Cloudflareのリゾルバ障害:DNSだけではない問題
著者: Catchpoint Team
翻訳: 逆井 晶子
この記事は米Catchpoint Systems社のブログ記事「Cloudflare’s Resolver Outage: More Than Just DNS」の翻訳です。
Spelldataは、Catchpointの日本代理店です。
この記事は、Catchpoint Systemsの許可を得て、翻訳しています。
【2025年7月16日更新】
Cloudflareは本インシデントについての詳細なポストモーテム分析をこちらに投稿しました。
要約
Cloudflareの内部システムの設定ミスにより、1.1.1.1のIPプレフィックスが誤って非本番環境のサービストポロジーに関連付けられました。
その後、テスト用ロケーションが追加されたことをきっかけに、これらのプレフィックスがCloudflareの全データセンターから一斉に撤回され、結果として大規模な障害が発生しました。
発生時に検出されたハイジャックは障害の直接的な原因ではなく、ルート撤回によって偶発的に表面化した別の潜在的な問題でした。
Catchpointは、Cloudflareがこのインシデントについて詳細な情報を公開したことを高く評価しています。
このような透明性は、信頼性の向上に寄与するだけでなく、インターネット全体の健全性向上にもつながります。
「原因はいつもDNSだ。」
これはIT業界の定番ジョークです。
Webサイトが読み込まれず、アプリが停止するとき、DNS(インターネットのアドレス帳)がまず疑われます。
これは、DNSがgoogle.comのような人間にとって分かりやすい名前を、コンピュータがトラフィックのルーティングに使用するIPアドレスに変換するためです。
何百万人もの利用者が、Cloudflareの1.1.1.1、Googleの8.8.8.8、Quad9といったパブリックリゾルバを利用しています。
これらは通常、ISPが提供するものよりも高速かつ信頼性が高いためです。
そのため、2025年7月14日に1.1.1.1が停止した際、何百万人もの利用者がインターネットから切り離されました。
Redditでは投稿が殺到し、ISPが非難され、利用者はルータを再起動しましたが、効果はありませんでした。
