
インターネットパフォーマンス監視(IPM)の紹介:どのように役立つのか?
翻訳: 島田 麻里子
この記事は米Catchpoint Systems社のブログ記事「Introducing Internet Performance Monitoring: How does it help?」の翻訳です。
Spelldataは、Catchpointの日本代理店です。
この記事は、Catchpoint Systemsの許可を得て、翻訳しています。
CatchpointとITOps Timesは、この隔週のマイクロウェビナー・シリーズで、あなたのビジネスにインターネット・レジリエンスを確保するために理解しておくべき6つの重要なトピックを、それぞれ10分以内で解説しています。
シリーズの各トピックはこちら。
- なぜインターネット・レジリエンスにこだわる必要があるのか?
- (本記事)IPMの紹介:どのように役立つのか?
- インターネット・レジリエンスは、eコマース事業者がより多くの収益を上げるためにどのように役立つのか?
- 企業はどのようにしてネットワークとAPIのパフォーマンスを向上させることができるのか?
- 企業はどのようにして従業員のデジタル体験を向上させることができるのか?
- Webサイトのコンバージョンを改善するにはどうすればよいのか?
この第2回では、インターネットパフォーマンス監視(IPM)の世界をさらに深く掘り下げます。
IPMを使用することで、インターネット・スタックの問題がビジネスに影響を及ぼす前にプロアクティブに問題を検出し、修正する方法を学びます。
さて、エピソードに入りましょう!
インターネットパフォーマンス監視の紹介:どのように役立つのか?
CatchpointのCMOであるGerardo Dada氏とのライブQ&A動画、もしくは以下の書き起こしをご覧ください。
動画内容の書き起こし
- Dave Rubinstein
-
皆さん、こんにちは。
ITOps Timesマイクロウェビナー・シリーズ、インターネット・レジリエンスの第2回へようこそ。
ITOps Times編集長のDave Rubinsteinです。前回は、インターネット・レジリエンスと、なぜ組織がインターネット・レジリエンスに関心を持つべきかについてお話ししました。
第2回となる今回は、インターネットパフォーマンス監視の概念と、それがレジリエンスの確保にどのように役立つかを紹介します。
今日ご一緒するのはCatchpointのCMOであるGerardo Dadaさんです。 - Gerardo Dada
-
ありがとう、Dave。
ここに来られて光栄です。 - Dave Rubinstein
-
やぁ、こちらこそ。
先週、御社のCEOであるMehdi Daoudi氏にお話を伺いましたが、彼はインターネットの重要性と、それがいかに複雑で壊れやすいものであるかについて語っていました。
そこで今回は、インターネットの混乱を未然に防ぐために、インターネットを可視化することの重要性についてご紹介したいと思っています。 - Gerardo Dada
-
そうですね。
Mehdiは、今やあらゆるビジネス、あらゆるやりとりがインターネットに依存していると話していましたね。私には10代の娘がいますが、家のインターネットが切断されると、数秒後にはすぐに文句を言われます。
何か対策をしなければなりません。要するに、インターネットは従業員にとっての新しいネットワークであるということです。
最近では、みんながリモートで働いているようで、アプリケーションもますます分散化しています。
私は以前、ネットワークパフォーマンス管理の主要なベンダーの1つで働いていましたが、実際のところ、Catchpointのような企業にはもはやネットワークが存在しません。ルーターを置くようなオフィスもないので、ルーターは持っていません。
もちろん、大企業はまだ何年もルーターを持ち続けるのでしょうが。
これは依然として重要な投資です。しかし、インターネットの監視は、多くの企業で行われる必要があるものです。
