はOpenAIを活用して主要なAI機能を提供していたため、たとえ短時間の中断であっても、プラットフォーム全体でパフォーマンスの問題が連鎖的に発生するリスクを抱えていました。
ここでは、同社がどのようにして問題を早期に察知し、緊急対応会議を回避しつつ、自社のシステムに原因がないことを迅速に突き止めたのかをご紹介します。
障害はどのようにして早期に検出されたのか?
5月31日未明、Catchpointのsyntheticテストが、世界的な消費者向けテクノロジー企業に対して、OpenAIのAPIへのアクセスにおけるタイムアウトおよびパフォーマンスの劣化を警告し始めました。
- 最初の障害観測時刻
- 午前4時30分(PDT)
- 初期影響地域
- ワシントンD.C.およびボストン(マサチューセッツ州)
- 検出された症状
- APIのタイムアウト、不安定なパフォーマンス、テスト失敗の増加
リアルタイムの可観測データを活用することで、チームは即座にOpenAIのプレミアムサポートに対し、サポートチケットを発行しました。
パフォーマンスタイムラインには何がわかるのか?
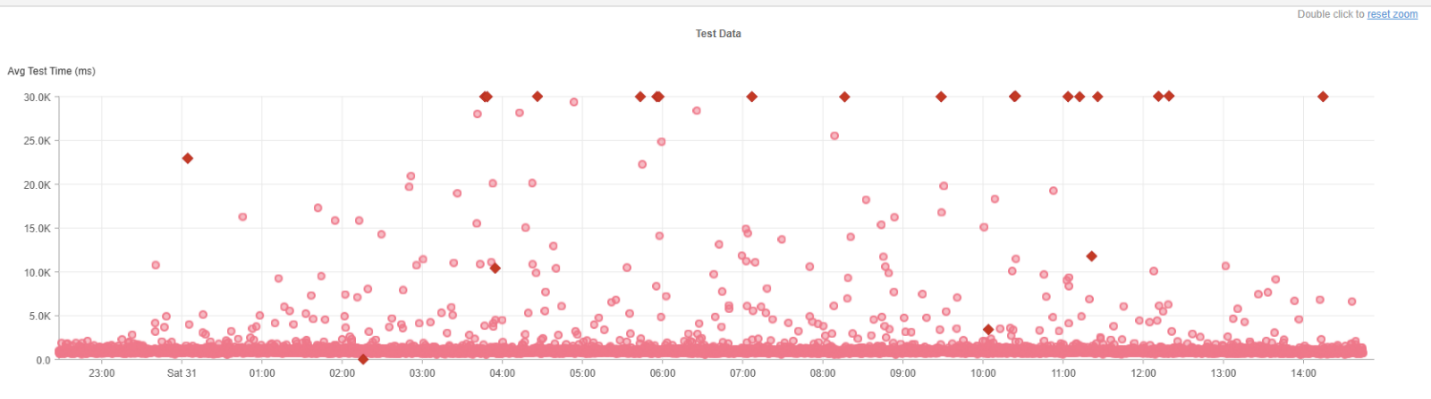
OpenAIのAPIリクエストに要した時間(ミリ秒単位)を可視化した散布図には、5月31日を通じたテスト結果が反映されています。
各点はsyntheticテストの結果を示しており、数値が高くなるほどレイテンシーの増加や応答速度の低下を意味します。
点が密集している部分や外れ値に着目すると、深刻なパフォーマンス低下や断続的な障害が発生していた時間帯が浮かび上がります。
独立したモニタリングがなぜ重要なのか?
OpenAIのスタッフは、チケットを5分以内に確認したものの、パフォーマンス劣化の把握と本格的なトラブルシューティングの開始には40分以上を要しました。
その間、Catchpointは米国内の複数の地域およびプロバイダーにおいて、数時間にわたり断続的な障害を検出し続けていました。
- 継続的な障害観測期間
- 午前4時30分(PDT)~午後2時00分(PDT)
- 影響地域の広がり
- 初期の拠点を超えて米国内の他地域にも拡大
独立したテストは、単なる早期検出にとどまらず、問題の原因が外部にあることを迅速に特定するためにも不可欠でした。
そのおかげで、社内の技術担当者は社内システムの調査に無駄な労力を費やすことなく、サードパーティプロバイダーによる対応のあいだ、状況のモニタリングに専念することができました。
ベンダーのステータスページや社内ログのみに依存していた場合、新たに発生する問題の兆候を見逃していた可能性もあります。
API障害によるビジネスリスクとは?