しかし、今回の原因はDNSではなかったのです ― 少なくとも、直接的には。
障害の概要:1.1.1.1に実際に何が起きたのか?
7月14日17:50(米東部時間)、CatchpointのInternet Sonarは、Cloudflareのパブリックリゾルバ1.1.1.1に対するDNSクエリの失敗が急増したことを検出しました。
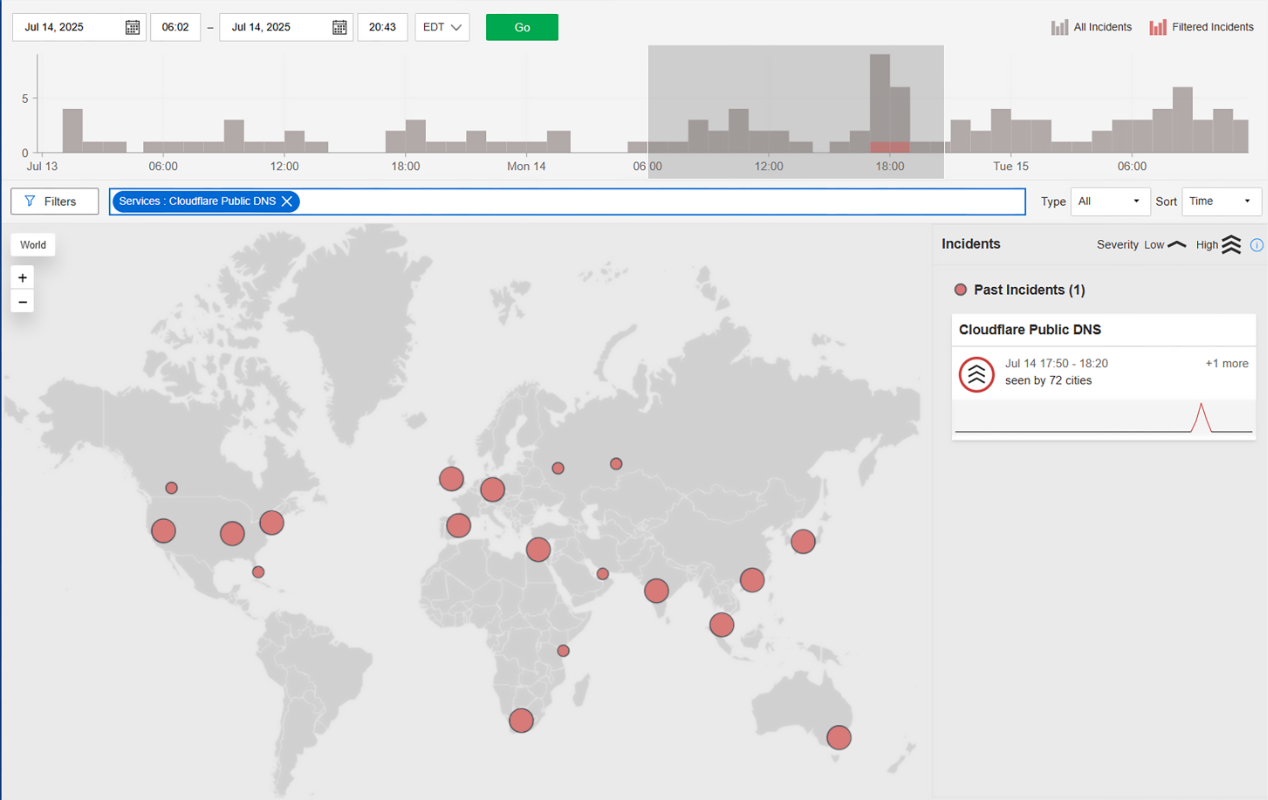
あらゆる観点から見ると、DNS障害のように見えました。
クエリがタイムアウトし、インシデント終盤にはServFailエラーも発生しました。

しかし、根本原因はDNSサーバの故障ではなく、BGPルートハイジャックでした。
BGPハイジャックの説明:Tataが1.1.1.1をネットワークマップから外した方法
背後では、障害はDNSの失敗ではなく、インターネットルートの改竄によって引き起こされていました。
障害発生中、Cloudflareに属する1.1.1.0/24の範囲が大規模に撤回され、その後、Tata Communications India(AS4755)によってハイジャックされたルートがアナウンスされました。
この不正なアナウンスはTataのグローバルバックボーン(AS6453)を通じて伝播し、世界中の多くのネットワークに拡散しました。
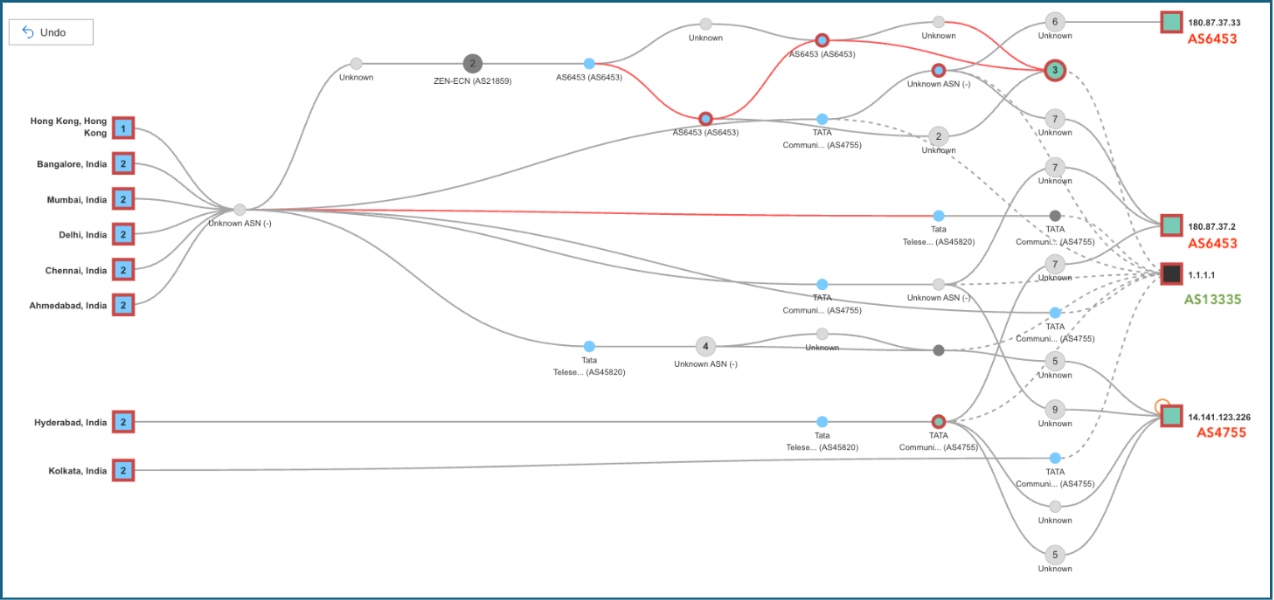
このトレースルートの図は、今回の障害の全体像を明確に示しています。
各経路は自律システム番号(ASN)ごとに分類されており、トラフィックがどの経路を通ったのか、あるいはどの地点で到達に失敗したのかが視覚的に分かります。
Cloudflareの正規のASN(AS13335)に到達しているケースも一部には見られますが、多くの経路ではそこに到達できず、「ルートが存在しない」というエラーで終了していました。
また、別の経路では、不正なASパスを通ってハイジャックされたプレフィックスが伝播している様子も確認されています。
RPKI(Resource Public Key Infrastructure)は不正を検出していたが、インターネットは受け入れてしまった
しかし、AS4755によってアナウンスされたハイジャックルートは、RPKIにおいて明確に「Invalid(無効)」と判定されていました。