なぜなら、インシデントの大部分がインターネット上で発生するからです。
そして、AmazonやMicrosoft、Facebookなどの大企業の障害を考える上で重要な点は、これらの企業は監視やネットワーキングなどにおいて非常に深いベンチやスキル、ツールを持っているにも関わらず、障害が発生しているということです。問題は、それが起こるかどうかではなく、いつ起こるか、どれくらい深刻な影響を与えるか、いくらのコストがかかるかということです。
そして本当に最も重要な問題は、それを素早くキャッチし、大問題に発展する前に解決できるかどうかということです。
そのためには、私たちがインターネット・スタックと呼んでいるものに注意を払う必要があります。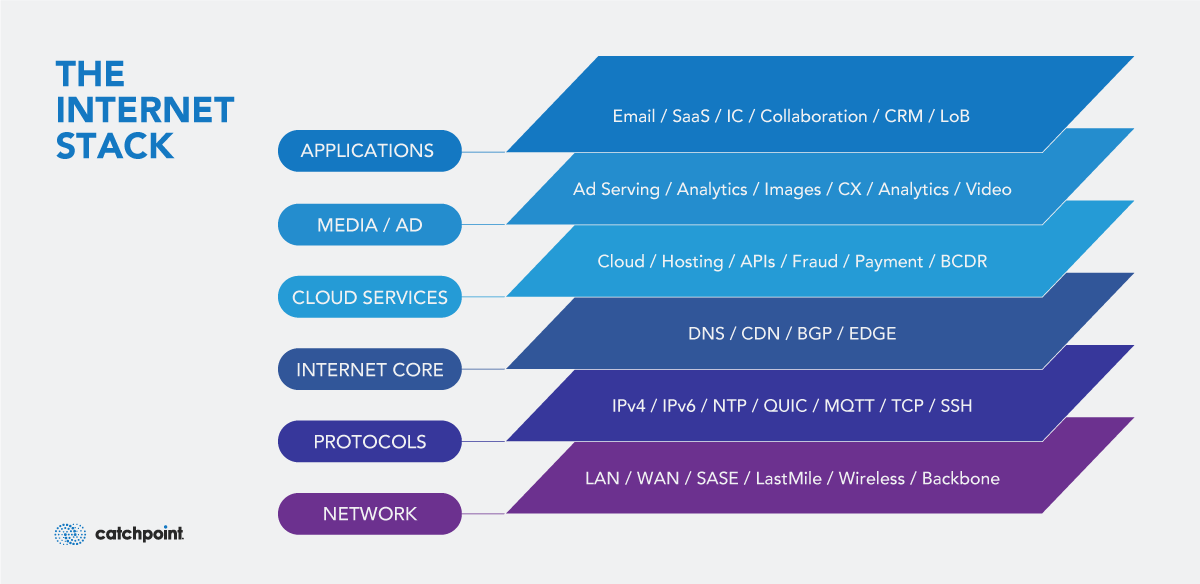
この図は必ずしも100%正確というわけではなく、単にインターネット内部には監視すべき多くの要素があるということを表現しようとしているだけなのです。
それは論理的に整理することもできるし、相互依存関係にあるグループも存在します。クラウドサービスはインターネットのコア・サービスに依存し、一連のネットワーク技術があり、一連のプロトコルがあります。
それらすべてに注意を払う必要があるのです。ネットワーク管理者なら誰でも、DNSが正しく機能しなければ何も機能しないことを知っていますよね?
例えば、ボーダーゲートウェイプロトコル(BGP)のようなものについては、ほとんどの人が知らないと思います。Facebookはこの教訓を、1年以上前にFacebook、WhatsApp、Instagramがダウンした、誰もが知っている大規模障害の際に学んだのです。
同社はBGPに関心を持たなかったがために、何億ドルもの損害を被ったわけです。
彼らは、ルーティング・プロトコルの重要性、監視方法、ルート・リークや変更を検出する方法を理解していなかったのです。こうした一連のテクノロジーすべてに注意を払うためには、企業が従来使ってきたものとは異なる一連のツールが必要です。
ええ、もちろん多くのツールはDNSにちょっとしたコンテキストを持っています。
これらのプロトコルのいくつかは、他のツールで監視できるかもしれない。一部のネットワーク管理ツールは有用であるかもしれませんが、不完全な情報の中での対応を望む人はいません。
再度言いますが、Facebookは何が起こっているのか把握できていなかったのです。私はある大手の金融サービス企業に所属していましたが、彼らは私たちのWebサイトが1時間25分間ダウンしていたと言いました。
1時間以上、私たちはDNSの問題だとは気づかなかった。つい先週のことですが、世界有数のホテル・チェーンがSSL証明書の期限切れを迎えていました。
そのため、数時間の間、ホテルの予約や予約の確認など、(彼らのプラットフォーム上では)何もできなかったのです。このような単純な問題で、企業は失敗しているのです。
彼らは正しいツールを持っていないため、状況を把握するために必要な可視性を確保できず、何か問題が発生した場合には、重大なインシデントになる前に問題を修正するための早期のシグナルを得ることができないのです。私はサウスウエスト航空を見ていましたが、感謝祭の問題の後、彼らは昨日も再び運航を停止したようです。
これは、問題をタイムリーに察知することの重要性を示しています。訳注…2023年4月18日、サウスウエスト航空は技術的問題により全米で一時運航を停止しました。
サウスウエストが5分間運航を停止したとしても、誰にもわからないでしょう。
フライトが5分遅れただけなら、それは良いフライトだと言えるでしょう?
しかし、それが5分から数時間になると、大規模な混乱が生じ始める。 - Dave Rubinstein
-
お聞きしたいのですが、かつては多くの企業がネットワークの監視などを目的としたNOC(ネットワークオペレーションセンター)を運営していましたが、それと比べて今回の状況はどのように異なるのでしょうか?
NOCでは、これらすべてのレイヤーにアクセスすることができたのでしょうか?
