
ベンダートラップ:次の障害はあなたの責任ではないかもしれませんが、対処するのはあなたです
著者: Payal Chakraborty
翻訳: 逆井 晶子
この記事は米Catchpoint Systems社のブログ記事「The vendor trap: why your next outage won’t be your fault—but will be your problem」の翻訳です。
Spelldataは、Catchpointの日本代理店です。
この記事は、Catchpoint Systemsの許可を得て、翻訳しています。
今日の企業は単一の自己完結型システムで運用されているわけではありません。
クラウドサービス、API、CI/CDツール、DNS、CDN、SASEベンダー、ID管理プロバイダー、クラウドインターコネクト、ISP、SaaSアプリケーション、アプリケーションコンポーネント、マイクロサービスなどが複雑に絡み合う相互依存のネットワークで構成されています。
最近の業界調査では、84%の組織がサードパーティリスクによる運用障害を経験し、そのうち66%が財務的な悪影響を受けたことが分かりました。
これはもはや単なるベンダー契約の問題ではなく、障害が見えない依存関係の連鎖を通じて波及するアーキテクチャにおける運用上の生存の問題です。
SRE(Site Reliability Engineering)やCIOにとっての課題は進化しています。
もはや単にインフラストラクチャを管理するだけではなく、複雑に絡み合ったエコシステム全体を統括する必要があります。
外部の依存関係は、機能を拡張する力となる一方で、重大な障害の原因にもなり得るのです。
ベンダーの管理不備がどのようにしてエンジニアリングの負担を生むのか?
Googleは「トイル(toil)」を以下のように定義しています。
本番サービスの運用に伴う作業のうち、手動で繰り返され、自動化可能で、戦術的なもの。
長期的な価値はなく、サービスの成長とともに直線的に増えていく傾向があります。
外部依存の手動検証、インシデント対応の調整、SLA主張の確認などのベンダー関連タスクは、現代の環境において運用トイルに大きく寄与しています。
ベンダー管理不備による隠れた運用コストには、以下が含まれます。
- 各サービス統合ごとに拡大する手動のベンダーパフォーマンス検証
- 依存関係の連鎖を通じて波及するマイクロ障害への受動的なインシデント対応
- 組織間をまたぐ根本原因分析に要する時間
SREチームは、運用タスクに最大で50%の時間を費やしていると報告しており、ベンダー関連のインシデントがその中で増加傾向にあります。
このサイクルを断ち切るには、インターネットスタック全体にわたる可観測性が必要です。
ベンダー関連のトイルがエンジニアリングの効率を妨げていると認識したら、次に取るべきステップは明確です。
公表されたSLAや仕様だけでなく、コスト・性能・説明責任といった客観的に測定できる観点でベンダーを評価しましょう。
サービスを構成する各要素ごとに、最も適したベンダーを見極めることがなぜ重要なのか?
クラウドプロバイダー、安全なリモートアクセスプラットフォーム、リモートオフィス向けのISPなど、どのベンダーを選ぶ場合でも、コストとパフォーマンスを比較するための客観的なデータが必要です。
たとえば、あるCDNプロバイダーは北米で中央値のページ読み込み時間が520ミリ秒で、年間コストが100万ドルですが、別のベンダーは570ミリ秒で75万ドルというケースがあります。
レイテンシの違いはわずかですが、コスト削減効果は大きいのです。
この場合、2つのベンダーを併用したり、インテリジェントなトラフィックステアリングを利用することが考えられます。
SASE(Secure Access Service Edge)ベンダーが、ヨーロッパのユーザーにとって受け入れがたい体験しか提供できない場合があります。
そのような場合には、新たなSASEベンダーの導入や、地域ごとに異なるベンダーを検討する必要があります。
さらに、SLA(Service Level Agreement)が遵守されているか、ユーザー体験がビジネス要件を満たしているかを継続的に監視することが求められます。
Internet Performance Monitoring(IPM)は、ベンダー選定にどのように役立つのか?