Cloudflareは1.1.1.0/24に対する有効なROA(Route Origin Authorization)を持っていました。
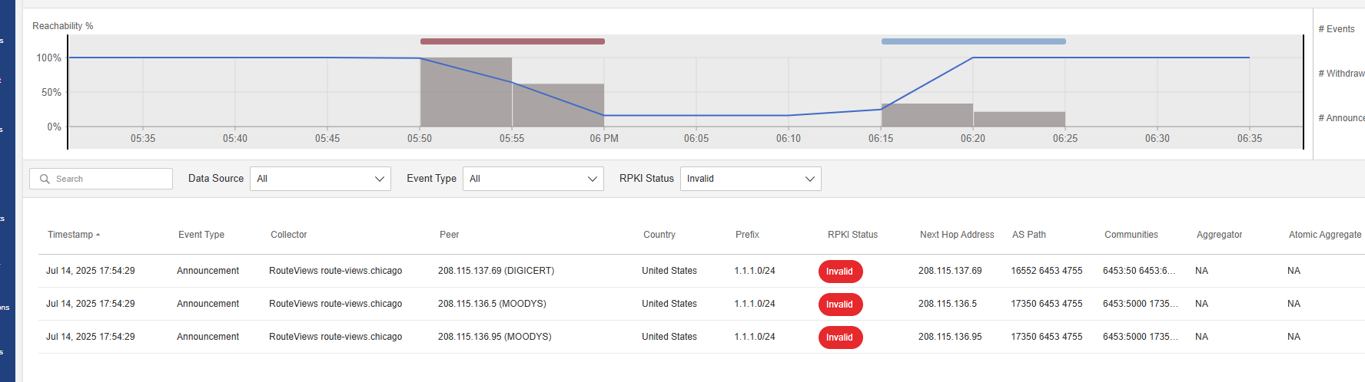
このチャートは、CatchpointのプラットフォームがRouteViewsコレクター経由で米国のピアからキャプチャした多数の無効なアナウンスメントの一例を示しています。
ROAに基づいて無効であるにもかかわらず、これらのアナウンスメントはAS6453を含む主要なネットワークによって受け入れられ、伝播されました。
この期間中、多くのノードがCloudflareのASN(AS13335)による正規ルートを撤回しました。
一部のノードは完全に到達不能となり、その他のノードはAS4755に向かうハイジャックルートを採用してしまいました。
LumenやAT&Tといった一部のISPでは、1.1.1.0/24に関するルート情報がまったく存在しない状況が確認されました。
これは、Tataによる無効なアナウンスメントをRPKIフィルタリングで正しく除外していたためと考えられます。
しかし、Cloudflareの正規ルートがなぜこれらのネットワークに届かなかったのかは不明です。
通常であれば、Cloudflareが発信する正規のBGPアナウンスは、それらのネットワークにも到達しているはずです。
リゾルバがが完全に到達不能となる方が良いのか、あるいは不正なネットワークを経由してアクセスできてしまう方が良いのかは意見が分かれるところです。
とはいえ、今回のケースでは多くのネットワークが後者を選び、その結果として、数百万のユーザが影響を受けることとなりました。
興味深いことに、今回はRPKIが期待された役割を果たすには至りませんでした。
Cloudflareは、DNSサービスを提供するプレフィックスを自社AS(AS13335)からのみアナウンスできるよう、正しくROAを設定していました。
また、TataもRPKIベースのフィルタリングを導入していると、Cloudflare自身が「Is BGP safe yet?」というWebサイト上で明言しています。