OpenAIの強力な生成能力は、リアルタイムAPI呼び出しによってパーソナライズされたコンテンツを生成する多くのAI搭載アプリケーションの基盤となっています。
API障害は、突発的なトラフィックスパイク、インフラストラクチャ障害、あるいは不具合のあるコードデプロイなど、さまざまな要因で発生します。
従来のダウンタイムとは異なり、これらの障害は断続的な失敗や地域的な速度低下として現れることが多く、基本的な稼働チェックでは検出が困難です。
サードパーティ依存が機能不全に陥ると、お客様向けの機能が利用不能となり、ユーザ体験と収益に直接的な影響を及ぼします。
Forresterの調査によると、平均的な小売企業は月に72回のインターネット障害を経験しており、調査対象の42%の企業では、直近1か月間で50万ドル以上の損失が発生していました。
年間では600万ドルを超える損失になります。

これらの障害の多くは、サードパーティAPIの障害に起因しており、今やあらゆるデジタル業務の基盤となっています。
Internet Performance Monitoring(IPM)は、複数の場所からアクティブテストを行い、ユーザインタラクションをシミュレーションしつつ、APIの健全性を継続的に監視することで、劣化や障害の初期兆候を効果的に捉えることができます。
今回のケースでは、IPMプラットフォームがお客様に安心を提供し、OpenAIの対応中も状況を綿密にモニタリングしながら、不要な緊急会議を回避することができました。
サービスは完全に復旧し、AIによる創造活動が再開
サービスの復旧によって、ユーザはペットや自分をジブリの世界に描き出す楽しいひとときを、再び安心して楽しめるようになりました。

早期検出と継続的モニタリングのおかげで、週末の危機となり得た事象は、ほんの短時間の中断にとどまりました。
デジタル企業にとってIPMが重要である理由
今回のOpenAIの障害のような事例は、IPMが今やデジタル企業にとってミッションクリティカルである理由を浮き彫りにしています。
現代のプラットフォームが複雑なサードパーティAPIのネットワークに依存している中で、リアルタイムかつ分散型のオブザーバビリティは不可欠です。
CatchpointのIPMが実現すること
- APIパフォーマンスの劣化を即座に検出
- 独立した検証によりMTTR(平均復旧時間)を短縮
- サードパーティの障害によるビジネスへの影響を軽減
- 世界中のユーザ拠点にわたるエンドツーエンドのオブザーバビリティ
これらの機能により、組織は迅速に対応し、混乱を最小限に抑え、信頼を維持することが可能になります。
それは、複雑で複数のプロバイダーが関わるインシデントに直面している場合でも同様です。
APIのオブザーバビリティの今後は?
今後、オブザーバビリティの未来はモニタリングソリューションにさらに多くのことを求めるようになります。
従来のメトリクスにとどまらない高度なツールを採用する必要があります。
それには、AI駆動の異常検出、自動修復、アプリケーション層とネットワーク層の統一的な可視性の統合が含まれます。
これは、ユーザの期待の高まりに対応し、APIやサードパーティサービスへの依存増加によって生じる運用およびビジネスリスクを効果的に管理するために不可欠です。
より深く知るには
APIモニタリングのベストプラクティスや、サードパーティ依存関係を管理するための戦略についてさらに知りたい方は、以下のリソースをご覧ください。
- ウェビナー:Planet of the APIs – 現場で役立つトランザクションモニタリングの上級セミナー
-
プロアクティブなAPIトランザクションモニタリングが、パフォーマンス、リグレッション、機能テストのユースケースにどう貢献するかを探ります。
本テクニカルセッションでは、実世界のモニタリング手法、高度なAPIテストスクリプトの構築、パフォーマンスデータのツールチェーンへの統合について解説します。 - ブログ:モダンAPIモニタリングに求められる重要要件
- 今日の相互接続されたデジタル環境において、信頼性、レジリエンス、シームレスなユーザ体験を実現するために、APIモニタリングソリューションに必要な基本機能を紹介します。