IPMは、クラウド、ISP、ネットワークインフラストラクチャなど、インターネットスタック全体にわたって能動的な可視性を提供し、アプリケーションパフォーマンスやユーザー体験に影響を与える問題の診断と解決を支援します。
IPMは、お客様、従業員、APIなど、ユーザーが実際にいる場所からの体験を起点とします。
アプリケーション自体に焦点を当てるApplication Performance Monitoring(APM)とは異なり、IPMはアプリケーションが存在する文脈を理解するために設計されています。
これには内部ネットワーク、クラウドサービス、接続性、ユーザーまでを含みます。
CatchpointのIPMが他と一線を画すのは、世界中のISP、クラウド、バックボーンプロバイダーにまたがる数千の視点からパフォーマンスを測定できる点です。
これにより、地域ごとに最もコスト効率の高いベンダーを特定することができます。
IPMは、ベンダー選定をデータ主導で、かつ責任ある判断に導きます。
- 地域別の実世界データによるレイテンシとコストのトレードオフの定量化
- 入出力経路の検証による非効率なルートや高額な送信コストの特定
- 独立したSLI(Service Level Indicator)データによるSLAの検証とベンダーへの責任付与
- サービス問題やダウンタイムの事前検出と迅速な対応体制の構築
Catchpoint IPMは、オンプレミス、パブリック、ハイブリッド、マルチクラウド環境にまたがってパフォーマンスを測定でき、地域に応じた最もコスト効率の高い選択肢を特定するのに役立ちます。
ベンダー選定から日々の責任ある運用へ移行するには、パフォーマンス保証を実現する仕組みが必要です。
SLAモニタリングによるベンダー責任の明確化
SLAサービスに関する争いは長期化する可能性があり、大きな経済的負担を伴う可能性があります。
さらに、ベンダーとクライアントのどちらに正当性があるかを客観的に判断することが困難な場合があります。
この曖昧さは、取引関係を悪化させるだけでなく、組織に深刻な損失を招く可能性もあります。
IPMによるSLAの検証
- 客観的なSLA検証
- 中立的な第三者データを使用して、サービス提供の実態を検証。
- 効率的なSLAモニタリング
- 可用性およびパフォーマンスのSLIを日次、週次、月次で追跡。
- 顧客クレーム対応
- デジタル体験に関する苦情を、信頼できる第三者のデータで検証または否定。
- 長期データ保持
- 過去のデータを保持し、年ごとのパフォーマンス比較、迅速な争議解決、法的紛争の回避を実現。
- XLOの採用
- ITとビジネスをアプリケーション体験およびサービス提供の背後で連携させるExperience Level Objectives(XLO)を実装。