しかし、Tataは自社グループに属するAS番号からのアナウンスに対して、RPKIフィルタを適用していなかった可能性があり、結果としてハイジャックまたは設定ミスがそのまま外部に伝播してしまいました。
まさに、「絶対に間違いが起こるはずのないところでこそ、何かが間違う」——マーフィーの法則です。
- この問題が引き起こされた理由:世界中のISPによる誤認
- TataのAS4755およびAS6453が1.1.1.1へのより良い経路を保持していると誤って確信しました。
- クエリの誤送信
- 数百万件のDNSクエリが誤ったネットワークにルーティングされました。
- 接続不能状態
- DNSクエリがタイムアウト、もしくは不正なレスポンスを受け取ったため、ユーザはDNSサービスを利用できない状況に陥りました。
実際の影響:エンドユーザにとっての意味
エンドユーザにとって、この影響は即時かつ混乱を招くものでした。
Webサイトが読み込めなくなった
多くのWebサイトやサービス自体は正常に稼働していたにもかかわらず、利用者はそれらに到達できませんでした。
DNS解決ができなければ、ドメイン名をIPアドレスに変換できないため、ブラウザはエラーを表示するか、読み込みを続けるだけになりました。
アプリが動作不能に見えた
ストリーミングサービス、メッセージングアプリ、決済ゲートウェイ、企業向けツールなど、すべてがドメイン解決に依存しています。
DNSが失敗すると、これらのサービスは「ダウンしている」または切断されているように見え、サポートへの問い合わせや利用者からの苦情、社内混乱を引き起こしました。
ローカルでのトラブルシューティングは無意味だった
多くの利用者は自分側の問題だと考え、ルータを再起動したり、Wi-Fiを切り替えたり、ISPに連絡したりしました。
しかし、根本原因は外部にあり、利用者には見えませんでした。
RedditとDownDetectorが賑わったのは「手遅れ」になってから
Cloudflareによる初動の情報開示が行われなかったことから、利用者はソーシャルプラットフォームを通じて状況を把握しようとしました。
その結果、RedditやDownDetectorでは多数の投稿が見られましたが、これらは断片的かつ反応的な情報が中心であり、事象の全体像やタイムライン、推奨される対処内容を示すものではありませんでした。
教訓:この障害が示すインターネットのレジリエンスとは?