それとも、インターネットが発展するに伴い、このような監視が必要になったのでしょうか? - Gerardo Dada
-
そうですね、NOCとは異なるコンセプトだと思います。
なぜなら、GartnerがNPMD(ネットワークパフォーマンス監視および診断)と呼ぶほとんどのネットワーク管理ツールは、SNMPプロトコルを介してデバイスを監視することから始まります。
彼らはトラフィックフローを調査し、ローカルネットワークを監視します。それ以外のことは、彼らのコアコンピテンシーから外れているのです。
同時に、こうした企業の多くはアプリケーション管理ツールを導入しています。
スタックについて話す際、最初に思い浮かぶのは7つのレイヤーだけでなく、サイドレイヤーやネットワーキング、そしてアプリケーションスタックも含まれますね?
そのための特別なツールがあるんです。これはスタックのレイヤーについての考え方の1つに過ぎず、伝統的な3層アーキテクチャやその他の方法、特にマイクロサービスやKubernetesなどの技術が登場した現在では、さまざまな考え方が存在します。
従来のネットワークを見るためのNPMツールがあり、従来のアプリケーション・スタックを見るためのAPMツールがあります。
でも、インターネット・スタックを見るには、別のツールが必要でしょう?
つまり、これがインターネットパフォーマンス監視(IPM)と呼ばれるものです。これらがなぜ重要かというと、BGPを理解するNPMツールを私は知らないからです。
たしかに、パブリック・ネットワークから調達したデータを得ることはできるが、それはリアルタイムのデータではありません。現実の状況や診断に15分遅れることは避けたいし、修正が機能するか確認するためにも15分遅れることは避けたいですよね。
しかし、それにはインターネットインフラの内部に特定のインフラストラクチャが必要です。例えば、Catchpointでは、BGPピアの内部、ASNの内部、無線プロバイダの内部、クラウド・ネットワークの内部にノードを持っています。
実際、クラウド・プロバイダやCDN(大手はすべて)は、Catchpointを使用してネットワークを監視しています。
Cloudflare、Fastly、AWS、Google、Azureについて考えてみると、これらはすべて、サービスが稼働していることを確認し、早期に警告の兆候を得るためにCatchpointを使用しているのです。私たちのノードは、皆さんが考えることができるほとんどすべての国にわたって、世界中のすべてのインフラストラクチャの中にあります。
そのため、他のツールでは得られない可視性を得ることができます。
実際、現在企業がAPMのために使用しているツールの多くは、クラウド上でホストされています。ツールをAmazonAWSでホストしている場合、AWSがダウンすると、ツールを使用できなくなります。
アラートを受け取ることもできない、どんなテクノロジーも使えない。
つまり、それらに依存することになる。私たちは、独立したシステムを持つという意図的な決定を行いました。
そうすることで、これらのサービスがダウンした場合でも、稼働させることができ、コントロールすることができるのです。 - Dave Rubinstein
-
素晴らしいですね。
それでは、そろそろ時間が迫ってきていますが、参加されている皆さんに向けて総括的な考えや、最終的なまとめのポイントがあればお聞かせください。 - Gerardo Dada
-
つまり、最初のアイデアはAPMプラスIPMであり、プラスNPMと言うこともできます。
これは今、あらゆる企業、あらゆるアプリケーションが必要としている新しいテクノロジーです。
企業は、従来のネットワーク・監視、アプリケーション・監視、内部監視の間で、時間、スキル、人材への投資のバランスを取る必要があります。これがインターネットパフォーマンス監視と呼ばれるものなのです。
目的は、ビジネスに影響を及ぼす可能性があるインターネットスタック内の問題を検知することです。
それは、アプリケーションや顧客、従業員、ネットワーク、さらにはWebサイトの体験などに影響を与える可能性があります。
それが私たちCatchpointの仕事です。私たちは唯一の企業ではありませんが、これが私たちの唯一の焦点であり、私たちは一日中IPMについて考え、どのように組織がインターネットスタックの問題を検知するのを支援できるかを考えています。
- Dave Rubinstein
-
わかりました。
Gerardo Dadaさん、今日は本当にありがとう。
心からお礼申し上げます。 - Gerardo Dada
-
ありがとう、Dave。
良い一日を。
あなたのすべてに感謝します。 - Dave Rubinstein
-
ありがとうございました。
5月4日のエピソード3では、インターネット・レジリエンスがeコマース企業の収益拡大にどのように貢献できるかについて、もう少し話を広げていきたいですね。
5月4日ですよ。EST午後1時、ITOpsライブ・マイクロセミナー・シリーズのエピソード3です。参加者の皆さん、ご来場ありがとうございました。
10分間のお時間をいただき、ありがとうございました、それでは次回まで。
ITOps Times編集長のDave Rubinsteinでした。それでは、また。