独立した可観測性を導入することで、法的コストを最小限に抑え、運用の混乱を軽減し、SLAの遵守を確実にすることが可能です。
2024年のSREレポートによれば、SLA違反は広範囲に及び、かつコストの高い問題であることが明らかになっています。
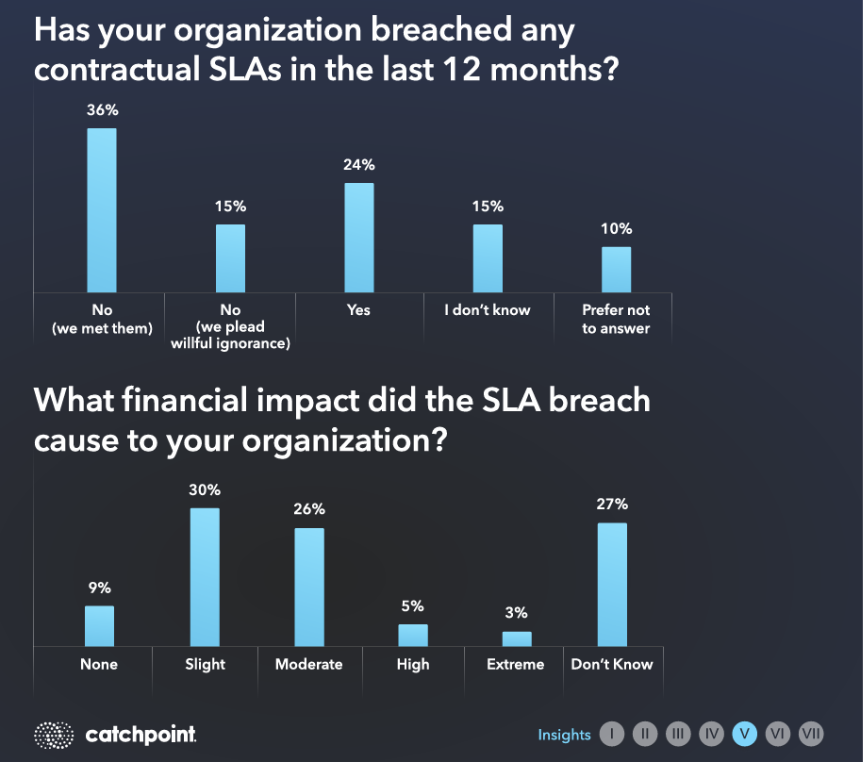
実際、全体の約4分の1の組織が、過去1年間に契約上のSLAを違反したと認めており、さらに15%の組織は違反の有無すら把握していませんでした。
さらに驚くべきことに、回答者の4分の1以上が、こうした違反による金銭的影響を具体的に把握・定量化できていないと答えています。
これは、組織における可視性の重大な欠如を示しています。
独立したモニタリングがなければ、組織はSLA違反の真のビジネスコストを過小評価し、過少報告するリスクがあります。
SLAの履行を複雑にする説明責任の問題は、地域によって大きく異なることがあります。
そのため、グローバル平均を超えて、地域別、さらには都市レベルでのパフォーマンスを検証することが不可欠です。
これこそがユーザーの影響が最も顕著に現れるポイントだからです。
地域によるパフォーマンスのばらつきが重要な理由
グローバルなベンダーの評判が、地域での信頼性を保証するわけではありません。
私たちのパフォーマンスデータは繰り返し、最大手のクラウドプロバイダーでさえ地域ごとにパフォーマンスにばらつきがあることを示しています。
たとえば、以下の例では、2つの主要クラウドプロバイダーのレイテンシをグローバル地域および都市別で比較しています。
全体の平均では見落とされる、地域ごとのパフォーマンス低下が明確になります。
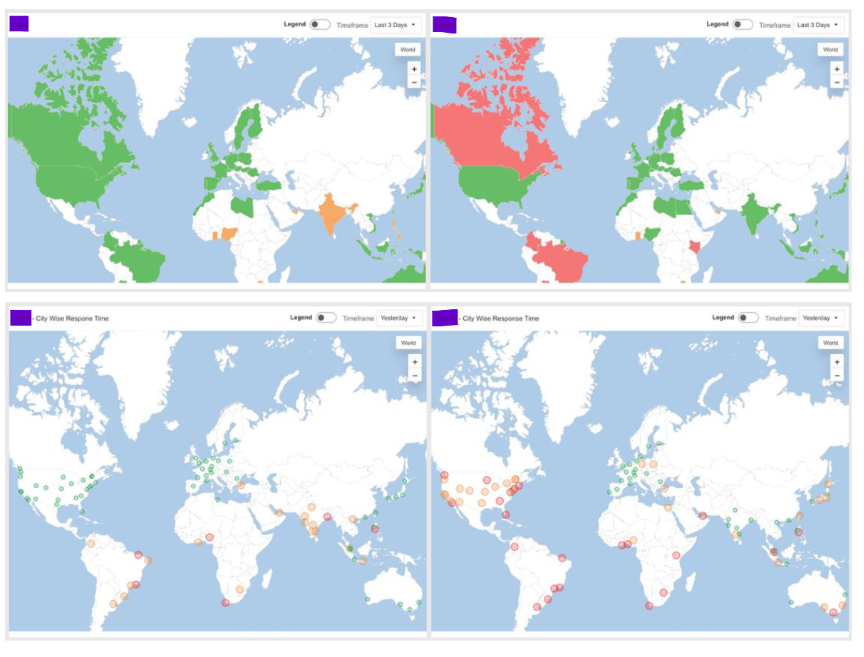
一方のプロバイダーは特定の地域で優れたパフォーマンスを示す一方で、もう一方は弱点を抱えており、両者とも都市レベルでは強みと弱みが混在していることが分かります。
ITチーム向けの重要なポイント
- 1.ベンダーおよび地域によるパフォーマンスの違い
- どのベンダーもすべての地域で常に優れているわけではありません。
- 2.都市レベルの問題を覆い隠すグローバル平均
- ある都市では正常でも、別の都市では障害が発生している可能性があります。
- 3.単一ベンダー依存のリスク
- グローバルレベルでは見えない障害が、ローカルユーザーに被害を与える可能性があります。
- 4.独立モニタリングによる最適な選択
- 地域ごとの可視性が、最適なワークロード配置とSLAの履行管理を支援します。
- クラウドによるユーザー体験監視の限界
- ユーザーはクラウドハイパースケーラーのデータセンターとは異なるリソース、接続性、課題を抱えています。