CloudflareのDNS障害は、インターネットのルーティングインフラストラクチャが今なおどれほど脆弱であるかを示す教訓です。
ベストプラクティスが守られなかった場合、いかに簡単に混乱が生じるかを浮き彫りにしました。
#1 すべてを監視せよ
ミッションクリティカルなサービスは、DNS、BGP、トランジットネットワークなど外部システムに依存しています。
DNSは単一障害点となりやすく、DNSが機能しない場合、バックエンドが健全であってもサービスは動作しません。
「インターネット全体が落ちているように感じられる」ケースでは、DNS障害が原因であることが少なくありません。
1.1.1.1 のようなパブリックDNSリゾルバは接続性の基盤であり、その停止は他の正常なサービスまでも障害が発生しているかのような印象を与えます。
効果的なモニタリングには、BGPやDNSを含むインターネットスタック全体の可視化が欠かせません。
結果として、利用者は外部事業者の問題ではなく、自身が利用するサービスに不具合があると認識します。
必読:スピードの重要性 ― なぜネットワークのDNSパフォーマンスを改めて注視すべきなのか
#2 ISPはRPKIフィルタリングを強制すべき
1.1.1.1へのアクセスを妨げたルートハイジャックは、RPKI上で無効と判定されるものでした。
それは拒否されるべきでした。
RPKIに基づくオリジン検証により適切にフィルタリングを実装したネットワークでは、利用者は影響を受けませんでした。
たとえ目的地に到達する代替経路が存在しなかったとしても、明らかにハイジャックされたルートを通過すべきではありません。
無効なルートをフィルタリングすることは、もはや任意の対策ではなく、レジリエントなインターネットを成立させるための前提条件です。
#3 早期検知こそが鍵
障害は非常に速い速度で拡大します。
そのため、先手を打つには、Internet Sonar や Internet Stack Map のような AIを活用したプロアクティブなInternet Performance Monitoring(IPM) が不可欠です。
今回のCloudflareの障害では、SonarがCloudflareのステータスページに投稿が行われる23分前に異常を検知していました。
サービス継続性やSLAが問われる状況において、この時間差は非常に大きな意味を持ちます。
#4 RedditやDownDetectorといったソーシャルシグナルに依存しない
これらのプラットフォームが目立って騒がしくなる頃には、すでに影響は顕在化しています。
ソーシャル上の反応は断片的で、必ずしも正確とは限らず、誤解を招くこともあります。
利用者から苦情が出る前に問題を把握するためには、データに基づいた監視ツールを用いるべきです。
関連記事:「クラウドプロバイダは、あらゆることを、あらゆる場所で、一度に伝えているだろうか?」
#5 バックアップDNSリゾルバを必ず設定する
エンドユーザであっても、異なるプロバイダのDNSリゾルバを必ず併用してください。
たとえば、プライマリに Cloudflare(1.1.1.1)を使用している場合は、セカンダリとして Google(8.8.8.8)を設定します。
このようなシンプルな対策であっても、特定のDNSサービスに障害が発生した際に、オンライン状態を維持する助けとなります。
結論
今回のCloudflare 1.1.1.1の障害は、DNSインフラストラクチャ自体の故障ではなく、インターネットのルーティングが信頼関係に依存しているという仕組みの脆さが露呈した結果として発生しました。
1つのネットワークによる設定ミスが原因で、誤ったBGPアナウンスメントが検証されないまま広範囲に拡散され、重要なサービスが何百万人にも利用できない状態となったのです。
この出来事は、インターネットのレジリエンスとは単に「止まらないこと」ではなく、ネットワークスタック全体にわたる可視性・正当性の検証・継続的な監視によって支えられるべきであることを示しています。
あなたがグローバルなネットワークを運用している場合も、単にそれを利用している立場であっても、こうした障害から利用者を守るためには、RPKIの厳格な適用、ネットワークの外側までを含めた監視体制、そして感覚的な対応ではなく、正確な判断に基づく対応が欠かせません。
このインシデントがどのように発生・拡大したのか、今後さらに詳細な分析が求められます。
Cloudflareによる正式なRCA(Root Cause Analysis:根本原因分析)の公開が、コミュニティ全体の学びにつながることが期待されます。
なぜなら、「原因はいつもDNSだ」と思われがちでも、実際にはそうではないこともあるからです。