グローバルに展開しているなら、レピュテーションやSLAの文言だけでベンダーを決めるのはリスクがあります。
マクロレベルでは見えない障害やレイテンシの問題が、特定のユーザーに深刻な影響を与える可能性があります。
FAQ:ベンダー管理のためのIPM
- 複数のベンダーを管理する際に直面する課題は?
- 異なるプロバイダーは、パフォーマンス、信頼性、透明性の点でばらつきがあります。
独立したデータがなければ、それらを公平に比較したり、責任を問うことは困難です。 - Catchpoint IPMは、ベンダーの選定と管理をどのように支援しますか?
- IPMは、クラウドからISP、エンドユーザーに至るまで、インターネットスタック全体のパフォーマンスを測定します。
これにより、ベンダーを客観的に比較し、SLAを検証し、地域に特化した意思決定を実世界のユーザー体験に基づいて行うことが可能になります。 - なぜベンダーのダッシュボードに頼ってはいけないのですか?
- ベンダーが報告するメトリクスは通常、自社の観測点に基づいており、地域ごとの問題を把握しづらくなる可能性があります。
独立したモニタリングは中立性を確保し、お客様や従業員の実際の体験を可視化します。
完全な可視性があれば、ベンダー間で責任の所在を押し付け合うこともなく、ダッシュボードが「すべて正常」を示しているにもかかわらず、ユーザーから苦情が出るといった事態も回避できます。 - IPMはコスト削減にどう役立ちますか?
- プロバイダーや地域ごとのパフォーマンスとコストのトレードオフを比較することで、ユーザー体験に影響を与えずに、わずかに遅いが大幅に安価な選択肢を特定できます。
これにより、より賢明なベンダー支出が可能になります。 - IPMは障害防止にどのように貢献しますか?
- 世界中の数千の観測点により、IPMは地域的な障害を拡大前に検出することができ、影響を軽減し、レジリエンスを維持するのに役立ちます。
ベンダー管理は運用上の必須事項です
今日の複雑なデジタルエコシステムでは、ベンダーが報告するメトリクスのみに頼るのはもはや不十分です。
独立した継続的なモニタリングは、透明性のあるベンダー管理、強靭な運用体制、一貫したデジタル体験の実現に欠かせません。
Catchpointは、ベンダーパフォーマンス、SLA遵守、インシデント対応、地域ごとの信頼性に関する客観的なインサイトを組織に提供し、SREやCIOがよりスマートな意思決定を行えるよう支援します。
さらに詳しく知るには
- Catchpoint IPMによるベンダー選定と管理について詳しく見る。
- お問い合わせフォームより、Catchpointの無料トライアルについてお問い合わせください。